IA 101
¿Qué es el Aprendizaje por Refuerzo?
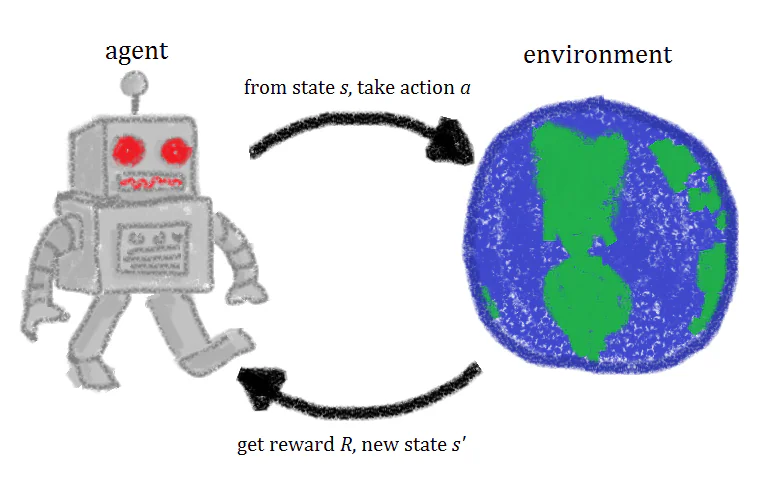
¿Qué es el Aprendizaje por Refuerzo?
En pocas palabras, el aprendizaje por refuerzo es una técnica de aprendizaje automático que implica entrenar a un agente de inteligencia artificial a través de la repetición de acciones y recompensas asociadas. Un agente de aprendizaje por refuerzo experimenta en un entorno, toma acciones y es recompensado cuando se toman las acciones correctas. Con el tiempo, el agente aprende a tomar las acciones que maximizarán su recompensa. Esa es una definición rápida del aprendizaje por refuerzo, pero tomar un vistazo más cercano a los conceptos detrás del aprendizaje por refuerzo te ayudará a ganar una comprensión mejor y más intuitiva de él.
El término “aprendizaje por refuerzo” se adapta del concepto de refuerzo en psicología. Por esa razón, tomemos un momento para entender el concepto psicológico de refuerzo. En el sentido psicológico, el término refuerzo se refiere a algo que aumenta la probabilidad de que una respuesta o acción en particular ocurra. Este concepto de refuerzo es una idea central de la teoría del condicionamiento operante, inicialmente propuesta por el psicólogo B.F. Skinner. En este contexto, el refuerzo es cualquier cosa que cause que la frecuencia de un comportamiento determinado aumente. Si pensamos en posibles refuerzos para los humanos, estos pueden ser cosas como elogios, un aumento en el trabajo, dulces y actividades divertidas.
En el sentido tradicional y psicológico, hay dos tipos de refuerzo. Hay refuerzo positivo y refuerzo negativo. El refuerzo positivo es la adición de algo para aumentar un comportamiento, como darle un premio a su perro cuando se comporta bien. El refuerzo negativo implica eliminar un estímulo para provocar un comportamiento, como apagar ruidos fuertes para atraer a un gato asustadizo.
Refuerzo Positivo y Negativo
El refuerzo positivo aumenta la frecuencia de un comportamiento mientras que el refuerzo negativo disminuye la frecuencia. En general, el refuerzo positivo es el tipo de refuerzo más comúnmente utilizado en el aprendizaje por refuerzo, ya que ayuda a los modelos a maximizar el rendimiento en una tarea determinada. No solo eso, sino que el refuerzo positivo lleva al modelo a hacer cambios más sostenibles, cambios que pueden convertirse en patrones consistentes y persistir durante largos períodos de tiempo.
En contraste, mientras que el refuerzo negativo también hace que un comportamiento sea más probable que ocurra, se utiliza para mantener un estándar de rendimiento mínimo en lugar de alcanzar el rendimiento máximo del modelo. El refuerzo negativo en el aprendizaje por refuerzo puede ayudar a asegurarse de que un modelo se mantenga alejado de acciones indeseables, pero no puede hacer que un modelo explore acciones deseables.
Entrenar a un Agente de Refuerzo
Cuando se entrena a un agente de aprendizaje por refuerzo, hay cuatro ingredientes diferentes o estados utilizados en el entrenamiento: estados iniciales (Estado 0), nuevo estado (Estado 1), acciones y recompensas.
Imagina que estamos entrenando a un agente de refuerzo para jugar un juego de plataformas donde el objetivo de la IA es llegar al final del nivel moviéndose hacia la derecha en la pantalla. El estado inicial del juego se extrae del entorno, lo que significa que el primer cuadro del juego se analiza y se le da al modelo. En base a esta información, el modelo debe decidir sobre una acción.
Durante las fases iniciales del entrenamiento, estas acciones son aleatorias, pero a medida que el modelo es reforzado, ciertas acciones se vuelven más comunes. Después de que se toma la acción, el entorno del juego se actualiza y se crea un nuevo estado o cuadro. Si la acción tomada por el agente produjo un resultado deseable, digamos que en este caso el agente sigue vivo y no ha sido golpeado por un enemigo, se le da una recompensa al agente y es más probable que haga lo mismo en el futuro.
Este sistema básico se repite constantemente, sucediendo una y otra vez, y cada vez el agente intenta aprender un poco más y maximizar su recompensa.
Tareas Episódicas vs Tareas Continuas
Las tareas de aprendizaje por refuerzo se pueden colocar típicamente en una de dos categorías diferentes: tareas episódicas y tareas continuas.
Las tareas episódicas llevarán a cabo el bucle de aprendizaje/entrenamiento y mejorarán su rendimiento hasta que se cumplan algunos criterios de finalización y se termine el entrenamiento. En un juego, esto podría ser llegar al final del nivel o caer en un peligro como espigas. En contraste, las tareas continuas no tienen criterios de terminación, esencialmente continuando el entrenamiento para siempre hasta que el ingeniero elija terminar el entrenamiento.
Monte Carlo vs Diferencia Temporal
Hay dos formas principales de aprender, o entrenar, a un agente de aprendizaje por refuerzo. En el enfoque de Monte Carlo, las recompensas se entregan al agente (su puntuación se actualiza) solo al final del episodio de entrenamiento. Para decirlo de otra manera, solo cuando se alcanza la condición de terminación, el modelo aprende cómo se desempeñó. Luego puede utilizar esta información para actualizar y, cuando se inicia la siguiente ronda de entrenamiento, responderá de acuerdo con la nueva información.
El método de diferencia temporal difiere del método de Monte Carlo en que la estimación de valor, o la estimación de puntuación, se actualiza durante el transcurso del episodio de entrenamiento. Una vez que el modelo avanza al siguiente paso de tiempo, los valores se actualizan.
Exploración vs Explotación
Entrenar a un agente de aprendizaje por refuerzo es un acto de equilibrio, que implica equilibrar dos métricas diferentes: exploración y explotación.
La exploración es el acto de recopilar más información sobre el entorno que rodea, mientras que la explotación es el uso de la información ya conocida sobre el entorno para ganar puntos de recompensa. Si un agente solo explora y nunca explota el entorno, las acciones deseables nunca se llevarán a cabo. Por otro lado, si el agente solo explota y nunca explora, el agente solo aprenderá a llevar a cabo una acción y no descubrirá otras estrategias posibles de ganar recompensas. Por lo tanto, equilibrar la exploración y la explotación es crítico al crear un agente de aprendizaje por refuerzo.
Casos de Uso para el Aprendizaje por Refuerzo
El aprendizaje por refuerzo se puede utilizar en una amplia variedad de roles, y es más adecuado para aplicaciones donde las tareas requieren automatización.
La automatización de tareas para ser realizadas por robots industriales es un área donde el aprendizaje por refuerzo demuestra ser útil. El aprendizaje por refuerzo también se puede utilizar para problemas como la minería de texto, creando modelos que puedan resumir largos cuerpos de texto. Los investigadores también están experimentando con el uso del aprendizaje por refuerzo en el campo de la salud, con agentes de refuerzo que manejan trabajos como la optimización de políticas de tratamiento. El aprendizaje por refuerzo también se puede utilizar para personalizar material educativo para los estudiantes.
Resumen del Aprendizaje por Refuerzo
El aprendizaje por refuerzo es un método poderoso para construir agentes de IA que pueden llevar a resultados impresionantes y a veces sorprendentes. Entrenar a un agente a través del aprendizaje por refuerzo puede ser complejo y difícil, ya que requiere muchas iteraciones de entrenamiento y un equilibrio delicado de la dicotomía explorar/explotar. Sin embargo, si se logra, un agente creado con aprendizaje por refuerzo puede realizar tareas complejas en una amplia variedad de entornos diferentes.








