
AI 101
¿Qué es el sobreajuste?
¿Qué es el sobreajuste?
Cuando entrena una red neuronal, debe evitar el sobreajuste. Sobreajuste Es un problema dentro del aprendizaje automático y las estadísticas donde un modelo aprende demasiado bien los patrones de un conjunto de datos de entrenamiento, explicando perfectamente el conjunto de datos de entrenamiento pero no logra generalizar su poder predictivo a otros conjuntos de datos.
Para decirlo de otra manera, en el caso de un modelo sobreajustado, a menudo mostrará una precisión extremadamente alta en el conjunto de datos de entrenamiento, pero una precisión baja en los datos recopilados y ejecutados a través del modelo en el futuro. Esa es una definición rápida de sobreajuste, pero repasemos el concepto de sobreajuste con más detalle. Echemos un vistazo a cómo se produce el sobreajuste y cómo se puede evitar.
Comprender el "ajuste" y el desajuste
Es útil echar un vistazo al concepto de desadaptación y “cómodo”generalmente cuando se habla de sobreajuste. Cuando entrenamos un modelo, intentamos desarrollar un marco que sea capaz de predecir la naturaleza o clase de los elementos dentro de un conjunto de datos, en función de las características que describen esos elementos. Un modelo debería poder explicar un patrón dentro de un conjunto de datos y predecir las clases de puntos de datos futuros basados en este patrón. Cuanto mejor explique el modelo la relación entre las características del conjunto de entrenamiento, más "ajustado" será nuestro modelo.
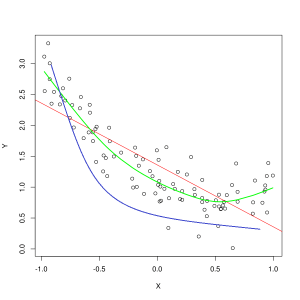
La línea azul representa las predicciones de un modelo que no se ajusta correctamente, mientras que la línea verde representa un modelo de mejor ajuste. Foto: Pep Roca vía Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Un modelo que explica mal la relación entre las características de los datos de entrenamiento y, por lo tanto, no clasifica con precisión los ejemplos de datos futuros es desajuste los datos de entrenamiento. Si tuviera que graficar la relación predicha de un modelo de ajuste insuficiente frente a la intersección real de las características y las etiquetas, las predicciones se desviarían de la marca. Si tuviéramos un gráfico con los valores reales de un conjunto de entrenamiento etiquetados, un modelo severamente inadecuado perdería drásticamente la mayoría de los puntos de datos. Un modelo con un mejor ajuste podría trazar un camino a través del centro de los puntos de datos, con puntos de datos individuales que están solo un poco fuera de los valores predichos.
El ajuste insuficiente a menudo puede ocurrir cuando no hay datos suficientes para crear un modelo preciso o cuando se intenta diseñar un modelo lineal con datos no lineales. Más datos de entrenamiento o más funciones a menudo ayudarán a reducir el desajuste.
Entonces, ¿por qué no creamos un modelo que explique perfectamente cada punto de los datos de entrenamiento? ¿Seguramente es deseable una precisión perfecta? La creación de un modelo que ha aprendido demasiado bien los patrones de los datos de entrenamiento es lo que provoca el sobreajuste. El conjunto de datos de entrenamiento y otros conjuntos de datos futuros que ejecute a través del modelo no serán exactamente iguales. Es probable que sean muy similares en muchos aspectos, pero también diferirán en aspectos clave. Por lo tanto, diseñar un modelo que explique perfectamente el conjunto de datos de entrenamiento significa que termina con una teoría sobre la relación entre características que no se generaliza bien a otros conjuntos de datos.
Comprender el sobreajuste
El sobreajuste ocurre cuando un modelo aprende demasiado bien los detalles dentro del conjunto de datos de entrenamiento, lo que hace que el modelo sufra cuando se realizan predicciones sobre datos externos. Esto puede ocurrir cuando el modelo no solo aprende las características del conjunto de datos, sino que también aprende fluctuaciones aleatorias o ruido dentro del conjunto de datos, dando importancia a estas ocurrencias aleatorias/sin importancia.
Es más probable que ocurra un sobreajuste cuando se utilizan modelos no lineales, ya que son más flexibles cuando aprenden las características de los datos. Los algoritmos de aprendizaje automático no paramétrico a menudo tienen varios parámetros y técnicas que se pueden aplicar para restringir la sensibilidad del modelo a los datos y, por lo tanto, reducir el sobreajuste. Como ejemplo, modelos de árboles de decisión son muy sensibles al sobreajuste, pero se puede usar una técnica llamada poda para eliminar aleatoriamente algunos de los detalles que el modelo ha aprendido.
Si tuviera que graficar las predicciones del modelo en los ejes X e Y, tendría una línea de predicción que zigzaguea de un lado a otro, lo que refleja el hecho de que el modelo se ha esforzado demasiado por encajar todos los puntos del conjunto de datos en su explicación.
Control de sobreajuste
Cuando entrenamos un modelo, idealmente queremos que el modelo no cometa errores. Cuando el rendimiento del modelo converge hacia la realización de predicciones correctas en todos los puntos de datos del conjunto de datos de entrenamiento, el ajuste es cada vez mejor. Un modelo con un buen ajuste puede explicar casi todo el conjunto de datos de entrenamiento sin sobreajustarse.
A medida que un modelo entrena, su rendimiento mejora con el tiempo. La tasa de error del modelo disminuirá a medida que pase el tiempo de entrenamiento, pero solo disminuirá hasta cierto punto. El punto en el que el rendimiento del modelo en el conjunto de prueba comienza a aumentar de nuevo suele ser el punto en el que se produce el sobreajuste. Para obtener el mejor ajuste para un modelo, queremos dejar de entrenar el modelo en el punto de menor pérdida en el conjunto de entrenamiento, antes de que el error comience a aumentar nuevamente. El punto de parada óptimo se puede determinar graficando el rendimiento del modelo a lo largo del tiempo de entrenamiento y deteniendo el entrenamiento cuando la pérdida es mínima. Sin embargo, un riesgo con este método de control del sobreajuste es que especificar el punto final para el entrenamiento basado en el rendimiento de la prueba significa que los datos de la prueba se incluyen de alguna manera en el procedimiento de entrenamiento y pierden su estado como datos puramente "intactos".
Hay un par de formas diferentes en las que uno puede combatir el sobreajuste. Un método para reducir el sobreajuste es utilizar una táctica de remuestreo, que opera estimando la precisión del modelo. También puedes usar un validación conjunto de datos además del conjunto de prueba y trazar la precisión del entrenamiento contra el conjunto de validación en lugar del conjunto de datos de prueba. Esto mantiene su conjunto de datos de prueba oculto. Un método popular de remuestreo es la validación cruzada de K-folds. Esta técnica le permite dividir sus datos en subconjuntos en los que se entrena el modelo, y luego se analiza el rendimiento del modelo en los subconjuntos para estimar cómo funcionará el modelo en datos externos.
Hacer uso de la validación cruzada es una de las mejores formas de estimar la precisión de un modelo en datos no vistos, y cuando se combina con un conjunto de datos de validación, el sobreajuste a menudo se puede mantener al mínimo.










