人工智能
代码嵌入:全面指南

代码嵌入是一种将代码片段表示为连续空间中的密集向量的变革性方法。这些嵌入捕获代码片段之间的语义和功能关系,实现了人工智能辅助编程中的强大应用。类似于自然语言处理(NLP)中的词嵌入,代码嵌入将相似的代码片段放在向量空间中靠近,使机器能够更有效地理解和操作代码。
什么是代码嵌入?
代码嵌入将复杂的代码结构转换为捕获代码含义和功能的数值向量。与传统方法不同,传统方法将代码视为字符序列,嵌入捕获代码各部分之间的语义关系。这对于各种人工智能驱动的软件工程任务至关重要,例如代码搜索、完成、错误检测等。
例如,考虑以下两个Python函数:
def add_numbers(a, b): return a + b
<p>def sum_two_values(x, y): result = x + y return result</p>
虽然这些函数在语法上看起来不同,但它们执行相同的操作。好的代码嵌入将以相似的向量表示这些两个函数,捕获它们的功能相似性,尽管它们的文本不同。

Vector Embedding
代码嵌入如何创建?
创建代码嵌入有不同的技术。一个常见的方法是使用神经网络从大量代码数据集中学习这些表示。网络分析代码结构,包括令牌(关键字、标识符)、语法(代码的结构)和潜在的注释,以学习代码片段之间的关系。
让我们分解这个过程:
- 代码作为序列:首先,代码片段被视为令牌(变量、关键字、运算符)序列。
- 神经网络训练:神经网络处理这些序列并学习将它们映射到固定大小的向量表示。网络考虑因素如语法、语义和代码元素之间的关系。
- 捕获相似性:训练的目标是将具有相似功能的代码片段(具有相似功能)放在向量空间中靠近。这使得任务如查找相似代码或比较功能成为可能。
以下是代码预处理的简化Python示例:
import ast
<p>def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# 添加更多节点类型,如有需要
return tokens</p>
<p># 示例用法
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# 输出:['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']</p>
这种标记化表示可以随后输入神经网络以进行嵌入。
现有的代码嵌入方法
现有的代码嵌入方法可以分为三大类:
基于令牌的方法
基于令牌的方法将代码视为词法令牌序列。像TF-IDF和深度学习模型(如CodeBERT)都属于这一类。
基于树的方法
基于树的方法将代码解析为抽象语法树(AST)或其他树结构,捕获代码的语法和语义规则。例如,树基于神经网络和像code2vec和ASTNN这样的模型。
基于图的方法
基于图的方法从代码中构造图,例如控制流图(CFG)和数据流图(DFG),以表示代码的动态行为和依赖关系。 GraphCodeBERT是一个值得注意的例子。
TransformCode:代码嵌入框架
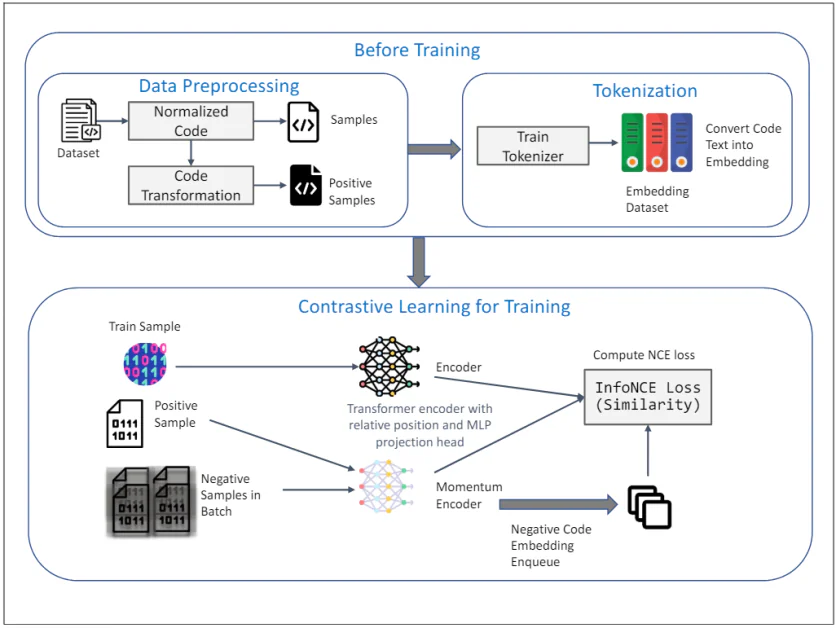
TransformCode:无监督代码嵌入学习
TransformCode是一个解决现有方法局限性的框架,它通过对比学习方式学习代码嵌入。它是编码器不可知的和语言不可知的,这意味着它可以利用任何编码器模型并处理任何编程语言。
上图说明了TransformCode框架的无监督代码嵌入学习使用对比学习的流程。它由两个主要阶段组成:训练前和训练的对比学习。以下是每个组件的详细解释:
训练前
1. 数据预处理:
- 数据集:初始输入是一个包含代码片段的数据集。
- 规范化代码:代码片段经过规范化以删除注释并将变量重命名为标准格式。这有助于减少变量命名对学习过程的影响,并提高模型的通用性。
- 代码转换:规范化的代码然后使用各种语法和语义转换来生成正样本。这些转换确保代码的语义含义保持不变,为对比学习提供了多样化和强大的样本。
2. 标记化:
- 训练标记器:一个标记器在代码数据集上进行训练,以将代码文本转换为嵌入。这涉及将代码分解为较小的单元,例如标记,可以被模型处理。
- 嵌入数据集:训练好的标记器用于将整个代码数据集转换为嵌入,这些嵌入作为对比学习阶段的输入。
训练的对比学习
3. 训练过程:
- 训练样本:从训练数据集中选择一个样本作为查询代码表示。
- 正样本:正样本是查询代码的转换版本,在数据预处理阶段获得。
- 批次中的负样本:负样本是批次中所有不同于正样本的代码样本。
4. 编码器和动量编码器:
- 带有相对位置和MLP投影头的Transformer编码器:查询和正样本都输入Transformer编码器。编码器包含相对位置编码以捕获代码中令牌之间的语法结构和关系。MLP投影头用于将编码表示映射到较低维度的空间中,在那里应用对比学习目标。
- 动量编码器:还使用动量编码器,它通过查询编码器参数的移动平均值更新。这种方法有助于保持表示的一致性和多样性,防止对比损失的崩溃。负样本使用此动量编码器编码并排队用于对比学习过程。
5. 对比学习目标:
- 计算InfoNCE损失(相似度):计算InfoNCE(噪声对比估计)损失,以最大化查询和正样本之间的相似度,同时最小化查询和负样本之间的相似度。这种目标确保学习到的嵌入是鉴别性的和强大的,捕获代码片段的语义相似度。
整个框架利用对比学习的优势,从无标签数据中学习有意义和强大的代码嵌入。使用AST转换和动量编码器进一步增强了学习表示的质量和效率,使TransformCode成为各种软件工程任务的强大工具。
TransformCode的关键特征
- 灵活性和适应性:可以扩展到各种下游任务,需要代码表示。
- 效率和可扩展性:不需要大型模型或大量训练数据,支持任何编程语言。
- 无监督和监督学习:可以应用于两种学习场景,通过纳入任务特定标签或目标。
- 可调参数:编码器参数的数量可以根据可用的计算资源进行调整。
TransformCode引入了一种称为AST转换的数据增强技术,应用语法和语义转换到原始代码片段。这种方法生成多样化和强大的样本用于对比学习。
代码嵌入的应用
代码嵌入通过将代码从文本格式转换为机器学习模型可用的数值表示,革新了软件工程的各个方面。以下是一些关键应用:
改进代码搜索
传统的代码搜索依赖于关键字匹配,通常会导致不相关的结果。代码嵌入使得语义搜索成为可能,代码片段根据其功能相似性进行排名,即使它们使用不同的关键字。这大大提高了在大型代码库中找到相关代码的准确性和效率。
更智能的代码完成
代码完成工具根据当前上下文建议相关的代码片段。通过利用代码嵌入,这些工具可以提供更准确和有用的建议,通过理解代码的语义含义,从而实现更快和更高效的编码体验。
自动代码纠正和错误检测
代码嵌入可以用来识别代码中经常指示错误或低效的模式。通过分析代码片段之间的相似性和已知错误模式,这些系统可以自动建议修复或突出可能需要进一步检查的区域。
增强代码摘要和文档生成
大型代码库通常缺乏适当的文档,使得新开发人员难以理解其工作原理。代码嵌入可以创建简洁的摘要,捕获代码的本质。这不仅提高了代码的可维护性,还促进了开发团队之间的知识转移。
改进代码审查
代码审查对于维护代码质量至关重要。代码嵌入可以通过突出潜在问题和建议改进来帮助审查者。此外,它们可以促进不同代码版本之间的比较,使审查过程更加高效。
跨语言代码处理
软件开发的世界并不局限于一种编程语言。代码嵌入为跨语言代码处理任务提供了希望。通过捕获不同语言中代码之间的语义关系,这些技术可以实现诸如代码搜索和分析等任务。












