人工智能
ChatGPT 首个周年纪念日:重塑 AI 交互的未来

回顾 ChatGPT 的第一年,我们可以清楚地看到这个工具已经极大地改变了 AI 的格局。ChatGPT 于 2022 年末推出,凭借其用户友好的、对话式风格,使得与 AI 交互感觉更像与人聊天,而不是与机器。这种新方法迅速吸引了公众的注意。在发布后仅五天,ChatGPT 就吸引了 100 万用户。到 2023 年初,这个数字迅速增加到约 1 亿月度用户,到 10 月,平台每月吸引了约 17 亿次访问。这些数字充分说明了其受欢迎程度和实用性。
过去一年中,用户发现了各种创造性的方法来使用 ChatGPT,从简单的任务如撰写电子邮件和更新简历到创办成功的企业。但这不仅仅是关于人们如何使用它;技术本身也在不断发展和改进。最初,ChatGPT 是一个免费服务,提供详细的文本响应。现在,有了 ChatGPT Plus,它包括 ChatGPT-4。这一更新版本是在更多数据上训练的,给出更少的错误答案,并更好地理解复杂指令。
其中一个最大的更新是 ChatGPT 现在可以通过多种方式交互——它可以听、说,甚至处理图像。这意味着您可以通过其移动应用程序与其交谈,并向其展示图片以获得响应。这些变化为 AI 开启了新的可能性,并改变了人们对 AI 在我们生活中作用的看法和思考方式。
从最初的技术演示到现在成为科技界的重要角色,ChatGPT 的旅程非常令人印象深刻。最初,它被视为一种通过从公众获取反馈来测试和改进技术的手段。但很快,它就成为 AI 景观中的一个重要组成部分。这种成功表明,通过监督学习和人类反馈来微调大型语言模型(LLM)是多么有效。因此,ChatGPT 可以处理广泛的问答和任务。
开发最具能力和多功能的 AI 系统的竞争导致了开放源码和专有模型(如 ChatGPT)的激增。要了解它们的一般能力,需要在广泛的任务范围内进行综合基准测试。这一部分探讨了这些基准测试,阐明了不同模型(包括 ChatGPT)如何相互比较。
评估 LLM:基准测试
- MT-Bench:该基准测试评估多轮对话和指令遵循能力,跨八个领域:写作、角色扮演、信息提取、推理、数学、编码、STEM 知识和人文/社会科学。更强大的 LLM,如 GPT-4,被用作评估者。
- AlpacaEval:基于 AlpacaFarm 评估集,该 LLM 基准测试自动评估模型,与 GPT-4 和 Claude 等高级 LLM 的响应进行比较,计算候选模型的胜率。
- 开放 LLM 排行榜:利用语言模型评估工具包,该排行榜在七个关键基准测试中评估 LLM,包括推理挑战和常识测试,在零次和少次设置中。
- BIG-bench:该协作基准测试涵盖了 200 多项新语言任务,跨越多种主题和语言。其目标是探测 LLM 并预测其未来的能力。
- ChatEval:一个多代理辩论框架,允许团队自主讨论和评估不同模型在开放式问题和传统自然语言生成任务中的响应质量。
比较性能
在一般基准测试中,开放源码 LLM 已经取得了显著的进步。例如,Llama-2-70B 在指令数据上进行微调后,取得了令人印象深刻的结果,特别是在 AlpacaEval 中,其胜率达到 92.66%,超过了 GPT-3.5-turbo。然而,GPT-4 仍然是领跑者,其胜率达到 95.28%。
Zephyr-7B,一个较小的模型,在 AlpacaEval 和 MT-Bench 中展示了与更大型 70B LLM 相似的能力。同时,WizardLM-70B 在指令数据上进行微调后,在 MT-Bench 中获得了最高分,超过了 GPT-3.5-turbo 和 GPT-4。
扩大规模:巨型 LLM 的崛起
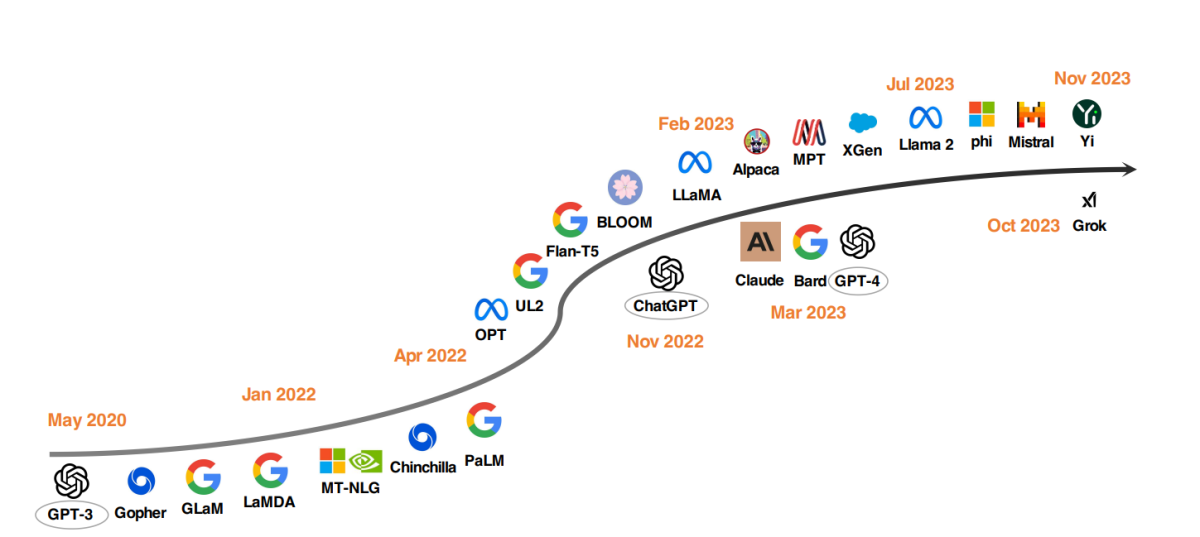
自 2020 年以来最顶尖的 LLM 模型
LLM 开发中的一个显著趋势是模型参数的扩大。像 Gopher、GLaM、LaMDA、MT-NLG 和 PaLM 这样的模型已经突破了界限,创造了高达 540 亿参数的模型。这些模型展示了卓越的能力,但由于其闭源性质,限制了它们的更广泛应用。这一限制激发了人们对开发开放源码 LLM 的兴趣,这一趋势正在增强。
ChatGPT 催化剂
OpenAI 的 ChatGPT 介绍标志着 NLP 研究的一个转折点。为了与 OpenAI 竞争,像 Google 和 Anthropic 这样的公司推出了自己的模型,分别是 Bard 和 Claude。虽然这些模型在许多任务中表现出与 ChatGPT 相似的性能,但它们仍然落后于 OpenAI 最新的模型 GPT-4。这些模型的成功主要归因于从人类反馈中进行强化学习(RLHF),这是一种正在受到越来越多研究关注的技术,以期进一步改进。
关于 OpenAI 的 Q*(Q-Star)的传闻和猜测
最近的报道表明,OpenAI 的研究人员可能已经在 AI 领域取得了重大进展,开发了一种名为 Q*(发音为 Q 星)的新模型。据称,Q* 具有执行小学水平数学运算的能力,这一壮举引发了专家们关于其作为人工通用智能(AGI)里程碑的潜力的讨论。虽然 OpenAI 没有对这些报道发表评论,但 Q* 的传闻能力已经在社交媒体和 AI 爱好者中引起了很大的兴奋和猜测。
Q* 的开发值得注意,因为现有的语言模型,如 ChatGPT 和 GPT-4,虽然能够执行一些数学任务,但并不是特别擅长可靠地处理它们。挑战在于,AI 模型不仅需要识别模式(如当前通过深度学习和转换器所做的),还需要推理和理解抽象概念。数学作为推理的基准,需要 AI 计划和执行多个步骤,展示对抽象概念的深刻理解。这一能力将标志着 AI 能力的重大飞跃,可能超越数学,延伸到其他复杂任务。
开放源码 LLM 运动
为了促进开放源码 LLM 研究,Meta 发布了 Llama 系列模型,引发了一波基于 Llama 的新发展潮流。这包括使用指令数据对模型进行微调的模型,如 Alpaca、Vicuna、Lima 和 WizardLM。研究还扩展到增强代理能力、逻辑推理和长上下文建模等领域,均在 Llama 框架内进行。
ChatGPT 和开放源码模型在医疗保健中的影响
我们正在展望一个未来,LLM 将在临床笔记记录、报销表格填写以及支持医生进行诊断和治疗规划等方面提供帮助。这已经吸引了科技巨头和医疗机构的注意。
Microsoft 与 Epic(一家领先的电子健康记录软件提供商)的讨论标志着 LLM 将被整合到医疗保健领域。UC San Diego Health 和 Stanford University Medical Center 已经启动了相关计划。同样,Google 与 Mayo Clinic 的合作以及 Amazon Web Services 推出的 HealthScribe(一种 AI 临床文档服务)标志着这一领域的重大进步。












