人工智能
Stable Diffusion 如何发展成为主流消费产品

Stable Diffusion,这个新型的AI图像合成框架,已经风靡全球,然而,它的名字却有些讽刺意味——它既不稳定,也不广泛应用——至少目前还不是这样。
Stable Diffusion 的全部功能被分散在各个开发者不断变化的众多版本中,这些开发者在 Discord 上的各种讨论中热烈地交换着最新的信息和理论。这些版本的安装程序离“插即用”还很远,反而需要通过命令行或 BAT 文件来安装,使用 GIT、Conda、Python、Miniconda 等前沿的开发框架——这些软件包在普通消费者中非常罕见,以至于它们的安装经常被防病毒和反恶意软件软件标记为潜在的系统安全威胁。

标准的 Stable Diffusion 安装过程中需要经过的几个阶段。许多发行版还需要特定的 Python 版本,这可能与用户机器上已安装的版本冲突——尽管可以通过 Docker 安装和 Conda 环境来一定程度上避免这个问题。
Stable Diffusion 的 SFW 和 NSFW 社区的消息线程中充满了关于如何修改 Python 脚本和标准安装以实现更好功能或解决依赖错误和其他问题的技巧和窍门。
这让普通消费者,对于那些希望使用 Stable Diffusion 从文本提示中创建惊人的图像的人来说,几乎完全依赖于日益增长的、商业化的 API 网页接口,大多数这些接口在提供少量免费图像生成后就需要购买代币。
此外,几乎所有这些基于 Web 的产品都拒绝输出 NSFW 内容(其中很多可能与非色情的普通话题有关,如“战争”),这使得 Stable Diffusion 与 OpenAI 的 DALL-E 2 的阉割服务有所区别。
‘Stable Diffusion 的 Photoshop’
被 Twitter 上 #stablediffusion 标签下每天出现的那些惊艳、诱人或超现实的图像所吸引,外界正在等待 ‘Stable Diffusion 的 Photoshop’ —— 一款集成了 Stability.ai 架构和 SD 开发社区的最佳、最强大的功能的跨平台应用程序,不需要浮动的命令行窗口、晦涩难懂的安装和更新程序,或缺失的功能。
我们目前拥有的,是大多数更强大的安装版本中,一个漂亮的网页界面,伴随着一个无形的命令行窗口,其 URL 是一个本地主机端口:

类似于 FaceSwap 和 BAT 驱动的 DeepFaceLab 等命令行驱动的合成应用,Stable Diffusion 的 ‘prepack’ 安装显示出其命令行根源,界面通过本地主机端口访问(见上图),与基于命令行的 Stable Diffusion 功能进行通信。
毫无疑问,更流线型的应用程序即将到来。已经有一些 Patreon 基础的整合应用程序可以下载,例如 GRisk 和 NMKD(见下图)——但还没有一个整合了 Stable Diffusion 更高级和更难以使用的实现所提供的全部功能范围。

早期的、Patreon 基础的 Stable Diffusion 包,轻度 ‘应用化’。NMKD 的是第一个将命令行输出直接集成到 GUI 中的应用。
让我们来看看一个更完善和整合的 Stable Diffusion 实现可能的样子——以及它可能面临的挑战。
商业化 Stable Diffusion 应用的法律考虑
NSFW 因素
Stable Diffusion 的源代码已在非常宽松的许可下发布,该许可不禁止商业重新实现和衍生作品,这些作品可以广泛地基于源代码构建。
除了众多 Patreon 基础的 Stable Diffusion 构建和为 Figma、Krita、Photoshop、GIMP 和 Blender 等开发的众多应用程序插件外,还没有 实际 的理由可以阻止一家资金充足的软件开发公司开发一个更复杂和功能更强大的 Stable Diffusion 应用程序。从市场角度来看,有理由相信,几项这样的计划已经在进行中。
这里,这样的努力立即面临着一个困境,即是否允许 Stable Diffusion 的本地 NSFW 过滤器(一个 代码片段)被关闭。
‘埋葬’ NSFW 开关
虽然 Stability.ai 为 Stable Diffusion 开源的许可包括一个可以广泛解释的应用列表, Stable Diffusion 可能 不 被用于这些应用(可能包括 色情内容 和 深度伪造),唯一能有效禁止此类使用的方法是将 NSFW 过滤器编译成一个不透明的可执行文件,而不是 Python 文件中的一个参数,或者强制执行包含 NSFW 指令的 Python 文件或 DLL 的校验和比较,以便在用户修改此设置时无法渲染。
这将使应用程序在很大程度上与 DALL-E 2 一样被“阉割”,从而降低其商业吸引力。另外,反编译和篡改这些组件(无论是原始的 Python 运行时元素还是现在 Topaz AI 图像增强工具中使用的编译 DLL 文件)的“改造”版本可能会在 torrent/黑客社区中出现,仅需通过替换阻碍这些限制的元素并否定任何校验和要求即可解锁此类限制。
最终,供应商可能会选择简单地重复 Stability.ai 在许多当前 Stable Diffusion 分发版的第一次运行中包含的对滥用的警告。
然而,目前使用这些警告的微小开源开发者与一家在使 Stable Diffusion 成为全功能和易用的应用程序上投入了大量时间和金钱的软件公司相比,风险要小得多,这引发了更深入的考虑。
深度伪造责任
如我们 最近指出,Stable Diffusion 的持续模型是在 4.2 亿张图像的 LAION 美学数据库上训练的,该数据库包含大量名人图像,允许用户有效地创建深度伪造,包括名人深度伪造色情图像。

来自我们最近的一篇文章,四个阶段的詹妮弗·康奈利在她职业生涯的四个十年中,从 Stable Diffusion 推断出来。
这是一个与生成(通常)合法的“抽象”色情图像(它不描绘“真实”的人,尽管这些图像是从训练材料中的多个真实照片推断出来的)不同的、更有争议的问题。
由于越来越多的美国州和国家正在制定或已经颁布了禁止深度伪造色情的法律,Stable Diffusion 创建名人色情的能力可能意味着一个不完全审查的商业应用程序可能需要某种方法来过滤被认为是名人面孔。
一种方法是提供一个内置的“黑名单”,其中包含不会被用户提示接受的词语,例如名人姓名和可能与他们相关的虚构人物。假设这些设置需要以多种语言(而不仅仅是英语)实施,因为原始数据包含其他语言。
另一种方法可能是整合名人识别系统,例如 Clarifai 开发的系统。
可能需要软件生产者整合此类方法,可能最初处于关闭状态,作为防止完全成熟的独立 Stable Diffusion 应用程序生成名人面孔的方式,直到可能使此功能成为非法的新立法出现。
然而,同样,如此功能最终可能会被反编译和逆向工程;然而,软件生产者可以在这种情况下声称,这基本上是未经授权的破坏——只要这种逆向工程不被过度简化。
可能包含的功能
任何 Stable Diffusion 分发版的核心功能都将被任何资金充足的商业应用程序所期望。这些功能包括使用文本提示生成图像的能力(文本到图像);使用草图或其他图像作为新生成图像的指导(图像到图像);调整系统被指示“想象力”的程度的方法;在渲染时间和质量之间进行权衡的方法;以及其他“基础”功能,例如可选的自动图像/提示存档,以及通过 RealESRGAN 进行的常规可选升级,以及至少基本的“面部修复”功能,使用 GFPGAN 或 CodeFormer。
这是一个相当“普通”的安装。让我们来看看一些目前正在开发或扩展的更高级功能,它们可以被集成到一个成熟的“传统”Stable Diffusion 应用程序中。
随机冻结
即使你 重用 前一次成功渲染的种子,如果 任何部分 的提示或源图像(或两者)在后续渲染中发生变化,那么要让 Stable Diffusion 准确地重复一个转换是非常困难的。
这是一个问题,如果你想使用 EbSynth 将 Stable Diffusion 的转换以时间上一致的方式强加于真实视频——尽管该技术对于简单的头肩部镜头可能非常有效:

有限的运动可以使 EbSynth 成为将 Stable Diffusion 转换变为真实视频的有效媒介。 来源:https://streamable.com/u0pgzd
EbSynth 通过将一小部分“修改”的关键帧外推到一个已经渲染成一系列图像文件的视频(稍后可以重新组装回视频)来工作。

在这个来自 EbSynth 网站的示例中,视频中的几个帧已以艺术方式绘制。EbSynth 使用这些帧作为样式向导,以类似的方式修改整个视频,使其与绘制的样式相匹配。 来源:https://www.youtube.com/embed/eghGQtQhY38
在下面的示例中,几乎没有任何运动, Stable Diffusion 仍然难以保持一致的面部,因为被转换为“关键帧”的三个图像并不完全相同,即使它们共享相同的数字种子。

在这里,即使使用相同的提示和种子用于所有三个转换,并且源帧之间变化很小,身体肌肉的大小和形状会有所不同,但更重要的是,面部是不一致的,这会阻碍潜在的 EbSynth 渲染的时间一致性。
虽然下面的 Stable Diffusion/EbSynth 视频非常有创意,用户的手指变成了(分别)一条穿着裤子的行走腿和一只鸭子,但不一致的裤子典型地表明了 Stable Diffusion 在保持不同关键帧之间的一致性方面存在的问题,即使源帧彼此相似,种子也保持一致。

一个人的手指变成了一个行走的腿和一只鸭子,通过 Stable Diffusion 和 EbSynth。 来源:https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
创建这个视频的用户 评论 说,鸭子转换(可以说是更有效的转换,尽管不那么引人注目和原创),只需要一个转换的关键帧,而要创建行走的裤子,需要渲染 50 个 Stable Diffusion 图像。用户还指出,需要五次尝试才能为每个关键帧实现一致性。
因此,对于一个真正全面的 Stable Diffusion 应用程序来说,提供一种保留特征的功能至关重要,以最大限度地跨关键帧保持一致性。
一种可能性是允许用户“冻结”每个帧的转换的随机编码,这目前只能通过手动修改源代码来实现。如下面的示例所示,这有助于时间一致性,尽管它当然没有完全解决这个问题:

一个 Reddit 用户通过不仅仅坚持使用相同的种子(任何 Stable Diffusion 实现都可以做到),而且确保每次转换的随机编码参数都相同,来将自己通过网络摄像头的画面转换成不同名人。这种方法是通过修改代码实现的,但可以轻松成为一个用户可访问的开关。显然,它并没有解决所有时间问题。 来源:https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
基于云的文本逆转
更好的解决方案是将它们“烘焙”到一个 文本逆转 中——一个可以在几小时内基于仅五个注释图像训练的 5KB 文件,然后可以通过特殊的 ‘*’ 提示来调用,允许例如在一个叙事中包含持续出现的新角色。

与相关标签关联的图像可以通过文本逆转转换为离散实体,并通过特殊的令牌单词在正确的上下文和风格中召唤出来。 来源:https://huggingface.co/docs/diffusers/training/text_inversion
文本逆转是 Stable Diffusion 使用的非常大且完全训练好的模型的附加文件,基本上是“注入”到提示/调用过程中,以便它们可以参与模型派生的场景,并从模型关于对象、风格、环境和交互的大型知识库中受益。
然而,虽然文本逆转的训练时间不长,但它需要大量的 VRAM;根据各种当前教程,需要大约 12、20,甚至 40GB。
由于大多数普通用户不太可能拥有如此强大的 GPU,因此已经出现了可以处理此操作的云服务,包括 Hugging Face 的版本。虽然有 Google Colab 实现 可以为 Stable Diffusion 创建文本逆转,但所需的 VRAM 和时间要求可能会使其对 Colab 免费层用户具有挑战性。
对于一个潜在的、全面的、资金充足的 Stable Diffusion(安装)应用程序,将此重任务转移到公司的云服务器似乎是一个明显的盈利策略(假设一个低成本或无成本的 Stable Diffusion 应用程序中包含此类非免费功能,这在可能从该技术中出现的许多应用程序中似乎很可能)。
此外,提交的图像和文本的复杂注释和格式化过程可能会从集成环境中受益。
多功能提示加权
有很多当前实现允许用户为长文本提示中的一个部分赋予更大的权重,但这些实现之间的工具性差异很大,且通常笨拙或不直观。
例如,AUTOMATIC1111 的 Stable Diffusion 分支可以通过将单词括在单个或多个括号(用于降低提示权重)或方括号(用于增加提示权重)中来降低或提高提示单词的值。

在这个 Stable Diffusion 提示权重版本中,方括号和/或括号可以改变你的早餐,但无论如何,这都是一个胆固醇噩梦。
其他 Stable Diffusion 版本使用感叹号来增加提示权重,而最通用的版本允许用户通过 GUI 为提示中的每个单词分配权重。
该系统还应允许 负面提示权重 —— 不仅仅是为了恐怖片迷,还因为 Stable Diffusion 的潜在空间中可能有比我们有限的语言可以召唤的更多令人着迷和更具启发性的秘密。
此外,系统应允许用户对提示中的某个部分赋予更大的权重。
外延绘画
Stable Diffusion 开源后不久,OpenAI 试图通过宣布“外延绘画”来夺回一些 DALL-E 2 的风头,这允许用户通过语义逻辑和视觉一致性将图像扩展到其边界之外。
当然,这也已在各种形式中为 Stable Diffusion 实现,包括 Krita 中,以及应该包含在一个全面、Photoshop 风格的 Stable Diffusion 版本中。
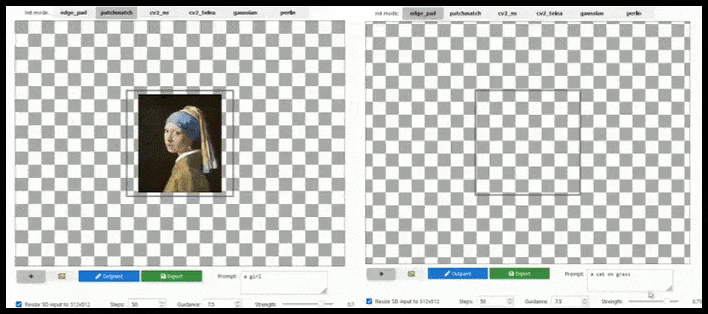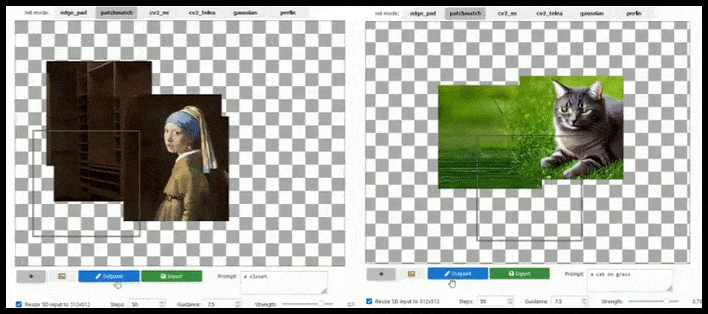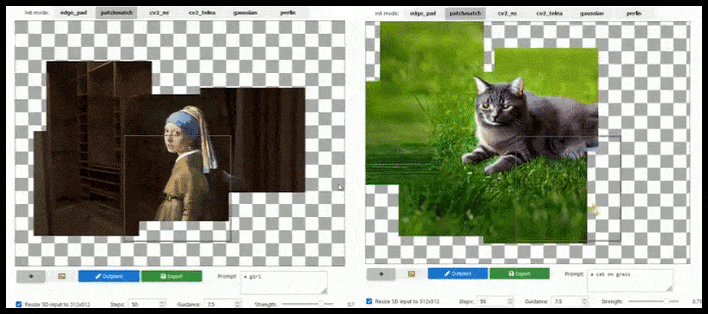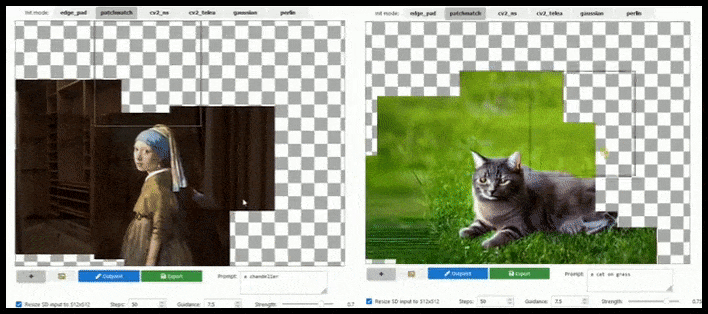
基于图块的增强可以在提示、现有图像和语义逻辑允许的情况下将标准 512×512 渲染几乎无限扩展。 来源:https://github.com/lkwq007/stablediffusion-infinity
由于 Stable Diffusion 是在 512x512px 图像上训练的(以及其他几个原因),它经常将人类主题的头部(或其他重要身体部位)切掉,即使提示明确指出“头部强调”等。

典型的 Stable Diffusion “斩首”示例;但外延绘画可以让乔治·克鲁尼重新回到画面中。
任何外延绘画实现都应作为一个单击/提示解决方案,用于解决此问题。
目前,许多用户通过扩展画布来“修复”被“斩首”的描绘,大致填充头部区域,然后使用 img2img 来完成渲染。
有效的上下文理解遮罩
遮罩可能是 Stable Diffusion 中非常困难的事情,具体取决于版本或分支。通常,遮罩在某种程度上是可能的,但指定的区域最终会被上下文不相关的内容填充。
在某个时候,我遮罩了一个人脸图像中的虹膜,并提供了“蓝眼睛”的提示作为遮罩填充——结果我似乎在看两个人类眼睛的剪切图,背景是一张超自然的狼图像。我猜我很幸运那不是弗兰克·辛纳特拉。
语义编辑也可以通过 识别构建图像的噪声 来实现,这允许用户在不干扰图像其余部分的情况下解决特定的结构元素:

在不使用传统遮罩和不改变相邻内容的情况下,通过识别最初生成图像的噪声并解决导致目标区域的噪声部分来更改图像中的一个元素。 来源:https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
这种方法基于 K-Diffusion 采样器。
生理错误的语义过滤器
正如我们之前提到的,Stable Diffusion 经常会添加或删除肢体,主要是由于训练数据问题和训练它的图像所附带的注释不足。

就像那个在集体照中把舌头伸出来的调皮孩子一样,Stable Diffusion 的生物学怪物并不总是立即显现,你可能已经在 Instagram 上发布了你的最新 AI杰作,然后才注意到额外的手或融化的肢体。
修复此类错误非常困难,因此,如果一个全面的 Stable Diffusion 应用程序包含某种解剖学识别系统,使用语义分割来计算传入图像是否具有严重的解剖学缺陷(如上图所示),并以用户无法看到的方式丢弃它,取而代之的是一个新的渲染,这将非常有用。

当然,你可能想要渲染女神卡利,或者博士奥克托普斯,或者甚至从肢体受损的图像中救出一个未受影响的部分,因此此功能应为可选切换。
如果用户能容忍遥测方面,如此失误甚至可以通过联邦学习的集体努力以匿名方式传输,这可能有助于未来的模型提高对解剖学逻辑的理解。
基于 LAION 的自动面部增强
正如我在对 Stable Diffusion 未来可能解决的三个挑战的 之前分析 中所指出的, Stable Diffusion 不应该仅仅依赖于 GFPGAN 来尝试“改进”渲染的面部。
GFPGAN 的“改进”是非常通用的,通常会破坏所描绘个人的身份,并且只对面部进行处理,面部在渲染过程中没有得到更多的处理时间或关注。
因此,一个专业标准的 Stable Diffusion 程序应该能够识别面部(使用一个标准且相对轻量的库,如 YOLO),并将可用的全部 GPU 力量用于重新渲染面部,然后将改进的面部融入原始的全上下文渲染中,或者将其单独保存以进行手动重新组合。目前,这是一个相当“手动”的操作。
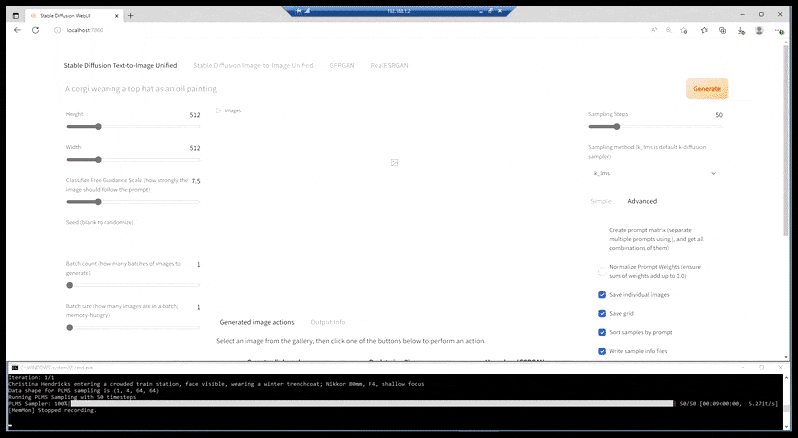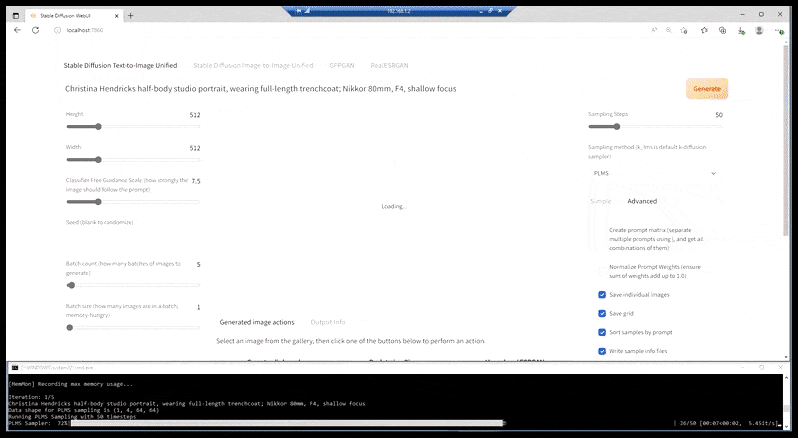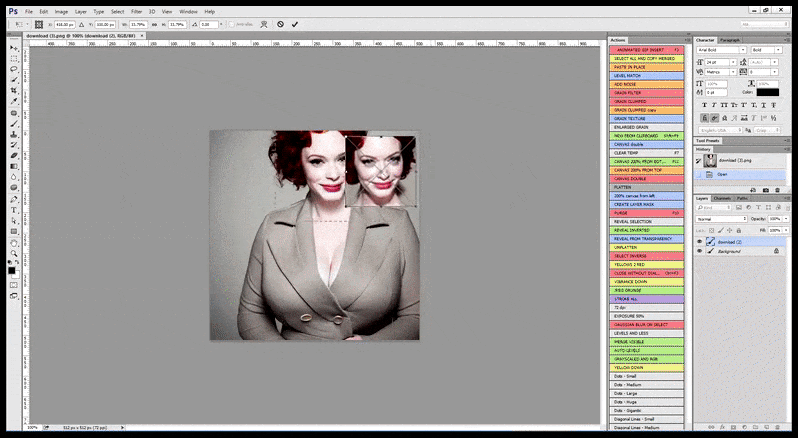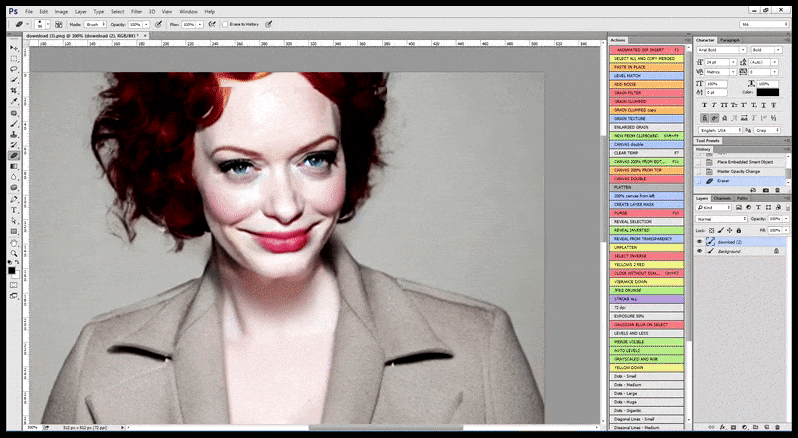
在 Stable Diffusion 已经在足够多的名人图像上进行了训练的情况下,完全可以专门使用 GPU 容量来渲染图像的面部,这通常是一个显著的改进——并且与 GFPGAN 不同的是,这是基于 LAION 训练数据,而不是简单地调整渲染的像素。
应用内 LAION 搜索
自从用户开始意识到搜索 LAION 的数据库可以帮助更好地使用 Stable Diffusion 以来,已经创建了几个在线 LAION 浏览器,包括 haveibeentrained.com。

haveibeentrained.com 的搜索功能允许用户探索为 Stable Diffusion 提供动力的图像,并发现他们可能希望从系统中唤起的对象、人物或想法是否可能被训练到其中。这样的系统也很有用,可以发现相邻实体,例如名人的聚类方式或从当前想法中产生的“下一个想法”。 来源:https://haveibeentrained.com/?search_text=bowl%20of%20fruit
虽然这样的 Web 基础数据库通常会显示图像中的一些标签,但模型训练过程中发生的 泛化 意味着不太可能通过使用其标签作为提示来召唤任何特定的图像。
此外,自然语言处理中的“停止词”和词干提取的去除意味着许多显示的短语在训练到 Stable Diffusion 之前已经被分割或省略。
然而,这些界面的美学分组可以教会最终用户很多关于 Stable Diffusion 的逻辑(或可以说是“个性”),并且可以帮助更好的图像生成。
结论
我希望在一个全面的本地桌面 Stable Diffusion 实现中看到的其他功能包括本地 CLIP 基础的图像分析,这反转了标准的 Stable Diffusion 过程,并允许用户从源图像中提取短语和单词,这些短语和单词系统自然会将其与源图像关联起来。
此外,真正的基于图块的缩放将是一个受欢迎的补充,因为 ESRGAN 几乎和 GFPGAN 一样笨拙。幸运的是,txt2imghd 中 GOBIG 实现的计划正在快速地在各个分发版中实现这一点,这似乎是一个明显的桌面迭代的选择。
其他一些受 Discord 社区欢迎的请求对我来说不那么有趣,例如集成的提示词典和适用的艺术家和风格列表,尽管应用内的笔记本或可自定义的短语词典似乎是一个合乎逻辑的补充。
同样,Stable Diffusion 中的人类中心动画的当前限制,尽管由 CogVideo 和其他项目启动,但仍然非常初步,并且依赖于人类运动的时间先验的上游研究。
就目前而言,Stable Diffusion 视频严格来说是 迷幻 的,尽管它可能在深度伪造木偶方面有一个更光明的近期未来,通过 EbSynth 和其他相对初生的文本到视频计划(值得注意的是,Runway 最新的宣传视频中没有合成或“修改”的人)。
另一个有价值的功能将是透明的 Photoshop 传递,早已在 Cinema4D 的纹理编辑器等类似实现中确立。通过此功能,可以轻松地在应用程序之间传递图像,并使用每个应用程序来执行它擅长的转换。
最后,也许最重要的是,一个全面的桌面 Stable Diffusion 程序应该不仅能够在检查点(即驱动系统的底层模型的版本)之间轻松切换,而且还应该能够更新自定义的文本逆转,这些逆转曾经适用于以前的官方模型版本,但可能会被后续模型版本破坏(正如官方 Discord 的开发人员所指出的那样)。
讽刺的是,处于创建此类强大和集成工具集的最佳位置的组织 Adobe,与 内容真实性倡议 联盟如此密切,以至于似乎这是一个令人遗憾的公关错误——除非它将 Stable Diffusion 的生成能力削弱得和 OpenAI 对 DALL-E 2 一样,并将其定位为其庞大的股票摄影持有量的自然演进。
最初发布于 2022 年 9 月 15 日。












