Andersonの視点
なぜアドバーサリアル画像攻撃は軽視できないのか
画像認識システムを慎重に作成されたアドバーサリアル画像で攻撃することは、過去5年間で面白いが軽微な概念実証と見なされてきました。しかし、オーストラリアからの新しい研究によると、商用AIプロジェクトで非常に人気のある画像データセットをカジュアルに使用することは、耐久性のある新しいセキュリティ問題を生み出す可能性があります。
2年間、アデレード大学の学者グループは、AIベースの画像認識システムの将来について非常に重要なことを説明しようとしてきました。
これは、現在(そして将来5~10年以内に商業化・産業化される)画像認識研究のトレンドを考慮すると、修正するのが非常に難しく(そして非常に高価で)、そして無視できないことです。
それ以前には、アデレード大学のチームが公開した6つのビデオの1つから、バラク・オバマ大統領として分類された花を見てみましょう:プロジェクトページ:
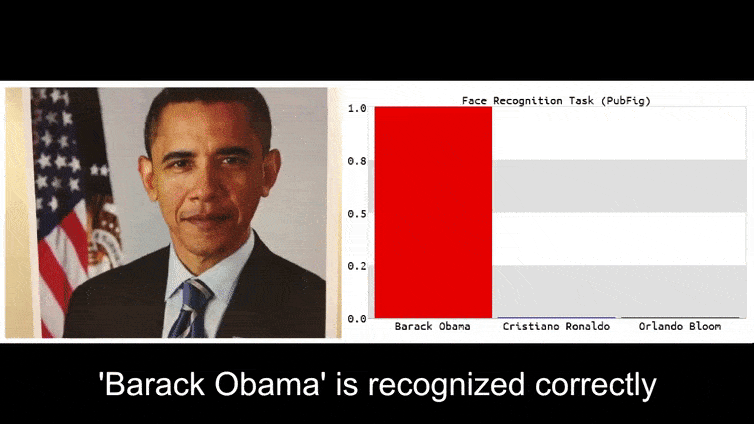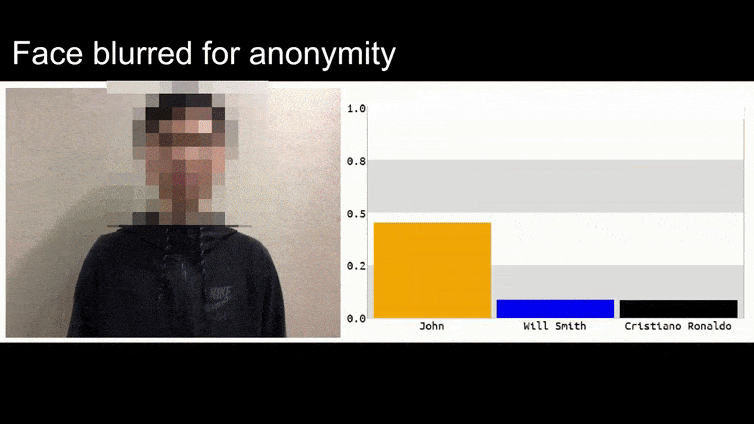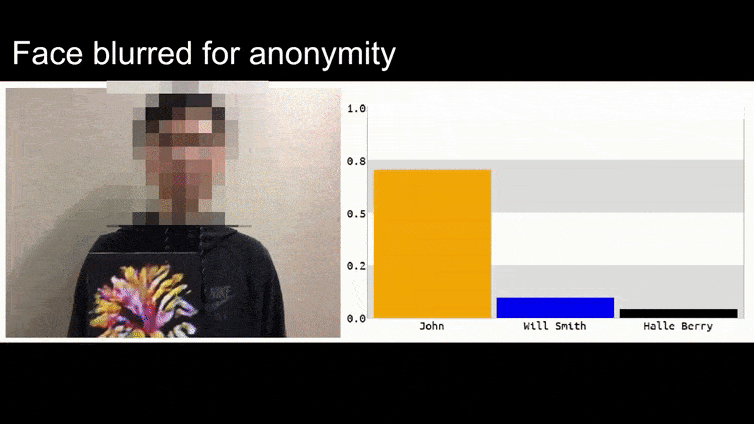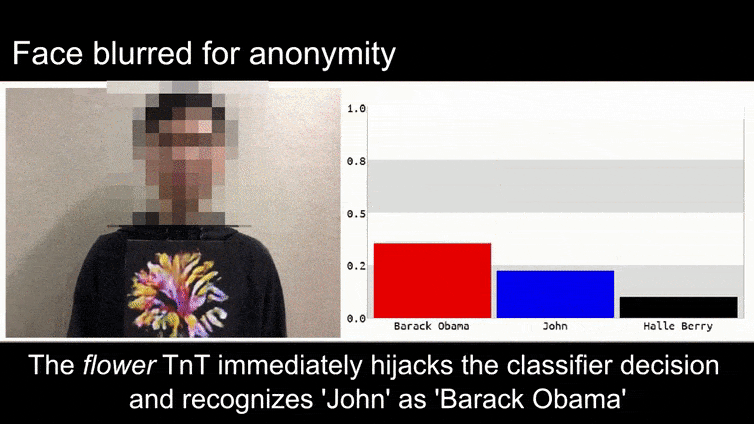
ソース:https://www.youtube.com/watch?v=Klepca1Ny3c
上の画像では、バラク・オバマを認識することができる顔認識システムは、80%の確率で匿名の男性が持っている作成されたアドバーサリアル画像の花もバラク・オバマであると誤認識しています。システムは、”偽の顔”が肩ではなく胸にあることにも気づきません。
研究者がこのようなアイデンティティキャプチャをランダムなノイズではなく、整合的な画像(花)で実現できたことは印象的ですが、このような愚かなエクスプロイトは、コンピュータビジョンのセキュリティ研究で頻繁に発生します。たとえば、2016年に顔認識を欺くことができた奇妙なパターンの眼鏡、または道路標識の意味を変更しようとする特別に作成されたアドバーサリアル画像などです。
興味がある場合は、上記の例で攻撃されるConvolutional Neural Network(CNN)モデルはVGGFace(VGG-16)であり、コロンビア大学のPubFigデータセットでトレーニングされています。研究者が開発した他の攻撃サンプルは、さまざまなリソースをさまざまな組み合わせで使用しました。

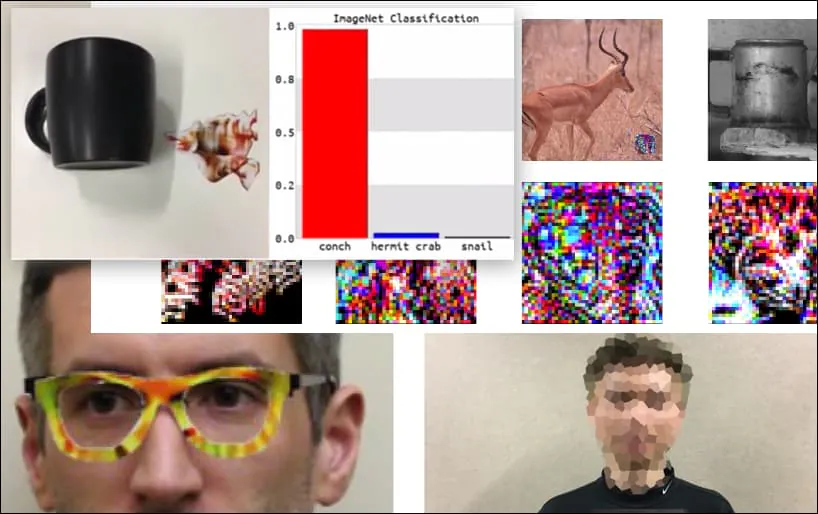
WideResNet50モデルでキーボードがコンチとして分類されます。研究者はモデルがコンチに偏りがないことを確認しました。https://www.youtube.com/watch?v=dhTTjjrxIcUで拡張および追加のデモをご覧ください
画像認識としての新たな攻撃ベクトル
研究者が示した多くの印象的な攻撃は、特定のデータセットや特定の機械学習アーキテクチャに対する批判ではなく、画像認識AI開発の全体的な現在のアーキテクチャの中央的な弱点を体現しています。この弱点は、将来の画像認識システムを攻撃者による容易な操作や、後の防御措置に脆弱性をもたらす可能性があります。
将来のセキュリティシステムに最新のアドバーサリアル攻撃画像(上記の花の例など)を「ゼロデイ・エクスプロイト」として追加することを想像してみましょう。現在のマルウェアやアンチウイルスフレームワークが毎日ウイルス定義を更新するのと同様にです。
新しいアドバーサリアル画像攻撃の可能性は無限大です。なぜなら、システムの基礎アーキテクチャは、下流の問題を予見できなかったからです。インターネット、ミレニアム・バグ、ピサの斜塔などの例があります。
では、どのようにしてこの状況を準備するのでしょうか。
攻撃に必要なデータの取得
上記の「花」の例のようなアドバーサリアル画像は、コンピュータモデルをトレーニングした画像データセットにアクセスすることで生成されます。トレーニングデータ(またはモデルアーキテクチャ)への「特権」アクセスは必要ありません。最も人気のあるデータセット(および多くのトレーニング済みモデル)は、広く利用可能で、常に更新されるトレントシーンで利用できます。
たとえば、コンピュータビジョンのデータセットの巨人であるImageNetは、トレントで利用可能です。通常の制限を回避し、重要な二次要素であるバリデーションセットを提供します。

ソース:https://academictorrents.com
データがあれば、アデレードの研究者が指摘しているように、CityScapesやCIFARなどの人気データセットを効果的に「逆コンパイル」できます。
先ほどの例で使用されたPubFigデータセットの場合、コロンビア大学は、画像データセットの再配布に関する著作権問題の増加に対処するために、研究者にカーソル付きリンクを介してデータセットを再現する方法を指示しています。「これは、他の多くの大規模なWebベースのデータベースが進化している方法のようです」と述べています。
ほとんどの場合、これは必要ありません。Kaggleは、コンピュータビジョンで最も人気のある10の画像データセットを推定しています。CIFAR-10とCIFAR-100(両方とも直接ダウンロード可能);CALTECH-101と256(両方とも利用可能で、現在トレントで利用可能);MNIST(公式に利用可能、トレントでも利用可能);ImageNet(上記を参照);Pascal VOC(利用可能、トレントでも利用可能);MS COCO(利用可能、トレントでも利用可能);Sports-1M(利用可能);およびYouTube-8M(利用可能)。
この利用可能性は、利用可能なコンピュータビジョン画像データセットのより広い範囲を表しています。なぜなら、オープンソース開発文化では、「公開するか死ぬか」であるからです。
新しいデータセットの入手可能な数の少なさ、画像セット開発の高コスト、古いデータセットへの依存度、古いデータセットを単純に適応させる傾向は、問題を悪化させます。
アドバーサリアル画像攻撃方法の典型的な批判
アドバーサリアル画像攻撃の有効性に対する機械学習エンジニアの最も頻繁で永続的な批判は、攻撃が特定のデータセット、特定のモデル、またはその両方に特有であるということです。つまり、他のシステムに「汎用性」がないということです。したがって、重大な脅威ではありません。
2番目に頻繁な批判は、アドバーサリアル画像攻撃が「ホワイトボックス」であるということです。つまり、トレーニング環境またはデータへの直接アクセスが必要です。これは、たとえばロンドンのメトロポリタン警察の顔認識システムのトレーニングプロセスを悪用したい場合、NECにコンソールまたは斧で侵入する必要があるため、ほとんどの場合にあり得ないシナリオです。
人気コンピュータビジョンデータセットの長期的な「DNA」
最初の批判については、コンピュータビジョン業界を支配するデータセットが年間でごく少数であること(たとえば、ImageNetはさまざまなオブジェクトタイプ、CityScapesは運転シーン、FFHQは顔認識のために使用される)、およびこれらのデータセットが「プラットフォーム非依存」で、高度に転送可能であることを考慮する必要があります。
コンピュータビジョントレーニングアーキテクチャは、ImageNetデータセットのオブジェクトやクラスのいくつかの特徴を見つけるでしょう。アーキテクチャによっては、他のアーキテクチャよりも多くの特徴を見つけたり、他のアーキテクチャよりも有用な接続を作ったりする場合がありますが、すべてのアーキテクチャは、少なくとも最上位の特徴を見つけるでしょう。

ImageNetデータ、最小限の正しい識別 – 「上位レベルの特徴」
これらの「上位レベルの特徴」がデータセットを区別し、「指紋」を付けるものであり、アーキテクチャ間でまたがり、データセットとともに成長することができる、長期的なアドバーサリアル画像攻撃方法論を構築するための信頼できる「フック」です。
より洗練されたアーキテクチャは、より正確で詳細な識別、特徴、クラスを生成します。

しかし、アドバーサリアル攻撃ジェネレーターがこれらの「下位」特徴(たとえば、「若いカウカシアン男性」ではなく「顔」)に依存するほど、クロスオーバーまたは後のアーキテクチャで効果が低くなります。ここでは、オリジナルのデータセットのサブセットまたはフィルタリングされたセットが使用され、オリジナルのデータセットの多くの画像が存在しません。

「ゼロ化」された、事前トレーニング済みモデルのアドバーサリアル攻撃
事前トレーニング済みモデルをダウンロードし、完全に新しいデータを与える場合、モデルはImageNetなどの非常に人気のあるデータセットでトレーニングされています。重みだけが残っており、これらは数週間または数か月かけてトレーニングされたもので、同じオブジェクトを識別するのを助けるために準備されています。

トレーニングアーキテクチャからオリジナルのデータを削除すると、モデルが元々学習した方法でオブジェクトを分類する「傾向」が残り、元々の「署名」が再形成され、再び同じ古いアドバーサリアル画像攻撃方法に対して脆弱になることになります。
これらの重みは貴重です。データまたは重みのいずれかがなければ、空のアーキテクチャしかないため、トレーニングからやり直す必要があります。オリジナルの作者が行ったように、多大な時間と計算リソースを費やす必要があります(おそらくはより強力なハードウェアとより高い予算で)。
問題は、重みがすでにかなり形成されており、頑健であるということです。トレーニング中に多少適応するでしょうが、新しいデータに対しては、元のデータに対してと同様の方法で動作するでしょう。アドバーサリアル攻撃システムがフックすることができるシグネチャ特徴を生成するでしょう。
長期的には、これはコンピュータビジョンデータセットの「DNA」を保存します。データセットは12歳以上で、オープンソースの取り組みから商業化された展開まで、注目に値する進化を遂げてきたからです。いくつかの商業化された展開はまだ発生していません。
ホワイトボックスは不要
アドバーサリアル画像攻撃システムの2番目に多い批判について、アデレード大学の論文の著者は、作成された画像(花)で画像認識システムを欺く能力が、さまざまなアーキテクチャに高い転送性があることを発見しました。
「[TnTs]は、ImageNetデータセットのLarge-Scale Visual RecognitionタスクのWideResNet50から、PubFigデータセットの顔認識タスクのVGG-faceモデルまで、幅広い最先端のクラシファイアに対して有効です。両方のターゲットと非ターゲット攻撃で。」
「TnTsは、トロイの木馬攻撃方法で使用されるトリガーと同等の自然主義を持ち、」
「アドバーサリアル例の汎用性と他のネットワークへの転送性を持ちます。」
「これは、すでに展開されたDNNと、将来のDNN展開について、安全性とセキュリティに関する懸念を引き起こします。攻撃者は、モデルを欺くために、目立たない自然なオブジェクトのパッチを使用できます。」
著者は、従来の対策として、ネットワークのクリーン精度を低下させることが理論的に防御を提供できる可能性があると示唆しています。しかし、「TnTsは、ほとんどの防御システムが0%の堅牢性を達成するSOTA provable防御方法を回避できます」と述べています。
他の可能な解決策としては、フェデレーテッドラーニングがあります。ここでは、寄稿画像の出所が保護されています。トレーニング時にデータを「暗号化」する新しいアプローチもあります。たとえば、南京航空航天大学が最近提案したものがあります。
これらの場合でも、本当に新しい画像データでトレーニングすることが重要です。現在、最も人気のあるCVデータセットの画像と注釈は、世界中の開発サイクルに埋もれており、数年前に大幅に更新されていないソフトウェアのように見えます。
結論
アドバーサリアル画像攻撃は、オープンソースの機械学習の慣行だけでなく、既存のコンピュータビジョンデータセットを商用AIプロジェクトで再利用することを促す企業のAI開発文化によっても可能になっています。なぜなら、これらのデータセットはすでに効果的であることが証明されており、最初からやり直すよりもはるかに安価であるからです。さらに、学術界と産業界の最先端の頭脳と組織によって維持および更新されており、単一の企業が複製するのが難しいレベルの資金と人員で行われているからです。
さらに、多くの場合、データはオリジナルではありません(CityScapesとは異なり)。画像は、最近のプライバシーとデータ収集慣行に関する論争の前に収集されたため、これらの古いデータセットは、会社の観点から見ると「安全な避難所」のように見える、ある種の「半合法の地獄」にあります。
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systemsは、Bao Gia Doan、Minhui Xue、Ehsan Abbasnejad、Damith C. Ranasinghe(アデレード大学)およびShiqing Ma(ラトガース大学コンピュータサイエンス学部)によって共同執筆されています。
2021年12月1日7:06 GMT+2 – タイポを修正しました。












