IA 101
¿Qué son las CNN (Redes Neuronales Convolucionales)?
Tal vez te hayas preguntado cómo Facebook o Instagram pueden reconocer automáticamente caras en una imagen, o cómo Google te permite buscar en la web fotos similares solo subiendo una foto tuya. Estas características son ejemplos de visión por computadora, y están impulsadas por redes neuronales convolucionales (CNN). Sin embargo, ¿qué son exactamente las redes neuronales convolucionales? Hagamos un análisis profundo de la arquitectura de una CNN y comprendamos cómo operan.
¿Qué son las Redes Neuronales?
Antes de comenzar a hablar sobre redes neuronales convolucionales, tomémonos un momento para definir una red neuronal regular. Hay otro artículo sobre el tema de las redes neuronales disponible, así que no nos adentraremos demasiado en ellas aquí. Sin embargo, para definirlas brevemente, son modelos computacionales inspirados en el cerebro humano. Una red neuronal opera tomando datos y manipulando los datos ajustando “pesos”, que son suposiciones sobre cómo las características de entrada se relacionan entre sí y la clase del objeto. A medida que se entrena la red, los valores de los pesos se ajustan y esperamos que converjan en pesos que capturen con precisión las relaciones entre las características.
Esta es la forma en que opera una red neuronal de feed-forward, y las CNN están compuestas por dos mitades: una red neuronal de feed-forward y un grupo de capas convolucionales.
¿Qué son las Redes Neuronales Convolucionales (CNN)?
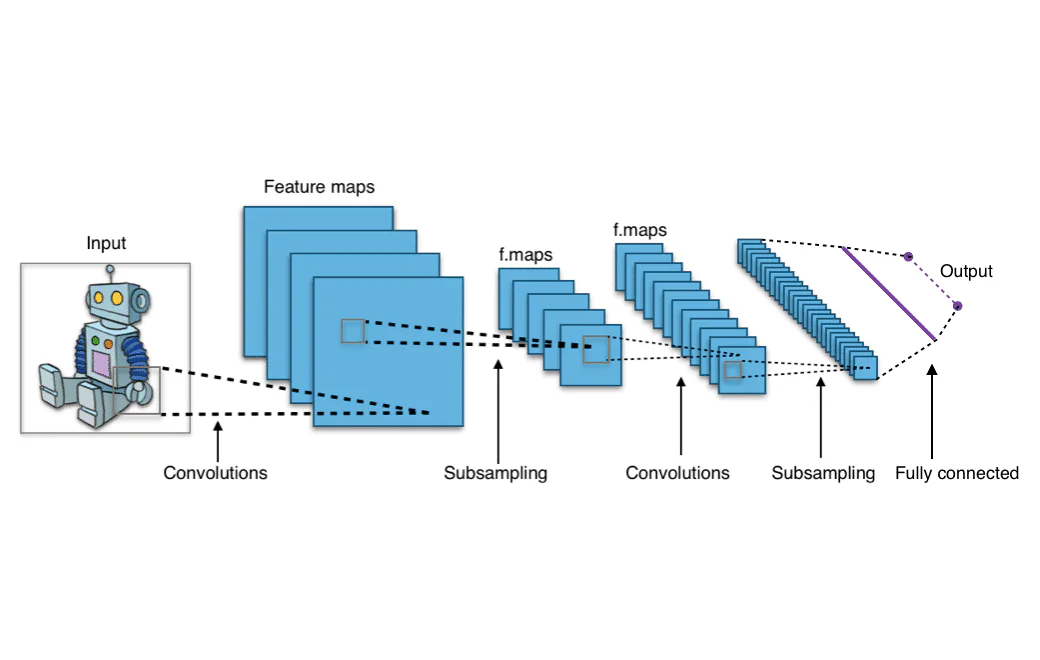
¿Qué son las “convoluciones” que ocurren en una red neuronal convolucional? Una convolución es una operación matemática que crea un conjunto de pesos, esencialmente creando una representación de partes de la imagen. Este conjunto de pesos se refiere a como un núcleo o filtro. El filtro que se crea es más pequeño que la imagen de entrada completa, cubriendo solo una subsección de la imagen. Los valores en el filtro se multiplican con los valores en la imagen. El filtro se mueve sobre la imagen para formar una representación de una nueva parte de la imagen, y el proceso se repite hasta que se ha cubierto toda la imagen.
Otra forma de pensar en esto es imaginar un muro de ladrillos, con los ladrillos que representan los píxeles en la imagen de entrada. Una “ventana” se desliza hacia atrás y hacia adelante a lo largo del muro, que es el filtro. Los ladrillos que son visibles a través de la ventana son los píxeles que tienen su valor multiplicado por los valores dentro del filtro. Por esta razón, este método de crear pesos con un filtro a menudo se refiere como la técnica de “ventanas deslizantes”.
La salida de los filtros que se mueven alrededor de la imagen de entrada completa es una matriz bidimensional que representa la imagen completa. Esta matriz se llama “mapa de características”.
¿Por qué las Convoluciones son Esenciales
¿Cuál es el propósito de crear convoluciones de todos modos? Las convoluciones son necesarias porque una red neuronal tiene que ser capaz de interpretar los píxeles en una imagen como valores numéricos. La función de las capas convolucionales es convertir la imagen en valores numéricos que la red neuronal pueda interpretar y luego extraer patrones relevantes de ella. El trabajo de los filtros en la red convolucional es crear una matriz bidimensional de valores que se pueden pasar a las capas posteriores de una red neuronal, que aprenderán los patrones en la imagen.
Filtros y Canales
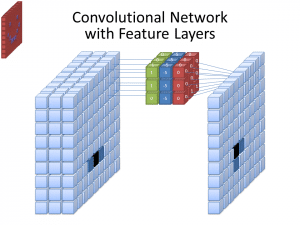
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
Las CNN no utilizan solo un filtro para aprender patrones de las imágenes de entrada. Se utilizan múltiples filtros, ya que los diferentes arreglos creados por los diferentes filtros conducen a una representación más compleja y rica de la imagen de entrada. Números comunes de filtros para las CNN son 32, 64, 128 y 512. Cuantos más filtros haya, más oportunidades tendrá la CNN para examinar los datos de entrada y aprender de ellos.
Una CNN analiza las diferencias en los valores de los píxeles para determinar los bordes de los objetos. En una imagen en escala de grises, la CNN solo consideraría las diferencias en términos de blanco y negro, de claro a oscuro. Cuando las imágenes son imágenes en color, no solo la CNN considera la oscuridad y la luz, sino que también debe considerar los tres canales de color diferentes – rojo, verde y azul. En este caso, los filtros poseen 3 canales, al igual que la imagen en sí. El número de canales que tiene un filtro se refiere a como su profundidad, y el número de canales en el filtro debe coincidir con el número de canales en la imagen.
Arquitectura de la Red Neuronal Convolucional (CNN)
Veamos la arquitectura completa de una red neuronal convolucional. Una capa convolucional se encuentra al comienzo de cada red convolucional, ya que es necesario transformar los datos de la imagen en matrices numéricas. Sin embargo, las capas convolucionales también pueden venir después de otras capas convolucionales, lo que significa que estas capas pueden apilarse una sobre otra. Tener múltiples capas convolucionales significa que las salidas de una capa pueden someterse a convoluciones adicionales y agruparse en patrones relevantes. En la práctica, esto significa que a medida que los datos de la imagen pasan a través de las capas convolucionales, la red comienza a “reconocer” características más complejas de la imagen.
Las capas iniciales de una ConvNet son responsables de extraer las características de bajo nivel, como los píxeles que componen líneas simples. Las capas posteriores de la ConvNet unirán estas líneas en formas. Este proceso de pasar de un análisis de superficie a un análisis profundo continúa hasta que la ConvNet reconoce formas complejas como animales, caras humanas y coches.
Después de que los datos han pasado a través de todas las capas convolucionales, proceden a la parte densamente conectada de la CNN. Las capas densamente conectadas son lo que una red neuronal de feed-forward tradicional parece, una serie de nodos dispuestos en capas que están conectados entre sí. Los datos proceden a través de estas capas densamente conectadas, que aprenden los patrones que se extrajeron de las capas convolucionales, y al hacerlo, la red se vuelve capaz de reconocer objetos.










