
AI 101
¿Qué es un árbol de decisiones?
¿Qué es un árbol de decisiones?
A árbol de decisión es un algoritmo de aprendizaje automático útil que se utiliza tanto para tareas de regresión como de clasificación. El nombre "árbol de decisión" proviene del hecho de que el algoritmo sigue dividiendo el conjunto de datos en porciones cada vez más pequeñas hasta que los datos se dividen en instancias individuales, que luego se clasifican. Si visualizaras los resultados del algoritmo, la forma en que se dividen las categorías se parecería a un árbol y muchas hojas.
Esa es una definición rápida de un árbol de decisión, pero profundicemos en cómo funcionan los árboles de decisión. Tener una mejor comprensión de cómo funcionan los árboles de decisión, así como sus casos de uso, lo ayudará a saber cuándo utilizarlos durante sus proyectos de aprendizaje automático.
Formato de un árbol de decisión
Un árbol de decisión es muy parecido a un diagrama de flujo. Para utilizar un diagrama de flujo, comienza en el punto de inicio, o raíz, del gráfico y luego, en función de cómo responda a los criterios de filtrado de ese nodo inicial, se mueve a uno de los siguientes nodos posibles. Este proceso se repite hasta llegar a un final.
Los árboles de decisión funcionan esencialmente de la misma manera, siendo cada nodo interno del árbol una especie de criterio de prueba/filtrado. Los nodos en el exterior, los puntos finales del árbol, son las etiquetas para el punto de datos en cuestión y se denominan "hojas". Las ramas que conducen desde los nodos internos al siguiente nodo son características o conjunciones de características. Las reglas que se utilizan para clasificar los puntos de datos son los caminos que van desde la raíz hasta las hojas.
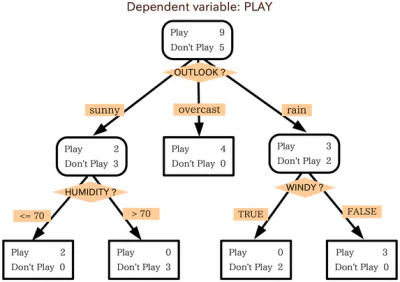
Algoritmos para árboles de decisión
Los árboles de decisión funcionan con un enfoque algorítmico que divide el conjunto de datos en puntos de datos individuales en función de diferentes criterios. Estas divisiones se realizan con diferentes variables o las diferentes características del conjunto de datos. Por ejemplo, si el objetivo es determinar si las características de entrada describen o no un perro o un gato, las variables en las que se dividen los datos pueden ser cosas como "garras" y "ladridos".
Entonces, ¿qué algoritmos se usan para dividir los datos en ramas y hojas? Existen varios métodos que se pueden usar para dividir un árbol, pero el método más común de división es probablemente una técnica denominada "división binaria recursiva”. Al llevar a cabo este método de división, el proceso comienza en la raíz y la cantidad de características en el conjunto de datos representa la cantidad posible de divisiones posibles. Se usa una función para determinar cuánta precisión costará cada división posible, y la división se realiza utilizando los criterios que sacrifican la menor precisión. Este proceso se lleva a cabo de forma recursiva y se forman subgrupos utilizando la misma estrategia general.
Llene la determinar el costo de la división, se utiliza una función de costo. Se utiliza una función de costo diferente para las tareas de regresión y las tareas de clasificación. El objetivo de ambas funciones de costo es determinar qué sucursales tienen los valores de respuesta más similares o las sucursales más homogéneas. Considere que desea que los datos de prueba de una cierta clase sigan ciertas rutas y esto tiene sentido intuitivo.
En términos de la función de costo de regresión para división binaria recursiva, el algoritmo utilizado para calcular el costo es el siguiente:
suma(y – predicción)^2
La predicción para un grupo particular de puntos de datos es la media de las respuestas de los datos de entrenamiento para ese grupo. Todos los puntos de datos se ejecutan a través de la función de costo para determinar el costo de todas las divisiones posibles y se selecciona la división con el costo más bajo.
En cuanto a la función de costo por clasificación, la función es la siguiente:
G = suma (paquete * (1 – paquete))
Este es el puntaje de Gini, y es una medida de la efectividad de una división, en función de cuántas instancias de diferentes clases hay en los grupos resultantes de la división. En otras palabras, cuantifica qué tan mezclados están los grupos después de la división. Una división óptima es cuando todos los grupos resultantes de la división consisten solo en entradas de una clase. Si se ha creado una división óptima, el valor "pk" será 0 o 1 y G será igual a cero. Es posible que pueda adivinar que la división en el peor de los casos es aquella en la que hay una representación 50-50 de las clases en la división, en el caso de la clasificación binaria. En este caso, el valor de “pk” sería 0.5 y G también sería 0.5.
El proceso de división finaliza cuando todos los puntos de datos se han convertido en hojas y se han clasificado. Sin embargo, es posible que desee detener el crecimiento del árbol antes de tiempo. Los árboles grandes y complejos son propensos al sobreajuste, pero se pueden usar varios métodos diferentes para combatir esto. Un método para reducir el sobreajuste es especificar un número mínimo de puntos de datos que se utilizarán para crear una hoja. Otro método para controlar el sobreajuste es restringir el árbol a una cierta profundidad máxima, que controla cuánto puede extenderse un camino desde la raíz hasta una hoja.
Otro proceso involucrado en la creación de árboles de decisión es poda. La poda puede ayudar a aumentar el rendimiento de un árbol de decisiones eliminando las ramas que contienen características que tienen poco poder predictivo o poca importancia para el modelo. De esta forma, se reduce la complejidad del árbol, es menos probable que se sobreajuste y aumenta la utilidad predictiva del modelo.
Al realizar la poda, el proceso puede comenzar en la parte superior o inferior del árbol. Sin embargo, el método más sencillo de poda es comenzar con las hojas e intentar descartar el nodo que contiene la clase más común dentro de esa hoja. Si la precisión del modelo no se deteriora cuando se hace esto, entonces se conserva el cambio. Hay otras técnicas que se utilizan para llevar a cabo la poda, pero el método descrito anteriormente (poda de errores reducidos) es probablemente el método más común de poda del árbol de decisión.
Consideraciones para el uso de árboles de decisión
Árboles de decisión a menudo son útiles cuando es necesario llevar a cabo la clasificación pero el tiempo de cálculo es una limitación importante. Los árboles de decisión pueden dejar en claro qué características en los conjuntos de datos elegidos ejercen el mayor poder predictivo. Además, a diferencia de muchos algoritmos de aprendizaje automático en los que las reglas utilizadas para clasificar los datos pueden ser difíciles de interpretar, los árboles de decisión pueden generar reglas interpretables. Los árboles de decisión también pueden utilizar variables categóricas y continuas, lo que significa que se necesita menos procesamiento previo, en comparación con los algoritmos que solo pueden manejar uno de estos tipos de variables.
Los árboles de decisión tienden a no funcionar muy bien cuando se utilizan para determinar los valores de atributos continuos. Otra limitación de los árboles de decisión es que, al clasificar, si hay pocos ejemplos de entrenamiento pero muchas clases, el árbol de decisión tiende a ser inexacto.










