
AI 101
¿Qué es una Red Adversaria Generativa (GAN)?
Redes Adversarias Generativas (GAN) son tipos de arquitecturas de redes neuronales capaz de generar nuevos datos que se ajusta a los patrones aprendidos. Las GAN se pueden utilizar para generar imágenes de rostros humanos u otros objetos, para realizar la traducción de texto a imagen, para convertir un tipo de imagen en otro y para mejorar la resolución de las imágenes (superresolución), entre otras aplicaciones. Debido a que las GAN pueden generar datos completamente nuevos, están a la cabeza de muchos sistemas, aplicaciones e investigaciones de IA de vanguardia. Sin embargo, ¿cómo funcionan exactamente las GAN? Exploremos cómo funcionan las GAN y echemos un vistazo a algunos de sus usos principales.
Definición de modelos generativos y GAN
Una GAN es un ejemplo de un modelo generativo. La mayoría de los modelos de IA se pueden dividir en una de dos categorías: modelos supervisados y no supervisados. Los modelos de aprendizaje supervisado se utilizan normalmente para discriminar entre diferentes categorías de entradas, para clasificar. Por el contrario, los modelos no supervisados se utilizan normalmente para resumir la distribución de datos, a menudo aprendiendo una distribución gaussiana de los datos. Debido a que aprenden la distribución de un conjunto de datos, pueden extraer muestras de esta distribución aprendida y generar nuevos datos.
Diferentes modelos generativos tienen diferentes métodos para generar datos y calcular distribuciones de probabilidad. por ejemplo, el Modelo bayesiano ingenuo opera calculando una distribución de probabilidad para las diversas características de entrada y la clase generativa. Cuando el modelo Naive Bayes genera una predicción, calcula la clase más probable tomando la probabilidad de las diferentes variables y combinándolas. Otros modelos generativos que no son de aprendizaje profundo incluyen los modelos de mezcla gaussiana y la asignación de Dirichlet latente (LDA). Modelos generativos basados en la inclinación profunda incluir Máquinas de Boltzmann restringidas (RBM), Autoencoders variables (VAE)y, por supuesto, GAN.
Las Redes Adversarias Generativas fueron propuesto por primera vez por Ian Goodfellow en 2014, y Alec Redford y otros investigadores las mejoraron en 2015, lo que llevó a una arquitectura estandarizada para las GAN. Las GAN son en realidad dos redes diferentes unidas. Las GAN son compuesto por dos mitades: un modelo de generación y un modelo de discriminación, también denominado generador y discriminador.
La arquitectura GAN
Las redes adversarias generativas son construido a partir de un modelo generador y un modelo discriminador juntos. El trabajo del modelo generador es crear nuevos ejemplos de datos, basados en los patrones que el modelo ha aprendido de los datos de entrenamiento. El trabajo del modelo discriminador es analizar imágenes (asumiendo que está entrenado en imágenes) y determinar si las imágenes son generadas, falsas o genuinas.

Los dos modelos se enfrentan entre sí, entrenados en forma de teoría de juegos. El objetivo del modelo generador es producir imágenes que engañen a su adversario, el modelo discriminador. Mientras tanto, el trabajo del modelo discriminador es vencer a su adversario, el modelo generador, y atrapar las imágenes falsas que produce el generador. El hecho de que los modelos se enfrenten entre sí da como resultado una carrera armamentista en la que ambos modelos mejoran. El discriminador obtiene retroalimentación sobre qué imágenes eran genuinas y qué imágenes fueron producidas por el generador, mientras que el generador recibe información sobre cuáles de sus imágenes fueron marcadas como falsas por el discriminador. Ambos modelos mejoran durante el entrenamiento, con el objetivo de entrenar un modelo de generación que pueda producir datos falsos que son básicamente indistinguibles de los datos reales y genuinos.
Una vez que se ha creado una distribución gaussiana de datos durante el entrenamiento, se puede usar el modelo generativo. El modelo generador recibe inicialmente un vector aleatorio, que transforma en función de la distribución gaussiana. En otras palabras, el vector siembra la generación. Cuando se entrena el modelo, el espacio vectorial será una versión comprimida, o representación, de la distribución gaussiana de los datos. La versión comprimida de la distribución de datos se denomina espacio latente o variables latentes. Más adelante, el modelo GAN puede tomar la representación del espacio latente y extraer puntos de ella, que pueden asignarse al modelo de generación y usarse para generar nuevos datos que son muy similares a los datos de entrenamiento.
El modelo discriminador recibe ejemplos de todo el dominio de entrenamiento, que se compone de ejemplos de datos reales y generados. Los ejemplos reales están contenidos dentro del conjunto de datos de entrenamiento, mientras que los datos falsos son producidos por el modelo generativo. El proceso de entrenamiento del modelo discriminador es exactamente el mismo que el entrenamiento básico del modelo de clasificación binaria.
Proceso de formación GAN
Veamos todo la formación para una tarea hipotética de generación de imágenes.
Para empezar, la GAN se entrena utilizando imágenes reales y genuinas como parte del conjunto de datos de entrenamiento. Esto configura el modelo discriminador para distinguir entre imágenes generadas e imágenes reales. También produce la distribución de datos que el generador utilizará para producir nuevos datos.
El generador toma un vector de datos numéricos aleatorios y los transforma en función de la distribución gaussiana, devolviendo una imagen. Estas imágenes generadas, junto con algunas imágenes genuinas del conjunto de datos de entrenamiento, se introducen en el modelo discriminador. El discriminador generará una predicción probabilística sobre la naturaleza de las imágenes que recibe, generando un valor entre 0 y 1, donde 1 suele ser imágenes auténticas y 0 es una imagen falsa.
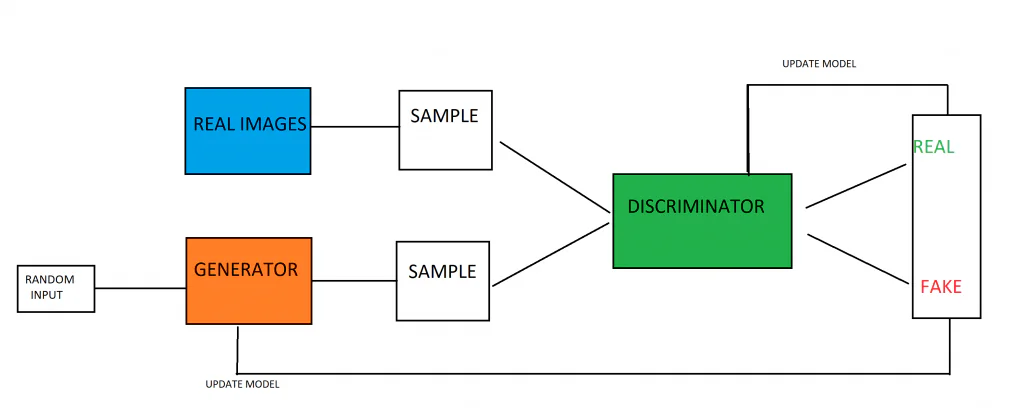
Hay un bucle de retroalimentación doble en juego, ya que el discriminador de tierra recibe la verdad de las imágenes, mientras que el generador recibe retroalimentación sobre su desempeño por parte del discriminador.
Los modelos generativo y de discriminación están jugando un juego de suma cero entre sí. Un juego de suma cero es aquel en el que las ganancias de un lado se obtienen a costa del otro lado (la suma de ambas acciones es cero ex). Cuando el modelo discriminador es capaz de distinguir con éxito entre ejemplos reales y falsos, no se realizan cambios en los parámetros del discriminador. Sin embargo, se realizan grandes actualizaciones en los parámetros del modelo cuando no distingue entre imágenes reales y falsas. Lo contrario es cierto para el modelo generativo, se penaliza (y sus parámetros se actualizan) cuando no logra engañar al modelo discriminativo, pero de lo contrario sus parámetros no cambian (o se recompensa).
Idealmente, el generador puede mejorar su rendimiento hasta el punto en que el discriminador no puede discernir entre las imágenes falsas y las reales. Esto significa que el discriminador siempre generará probabilidades del 50% para imágenes reales y falsas, lo que significa que las imágenes generadas no deben distinguirse de las imágenes genuinas. En la práctica, las GAN normalmente no llegarán a este punto. Sin embargo, el modelo generativo no necesita crear imágenes perfectamente similares para seguir siendo útil para las muchas tareas para las que se utilizan las GAN.
Aplicaciones GAN
Las GAN tienen varias aplicaciones diferentes, la mayoría de las cuales giran en torno a la generación de imágenes y componentes de imágenes. Las GAN se usan comúnmente en tareas en las que faltan los datos de imagen requeridos o están limitados en alguna capacidad, como método para generar los datos requeridos. Examinemos algunos de los casos de usos comunes de las GAN.
Generación de nuevos ejemplos para conjuntos de datos
Las GAN se pueden usar para generar nuevos ejemplos para conjuntos de datos de imágenes simples. Si solo tiene un puñado de ejemplos de entrenamiento y necesita más, las GAN podrían usarse para generar nuevos datos de entrenamiento para un clasificador de imágenes, generando nuevos ejemplos de entrenamiento en diferentes orientaciones y ángulos.
Generación de rostros humanos únicos

La mujer de esta foto no existe. La imagen fue generada por StyleGAN. Foto: Owlsmcgee a través de Wikimedia Commons, dominio público (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
Cuando están suficientemente entrenados, los GAN se pueden usar para generar imágenes extremadamente realistas de rostros humanos. Estas imágenes generadas se pueden utilizar para ayudar a entrenar los sistemas de reconocimiento facial.
Traducción de imagen a imagen
GAN sobresalir en la traducción de imágenes. Las GAN se pueden usar para colorear imágenes en blanco y negro, traducir bocetos o dibujos en imágenes fotográficas o convertir imágenes del día a la noche.
Traducción de texto a imagen
La traducción de texto a imagen es posible mediante el uso de GAN. Cuando se le proporciona un texto que describe una imagen y la imagen que la acompaña, una GAN puede estar capacitado para crear una nueva imagen cuando se le proporciona una descripción de la imagen deseada.
Edición y reparación de imágenes
Las GAN se pueden usar para editar fotografías existentes. GAN eliminar elementos como la lluvia o la nieve de una imagen, pero también se pueden utilizar para reparar imágenes viejas, dañadas o imágenes corruptas.
Súper resolución
La superresolución es el proceso de tomar una imagen de baja resolución e insertar más píxeles en la imagen, mejorando la resolución de esa imagen. Las GAN se pueden entrenar para tomar una imagen y generar una versión de mayor resolución de esa imagen.














