AI 101
ทฤษฎีเบย์ คืออะไร?
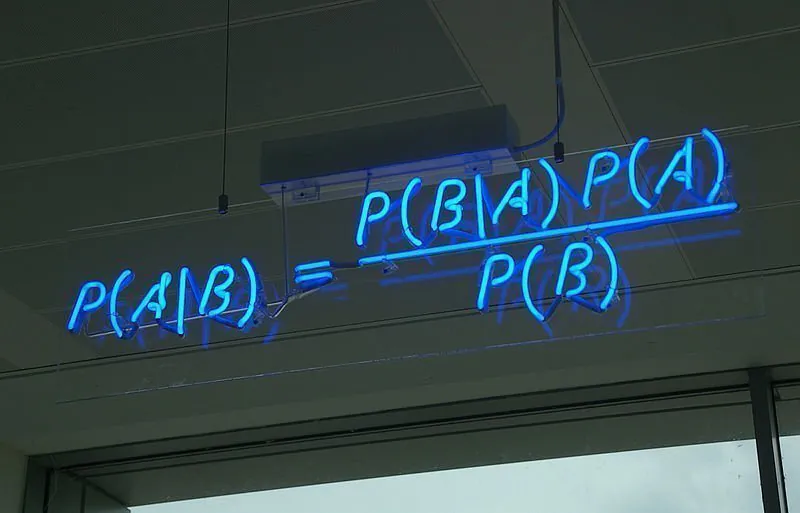
หากคุณได้เรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูลหรือการเรียนรู้ของเครื่องจักร มีโอกาสที่คุณจะได้ยินคำว่า “ทฤษฎีเบย์” มาก่อน หรือ “คลาสสิฟายเออร์แบบเบย์” เหล่านี้สามารถทำให้เข้าใจได้ยากเล็กน้อย โดยเฉพาะถ้าคุณไม่ได้คิดเกี่ยวกับความน่าจะเป็นจากมุมมองของสถิติแบบดั้งเดิม ที่เน้นความถี่ การเขียนบทความนี้จะพยายามอธิบายหลักการเบื้องหลังทฤษฎีเบย์ และวิธีการใช้งานในเครื่องจักรเรียนรู้
ทฤษฎีเบย์ คืออะไร?
ทฤษฎีเบย์เป็นวิธีการหนึ่งในการคำนวณความน่าจะเป็นแบบมีเงื่อนไข วิธีการดั้งเดิมในการคำนวณความน่าจะเป็นแบบมีเงื่อนไข (ความน่าจะเป็นที่เหตุการณ์หนึ่งจะเกิดขึ้นเมื่อเหตุการณ์อื่นเกิดขึ้น) คือการใช้สูตรความน่าจะเป็นแบบมีเงื่อนไข โดยการคำนวณความน่าจะเป็นร่วมของเหตุการณ์ทั้งสองและแบ่งด้วยความน่าจะเป็นของเหตุการณ์ที่สอง อย่างไรก็ตาม ความน่าจะเป็นแบบมีเงื่อนไขสามารถคำนวณได้ในรูปแบบที่แตกต่างเล็กน้อยโดยใช้ทฤษฎีเบย์
เมื่อคำนวณความน่าจะเป็นแบบมีเงื่อนไขโดยใช้ทฤษฎีเบย์ คุณจะใช้ขั้นตอนต่อไปนี้:
- กำหนดความน่าจะเป็นที่เงื่อนไข B เป็นจริง โดยสมมติว่าเงื่อนไข A เป็นจริง
- กำหนดความน่าจะเป็นที่เหตุการณ์ A เป็นจริง
- คูณความน่าจะเป็นทั้งสองเข้าด้วยกัน
- หารด้วยความน่าจะเป็นที่เหตุการณ์ B เกิดขึ้น
ซึ่งหมายความว่าสูตรสำหรับทฤษฎีเบย์สามารถแสดงได้ดังนี้
P(A|B) = P(B|A)*P(A) / P(B)
การคำนวณความน่าจะเป็นแบบมีเงื่อนไขเช่นนี้มีประโยชน์อย่างยิ่งเมื่อความน่าจะเป็นแบบมีเงื่อนไขในทางกลับกันสามารถคำนวณได้ง่าย หรือเมื่อการคำนวณความน่าจะเป็นร่วมเป็นเรื่องที่ท้าทาย
ตัวอย่างทฤษฎีเบย์
อาจจะเข้าใจได้ง่ายขึ้นหากเราพิจารณาตัวอย่างของวิธีการใช้เหตุผลแบบเบย์และทฤษฎีเบย์ ลองสมมติว่าคุณกำลังเล่นเกมง่ายๆ โดยมีผู้เข้าร่วมหลายคนบอกเล่าเรื่องราวให้คุณฟัง และคุณต้องตัดสินว่าใครเป็นคนโกหก ลองเติมสูตรทฤษฎีเบย์ด้วยตัวแปรในสถานการณ์สมมตินี้
เรากำลังพยายามคาดเดาว่าแต่ละคนในเกมนั้นโกหกหรือพูดความจริง ดังนั้น หากมีผู้เล่นสามคนนอกเหนือจากคุณ ตัวแปรแบบคатегорีสามารถแสดงเป็น A1, A2 และ A3 ได้ หลักฐานการโกหกหรือพูดความจริงของพวกเขาเป็นพฤติกรรม เช่น เมื่อเล่นโป๊กเกอร์ คุณจะสังเกต “สัญญาณ” ที่บ่งบอกว่าคนๆ หนึ่งกำลังโกหกและใช้สัญญาณเหล่านั้นเป็นข้อมูลในการเดา หรือถ้าคุณได้รับอนุญาตให้ถามพวกเขามันจะเป็นหลักฐานใดๆ ที่เรื่องราวของพวกเขาไม่สอดคล้องกัน เราสามารถแสดงหลักฐานที่บุคคลนั้นโกหกเป็น B ได้
เพื่อความชัดเจน เรากำลังพยายามคาดเดา Probability(A โกหก/พูดความจริง | หลักฐานพฤติกรรมของพวกเขา) เพื่อทำเช่นนี้ เราต้องการหาความน่าจะเป็นของ B เมื่อ A เป็นจริง หรือความน่าจะเป็นที่พฤติกรรมจะเกิดขึ้นเมื่อบุคคลนั้นโกหกหรือพูดความจริงจริงๆ คุณพยายามตัดสินว่าภายใต้เงื่อนไขใดพฤติกรรมที่คุณเห็นจะทำให้เหตุการณ์มีเหตุผลมากที่สุด หากคุณสังเกตพฤติกรรมสามอย่าง คุณจะทำการคำนวณสำหรับพฤติกรรมแต่ละอย่าง ตัวอย่างเช่น P(B1, B2, B3 * A) คุณจะทำเช่นนี้สำหรับการเกิดขึ้นของ A ทุกครั้ง / สำหรับคนในเกมทุกคนนอกเหนือจากคุณ ซึ่งเป็นส่วนนี้ของสมการข้างต้น:
P(B1, B2, B3,|A) * P|A
สุดท้าย คุณเพียงหารผลลัพธ์ด้วยความน่าจะเป็นของ B
หากเราได้รับหลักฐานใดๆ เกี่ยวกับความน่าจะเป็นจริงในสมการนี้ เราจะสร้างแบบจำลองความน่าจะเป็นใหม่ โดยนำหลักฐานใหม่นั้นมาใช้ นี่เรียกว่าการอัปเดตความน่าจะเป็นก่อนหน้า เนื่องจากคุณอัปเดตสมมติฐานเกี่ยวกับความน่าจะเป็นก่อนหน้าของเหตุการณ์ที่สังเกตได้
การประยุกต์ใช้ทฤษฎีเบย์ในการเรียนรู้ของเครื่องจักร
การใช้ทฤษฎีเบย์ที่พบบ่อยที่สุดในการเรียนรู้ของเครื่องจักรคือในรูปแบบของอัลกอริทึม Naive Bayes
Naive Bayes ใช้สำหรับการจำแนกประเภทของชุดข้อมูลทั้งแบบไบนารีและแบบหลายคลาส Naive Bayes ได้รับชื่อเพราะค่าของพยานหลักฐาน / คุณลักษณะ – Bs ใน P(B1, B2, B3 * A) – ถูกถือว่าเป็นอิสระจากกัน มันถูกถือว่าคุณลักษณะเหล่านี้ไม่ส่งผลกระทบต่อกันเพื่อทำให้แบบจำลองง่ายขึ้นและทำให้การคำนวณเป็นไปได้ แทนที่จะพยายามคำนวณความสัมพันธ์ระหว่างคุณลักษณะแต่ละอย่าง แม้ว่าจะมีแบบจำลองที่เรียบง่าย แต่ Naive Bayes ก็มีประสิทธิภาพในการทำงานเป็นอัลกอริทึมการจำแนกประเภท แม้ว่าสมมติฐานนี้อาจไม่จริงเสมอไป (ซึ่งเป็นกรณีส่วนใหญ่)
มีการใช้ Naive Bayes ที่เป็นที่นิยมอย่างกว้างขวาง เช่น Multinomial Naive Bayes, Bernoulli Naive Bayes และ Gaussian Naive Bayes
Multinomial Naive Bayes มักใช้ในการจำแนกประเภทเอกสาร เนื่องจากมีประสิทธิภาพในการตีความความถี่ของคำในเอกสาร
Bernoulli Naive Bayes ทำงานในลักษณะที่คล้ายกับ Multinomial Naive Bayes แต่การคาดเดาที่ได้รับจากอัลกอริทึมจะเป็นแบบไบนารี ซึ่งหมายความว่าเมื่อคาดเดาประเภท ค่าจะอยู่ในรูปแบบ “ใช่” หรือ “ไม่” ในโดเมนของการจำแนกประเภทข้อความ อัลกอริทึม Bernoulli Naive Bayes จะกำหนดพารามิเตอร์เป็น “ใช่” หรือ “ไม่” ขึ้นอยู่กับว่ามีคำในเอกสารหรือไม่
หากค่าของตัวทำนาย / คุณลักษณะไม่ใช่แบบไม่ต่อเนื่อง แต่เป็นแบบต่อเนื่อง Gaussian Naive Bayes สามารถใช้ได้ มันถูกถือว่าค่าของคุณลักษณะต่อเนื่องเหล่านั้นถูกสุ่มจากการกระจายตัวแบบกอสเซียน












