人工智能
模型路由器和反馈陷阱:AI 如何从自身学习
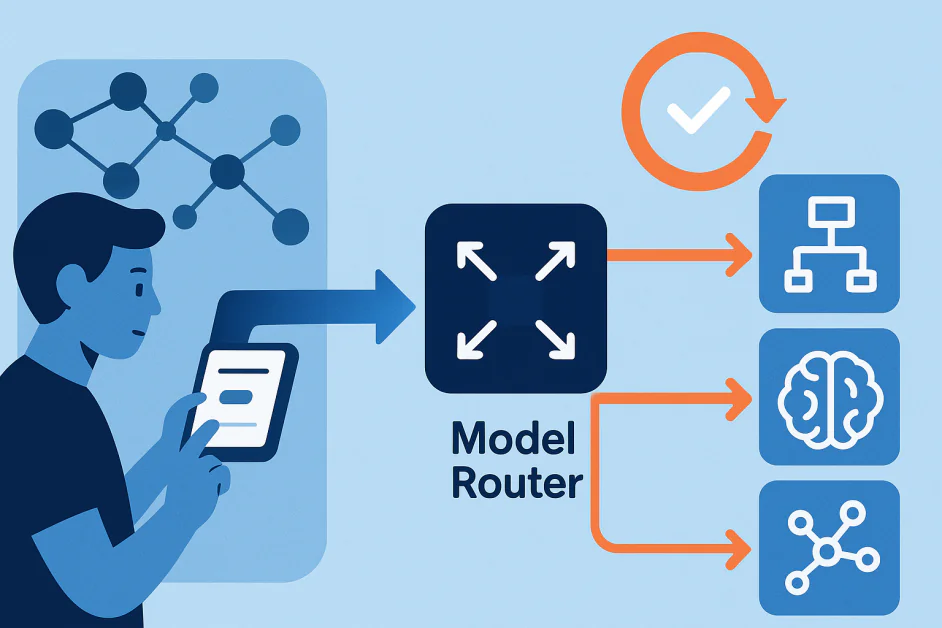
现代 AI 系统不再依赖单一模型来处理所有任务。相反,它们依赖于模型集合,每个模型都有特定的目的。模型路由器是这一设置中的核心组件,它解释用户的请求并决定哪个模型应该处理它。例如,在 OpenAI 的 GPT-5 系统中,路由器可能会将简单的查询发送到轻量级模型以提高速度,同时将复杂的推理任务路由到更高级的模型。
路由器不仅仅是流量管理器。它们从用户行为中学习,例如当用户在模型之间切换或偏爱某些答案时。这就形成了一个循环:路由器分配查询,模型产生答案,用户反应提供反馈,路由器更新其决策。当这些循环在后台默默地运行时,它们可能会形成隐藏的反馈循环。这些循环可能会放大偏见,强化有缺陷的模式,或者以难以检测的方式逐渐降低性能。
本文探讨了模型路由器的工作原理,反馈循环的形成,以及它们对 AI 系统的风险。
理解 AI 中的模型路由器
模型路由器是多模型 AI 系统中的决策层。其作用是确定哪个模型最适合任务。选择取决于诸如查询复杂性、用户意图、上下文以及成本、准确性和速度之间的权衡等因素。
与遵循固定规则的系统不同,大多数模型路由器都是机器学习系统本身。它们是使用真实世界信号训练的,并且会随着时间的推移而适应。它们可能会从用户行为中学习,例如在模型之间切换、评分答案或重新表述提示,以及从自动评估中学习,这些评估可以衡量输出质量。
这种适应性使得路由器变得强大,但也带来了风险。它们提高了效率并提供了更好的用户体验,但也可能创建出强化循环。随着时间的推移,这些循环不仅会影响路由策略,还会影响整个 AI 系统的行为。
反馈循环的形成
反馈循环发生在系统的输出影响了它后来学习的数据时。一个简单的例子是推荐系统:如果你点击一个体育视频,系统会向你展示更多的体育内容,这会影响你下一次观看的内容。随着时间的推移,系统会强化自己的模式。另一个例子是预测性执法。算法可能会预测某些社区的犯罪率更高,这可能会导致更多的巡逻。增加的巡逻会发现更多的事件,这反过来又会证实算法的预测。系统看起来是准确的,但数据是由其自身的影响而扭曲的。反馈循环可以是直接的或隐藏的。直接循环很容易识别,例如推荐系统在其自身的建议上重新训练。隐藏循环更为微妙,因为它们是当系统的不同部分间接地相互影响时产生的。
模型路由器也可以创建类似的循环。路由器的决策会影响哪个模型产生答案。答案会影响用户行为,这反过来又会成为路由器的反馈。随着时间的推移,路由器可能会开始强化过去有效的模式,而不是始终选择最好的模型。这些循环很难检测,并且可能会默默地将 AI 系统推向意想不到的方向。
为什么路由器中的反馈循环是有风险的
虽然反馈循环有助于路由器改进任务匹配,但它们也带来了风险,这些风险可能会扭曲系统的行为。一个风险是强化初始偏见。如果路由器反复将某种类型的查询发送到模型 A,大部分反馈将来自模型 A 的输出。路由器可能会假设模型 A 始终是最好的,边缘化模型 B,即使模型 B 有时可能表现更好。这种不平等的使用可能会自我强化。表现良好的模型会吸引更多的请求,这会强化它们的优势。使用较少的模型会获得较少的机会来改进,这会产生不平衡并降低多样性。
偏见也可能来自用于判断正确性的评估模型。如果“法官”模型有盲点,其偏见会直接传递给路由器,路由器然后会优化“法官”的价值观,而不是实际的用户需求。用户行为增加了另一个复杂性层次。如果路由器倾向于返回某种风格的答案,用户可能会适应他们的查询以匹配这些模式,从而进一步强化它们。随着时间的推移,这可能会同时狭窄用户行为和系统响应。路由器还可能会将某些查询模式或人口统计学特征与特定的模型相关联。这可能会导致不同群体之间系统地不同的体验,可能会强化和放大现有的社会偏见。
另一个关键问题是长期漂移。路由器今天所做的决定会影响明天使用的训练数据。如果模型是在路由器影响的输出上重新训练的,它们可能会学习路由器的偏好,而不是独立的方法。这可能会使模型之间的响应更加统一,并且会随着时间的推移而固化偏见。
打破循环的策略
减少隐藏循环的风险需要主动的设计和监督。训练应该使用多样化的数据源,而不是仅仅依赖于用户点击或切换。偶尔的随机路由也可以防止一个模型垄断某种任务类型。监控是必不可少的。定期的审计可以揭示路由器是否正在偏向某些模式或过度依赖单个模型。路由器决策的透明度有助于研究人员尽早检测偏见。
路由器还应定期使用新鲜、平衡的数据重新训练,以防止旧的偏见被锁定。特别是在敏感领域,加入人工监督增加了另一个责任层。人类可以识别出路由器是否系统地偏向某个模型或误分类某些查询。
关键是将路由器视为一个受到反馈影响的模型,而不是一个固定的或中立的组件。通过认识到路由器本身是如何受到其创建的数据的影响,研究人员和开发人员可以设计出在长期保持公平、适应性和可靠性的 AI 系统。
结论
模型路由器在效率和适应性方面提供了明显的优势,但它们也带来了隐藏的风险。这些系统中的反馈循环可能会默默地放大偏见,限制响应的多样性,并将模型锁定在狭窄的行为模式中。随着这些架构变得更加普遍,早期识别和解决这些风险将是构建保持公平、可靠和真正适应性的 AI 系统的关键。












