人工智能
不,他们没有限制 Claude – 事实上更糟糕

好了,让我们谈谈最近发生在 Claude 身上的事情,因为如果你过去一个月使用过它,你可能已经注意到有些事情不对劲。
在过去的六周里,Claude 的用户们都快疯了。从八月初开始,投诉开始在 Reddit、X 和开发者论坛上涌现。问题无处不在:
- 曾经完美工作的代码突然变得有问题
- Claude 声称它对文件进行了修改,但实际上并没有
- 英语回复中突然出现了随机的泰语或中文字符
- 完全忽略指令
- 相同的提示产生了极其不同的质量回复
- Claude Code 用户说它感觉像被“阉割”了一样,与之前相比
投诉变得如此严重,以至于到八月底,人们都相信 Anthropic 正在秘密限制 Claude 以节省钱。阴谋论无处不在 – 也许他们在高峰时段降低了质量,也许他们悄悄地换成了更便宜的模型,也许这是故意降级以管理服务器成本。
用户正在为 Claude Pro 支付费用,但他们感觉像是得到的却是 Claude Lite。围绕 Claude 建立工作流程的开发人员突然发现他们的生产力直线下降。话虽如此,一些用户根本没有遇到任何问题,这让一切更加令人困惑。
Anthropic 最终承认:是的,我们遇到了问题
在数周的用户投诉和日益增长的沮丧之后, Anthropic 刚刚发布了一份大规模的技术事后分析,基本上说:“你们是对的。Claude 出了问题。以下是发生了什么。”
答案很有趣。
事实证明这不是一个问题,而是三个完全独立的基础设施错误,同时发生,造成了人工智能退化的完美风暴。他们没有限制。他们没有削减角落。他们只是有三个不同的东西同时坏掉,以一种需要六周时间才能完全理解和修复的方式。
让我详细解释一下到底出了什么问题,因为这实际上是一个有用的视角,展示了这些人工智能系统如何以没有人预料到的方式失败。
三重 Bug 灾难:混乱的时间线
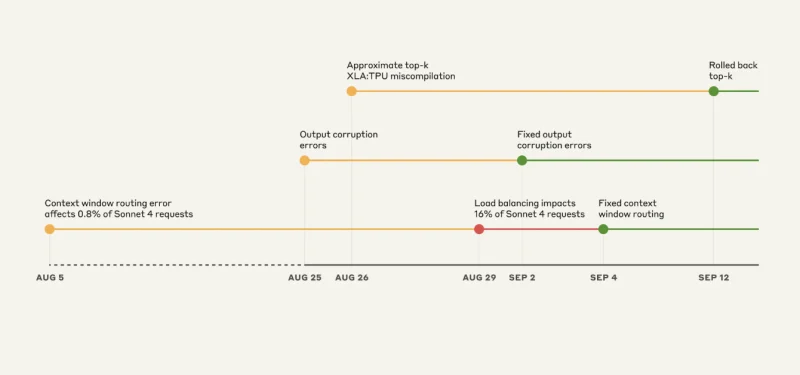
来源:Anthropic
Bug #1:错误的服务器问题
这几乎很有趣,如果你不是正在经历它的人。Claude Sonnet 4 被设计为处理 200,000 个令牌上下文。但从 8 月 5 日开始,一些请求被路由到配置为 1,000,000 个令牌上下文的服务器。
最初,只有 0.8% 的请求受到影响。没什么大不了的,对吧?错了。
8 月 29 日,一个常规的负载均衡器更新将这个小问题变成了一个大问题。突然,在高峰时,16% 的 Sonnet 4 请求被发送到错误的服务器。而路由是“粘性”的。一旦你被错误路由,你就会继续被错误路由。
影响:
- 大约 30% 的 Claude Code 用户在此期间至少有一次请求被错误路由
- 受影响用户的响应时间直线下降
- 同一用户会反复遇到这个问题,而其他用户根本没有问题
Bug #2:随机字符生成器
8 月 25 日,Anthropic 部署了一个对其 TPU 服务器的错误配置。结果是 Claude 开始随机地在英语回复中插入泰语和中文字符。
想象一下,你要求 Claude 调试你的 Python 代码,然后你得到这样的回复:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price# <- 什么?
return ผลรวม
这影响了:
- Opus 4.1 和 Opus 4:8 月 25-28 日
- Sonnet 4:8 月 25 日 – 9 月 2 日
技术原因是一个令牌生成错误,它为不应该在那里的字符分配了高概率。它从根本上破坏了 Claude 选择下一个要说的话的机制。
Bug #3:不可见的编译器 Bug
这是一个从工程角度来说很可怕的问题。Google 的 XLA 编译器中有一个潜在的 Bug 一直处于休眠状态。当 Anthropic 在 8 月 25 日部署代码来改进令牌选择时,他们无意中触发了它。
这个 Bug 所做的事情从本质上来说是很奇怪的 – 它会导致 Claude 在生成文本时无意中排除最可能的令牌。Claude 知道正确的答案,但它被物理上阻止说出来。
真正令人沮丧的部分是?他们实际上在 2024 年 12 月已经绕过了这个 Bug,没有意识到这一点。当他们在 8 月“修复”了他们认为的根源时,他们删除了绕过方法并释放了真正的问题。
为什么需要六周时间来修复
你可能会想:像 Anthropic 这样的公司,拥有世界级的工程师,为什么需要六周时间来弄清楚这一点?
答案揭示了这些系统的复杂性:
1. 隐私控制阻止了调试
“我们的内部隐私和安全控制限制了工程师何时可以访问用户与 Claude 的交互,特别是当这些交互没有被报告为反馈时。”
他们从字面上来说无法看到是什么出了问题,除非用户明确地报告了它作为反馈。对隐私来说很好,对调试来说很糟糕。
2. Bug 自己隐藏了自己
Claude 经常从单个错误中恢复过来,使得退化看起来像正常的方差,而不是系统性的故障。他们的基准测试和评估没有捕捉到它,因为模型会自我纠正到足以通过测试的程度。
3. 多平台混乱
Claude 在 AWS Trainium、NVIDIA GPU 和 Google TPUs 上运行 – 三个完全不同的硬件平台。每个 Bug 在每个平台上表现出不同的症状:
- AWS Bedrock:0.18% 的 Sonnet 4 请求在峰值时受到影响
- Google Vertex AI:低于 0.0004% 受影响
- 直接 API:高达 16% 受影响
这使得它看起来像多个无关的问题,而不是三个特定的 Bug。
4. 重叠的症状
有三个 Bug 同时活跃,症状都很混乱。一个用户可能会得到泰语字符,另一个可能会得到降级的回复,第三个可能会看到完美的性能。没有明确的模式可以遵循。
这对 AI 可靠性意味着什么
这个故事揭示了当前 AI 系统的状态:它们比看起来更脆弱。
我们不仅仅在谈论 AI 模型本身。我们在谈论:
- 可以将请求发送到错误地方的路由基础设施
- 具有不同行为的硬件特定实现
- 可以休眠数月的编译器 Bug
- 可以将小问题放大为大型中断的负载均衡器
一个错误的配置,一个编译器 Bug,一个路由错误 – 然后你的 AI 助手忘记了如何编码或开始说它不应该说的话。
它是否真正被修复了?
Anthropic 说他们已经在 9 月 16 日解决了所有三个问题。他们:
- 修复了路由逻辑
- 回滚了有问题的配置
- 切换到近似到确切的 top-k 操作(为了准确性而牺牲性能)
- 添加了持续的生产监控
但是 用户仍然报告问题。一些开发人员声称 Claude Code 仍然感觉与之前的性能有所退化。无论是:
- Bug 的残留影响
- 尚未被识别的新问题
- 在数周的问题之后的心理偏见
- 实际的持续退化
…我们还不知道。
结论
这种情况是一个完美的案例研究,展示了复杂的 AI 系统如何以完全意外的方式失败。三个独立的 Bug,在几周内触发,造成了巨大的质量退化的感觉,需要六周时间来诊断和修复。
我们可以给 Anthropic 一些赞扬,因为他们的透明度。发布一份详细的技术事后分析比大多数公司做得更多。但这也表明了这些系统的潜在问题,我们越来越依赖它们。
对于任何在 Claude 或任何 LLM 之上构建的人:你需要冗余、验证和备份计划。因为正如我们刚刚看到的,即使是最好的 AI 系统也可能同时有三个问题,它可能需要数周时间才能弄清楚到底发生了什么。
支持这些 AI 模型的基础设施和模型本身一样重要。目前,这个基础设施显示出一些严重的成长痛苦。












