AI 模型与平台
Auto-GPT & GPT-Engineer:对当今领先的AI代理的深入指南

当比较ChatGPT与Auto-GPT和GPT-Engineer等自治AI代理时,决策过程中存在显著差异。虽然ChatGPT需要积极的人类参与来驱动对话,根据用户提示提供指导,但规划过程主要依赖于人类干预。
像变压器这样的生成式AI模型是这些自治AI代理的核心技术,训练在大型数据集上,使其能够模拟复杂的推理和决策能力。
自治代理的开源根源:Auto-GPT和GPT-Engineer
许多自治AI代理源自开源计划,由创新个人领导,改变传统工作流程。与提供建议不同,像Auto-GPT这样的代理可以独立处理任务,从在线购物到构建基本应用程序。
Auto-GPT和GPT-Engineer都具有GPT 3.5和GPT-4的能力,理解代码逻辑,合并多个文件,并加速开发过程。
Auto-GPT的核心功能在于其AI代理,这些代理被编程为执行特定任务,从日常任务到需要战略决策的复杂任务。然而,这些AI代理在用户设定的边界内运行。通过控制API访问,用户可以确定AI可以执行的操作范围和深度。
例如,如果任务是创建一个集成ChatGPT的聊天网页应用,Auto-GPT会自主地将目标分解为可执行的步骤,如创建HTML前端或Python后端。虽然应用程序自主生成这些提示,但用户仍可以监控和修改它们。
https://twitter.com/SigGravitas/status/1642181498278408193
以下图表描述了一个更一般的自治AI代理架构,提供了对幕后过程的宝贵见解。

自治AI代理架构
该过程从验证OpenAI API密钥和初始化参数开始,包括短期内存和数据库内容。一旦密钥数据传递给代理,模型与GPT3.5/GPT4交互以获取响应。该响应然后转换为JSON格式,代理解释以执行各种功能,如进行在线搜索、读写文件或运行代码。Auto-GPT使用预训练模型存储这些响应,并在未来交互中使用这些信息作为参考。循环继续,直到任务被认为是完成的。
Auto-GPT和GPT-Engineer的设置指南
设置像GPT-Engineer和Auto-GPT这样的尖端工具可以简化您的开发过程。以下是结构化的指南,帮助您安装和配置这两个工具。
Auto-GPT
设置Auto-GPT可能看起来复杂,但有了正确的步骤,它就变得简单明了。本指南涵盖了设置Auto-GPT的程序,并提供了对其多样化场景的见解。
1. 先决条件:
- Python环境: 确保您已安装Python 3.8或更高版本。您可以从其官方网站获取Python。
- 如果您计划克隆存储库,请安装Git。
- OpenAI API密钥: 与OpenAI交互需要API密钥。从您的OpenAI帐户获取密钥

Open AI API密钥生成
内存后端选项: 内存后端作为AutoGPT的存储机制,用于访问其操作所需的基本数据。AutoGPT使用短期和长期存储能力。Pinecone、Milvus、Redis等都是可用的选项。
2. 设置您的工作空间:
- 创建虚拟环境:
python3 -m venv myenv - 激活环境:
- MacOS或Linux:
source myenv/bin/activate
- MacOS或Linux:
3. 安装:
- 克隆Auto-GPT存储库(确保您已安装Git):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - 要使用Auto-GPT的0.2.2版本,请检查出该版本:
git checkout stable-0.2.2 - 导航到下载的存储库:
cd Auto-GPT - 安装所需依赖项:
pip install -r requirements.txt
4. 配置:
- 在主目录中找到
.env.template,复制并重命名为.env - 打开
.env,并在OPENAI_API_KEY=后设置您的OpenAI API密钥 - 类似地,要使用Pinecone或其他内存后端,请在
.env文件中更新Pinecone API密钥和区域。
5. 命令行指令:
Auto-GPT提供了一组丰富的命令行参数来定制其行为:
- 一般用法:
- 显示帮助:
python -m autogpt --help - 调整AI设置:
python -m autogpt --ai-settings <filename> - 指定内存后端:
python -m autogpt --use-memory <memory-backend>
- 显示帮助:

AutoGPT CLI
6. 启动Auto-GPT:
一旦配置完成,使用以下命令启动Auto-GPT:
- Linux或Mac:
./run.sh start - Windows:
.run.bat
Docker集成(推荐设置方法)
对于那些希望容器化Auto-GPT的人,Docker提供了一种简化的方法。然而,Docker的初始设置可能会稍微复杂一些。请参考Docker的安装指南以获取帮助。
按照以下步骤修改OpenAI API密钥。确保Docker在后台运行。现在,转到AutoGPT的主目录,并在终端中按照以下步骤进行操作
- 构建Docker镜像:
docker build -t autogpt . - 现在运行:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
使用docker-compose:
- 运行:
docker-compose run --build --rm auto-gpt - 对于额外的自定义,您可以集成其他参数。例如,要运行带有–gpt3only和–continuous的参数:
docker-compose run --rm auto-gpt --gpt3only--continuous - 鉴于Auto-GPT从大型数据集生成内容的广泛自治性,存在潜在风险,即它可能会无意中访问恶意的Web源。
为了减轻风险,请在虚拟容器中运行Auto-GPT,例如Docker。这确保任何潜在的有害内容都被限制在虚拟空间内,而您的外部文件和系统保持不受影响。或者,Windows沙盒也是一个选项,尽管它在每个会话后都会重置并且无法保留其状态。
为了安全,请始终在虚拟环境中执行Auto-GPT,以确保您的系统免受意外输出的影响。
尽管如此,仍然有可能您无法获得预期的结果。Auto-GPT用户报告了在尝试写入文件时遇到的反复出现的问题,通常会遇到由于文件名有问题而导致的尝试失败。以下是这样的一个错误:Auto-GPT(版本0.2.2)不追加文本,错误“write_to_file返回:错误:文件已经更新”
各种解决方案已在相关的GitHub线程中进行了讨论,以供参考。
GPT-Engineer
GPT-Engineer工作流程:
- 提示定义: 使用自然语言编写项目的详细描述。
- 代码生成: 根据您的提示,GPT-Engineer生成代码片段、函数,甚至完整的应用程序。
- 改进和优化: 生成后,总是有改进的余地。开发人员可以修改生成的代码以满足特定的要求,确保质量最佳。
设置GPT-Engineer的过程已被浓缩成一个易于遵循的指南。以下是逐步分解:
1. 准备环境: 在开始之前,请确保您已准备好项目目录。打开终端并运行以下命令
- 创建一个名为“网站”的新目录:
mkdir website- 转到目录:
cd website
2. 克隆存储库: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. 导航和安装依赖项: 克隆后,切换到目录 cd gpt-engineer 并安装所有必要的依赖项 make install
4. 激活虚拟环境: 根据您的操作系统,激活创建的虚拟环境。
- 对于 macOS/Linux:
source venv/bin/activate
- 对于 Windows,由于API密钥设置,它略有不同:
set OPENAI_API_KEY=[your api key]
5. 配置 – API密钥设置: 要与OpenAI交互,您需要API密钥。如果您尚未拥有,请在OpenAI平台上注册,然后:
- 对于 macOS/Linux:
export OPENAI_API_KEY=[your api key]
- 对于 Windows(如前所述):
set OPENAI_API_KEY=[your api key]
6. 项目初始化和代码生成: GPT-Engineer的魔力从 main_prompt 文件开始,该文件位于 projects 文件夹中。
- 如果您想启动一个新项目:
cp -r projects/example/ projects/website
用您选择的项目名称替换“网站”。
- 使用文本编辑器编辑
main_prompt文件,编写项目的要求。

- 一旦您对提示感到满意,请运行:
gpt-engineer projects/website
您的生成代码将位于项目文件夹中的 workspace 目录中。
7. 生成后: 虽然GPT-Engineer很强大,但它可能并不总是完美。检查生成的代码,如果需要,请进行手动更改,并确保一切顺利运行。
示例运行
提示:
“我想开发一个基本的Streamlit应用程序,使用Python来可视化用户数据,通过交互式图表。该应用程序应允许用户上传CSV文件,选择图表类型(例如,条形,饼图,线图),并动态可视化数据。它可以使用Pandas进行数据操作和Plotly进行可视化。”
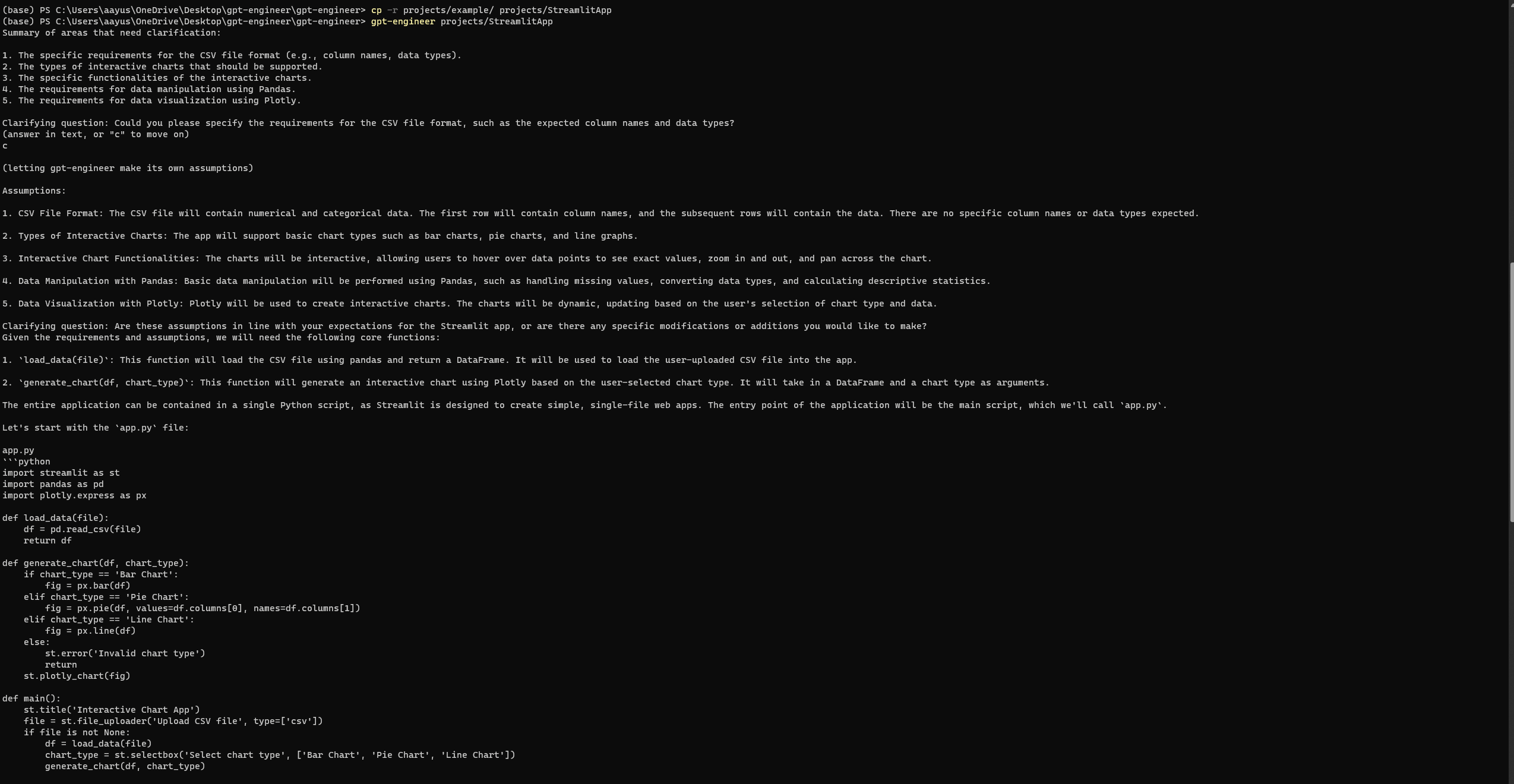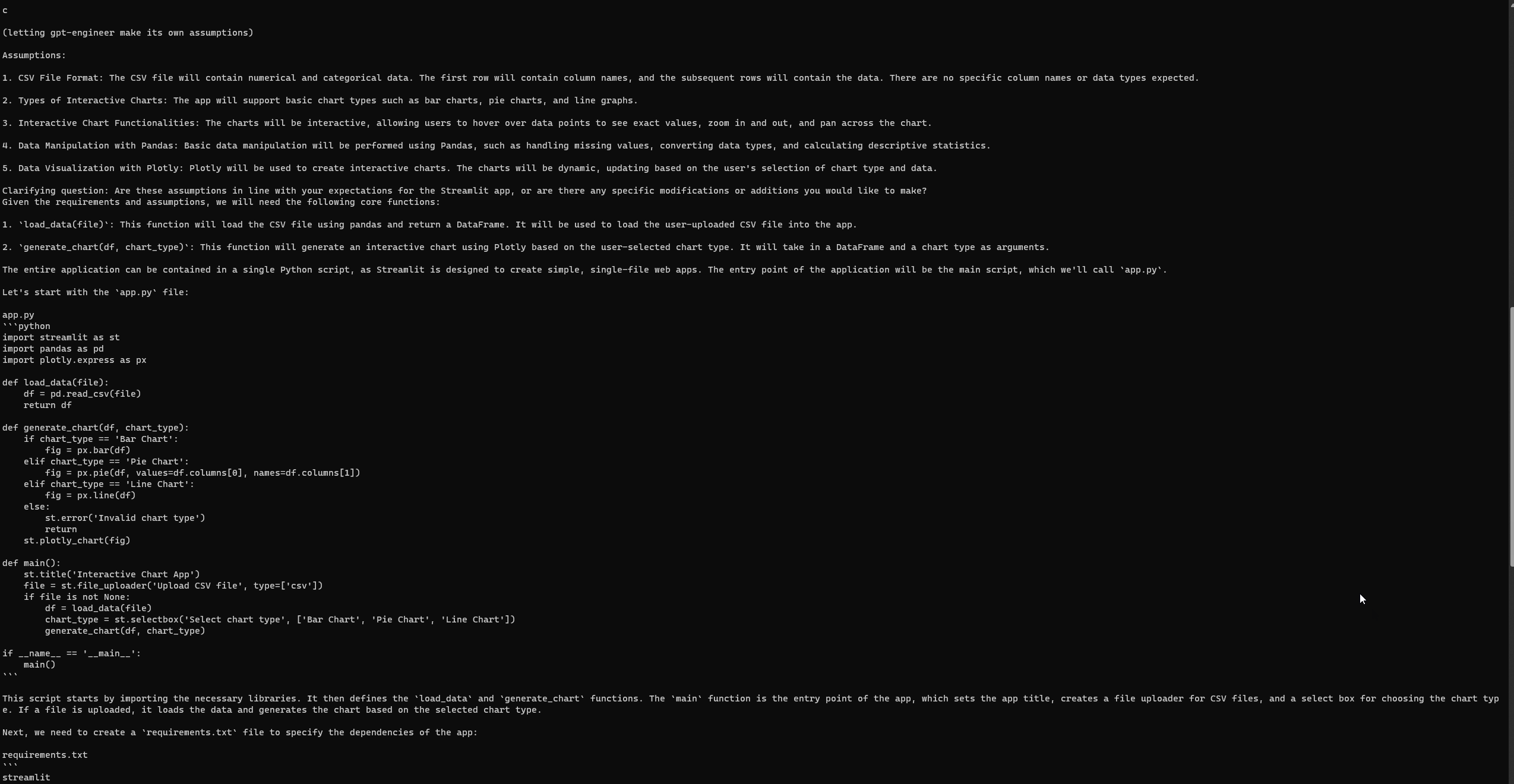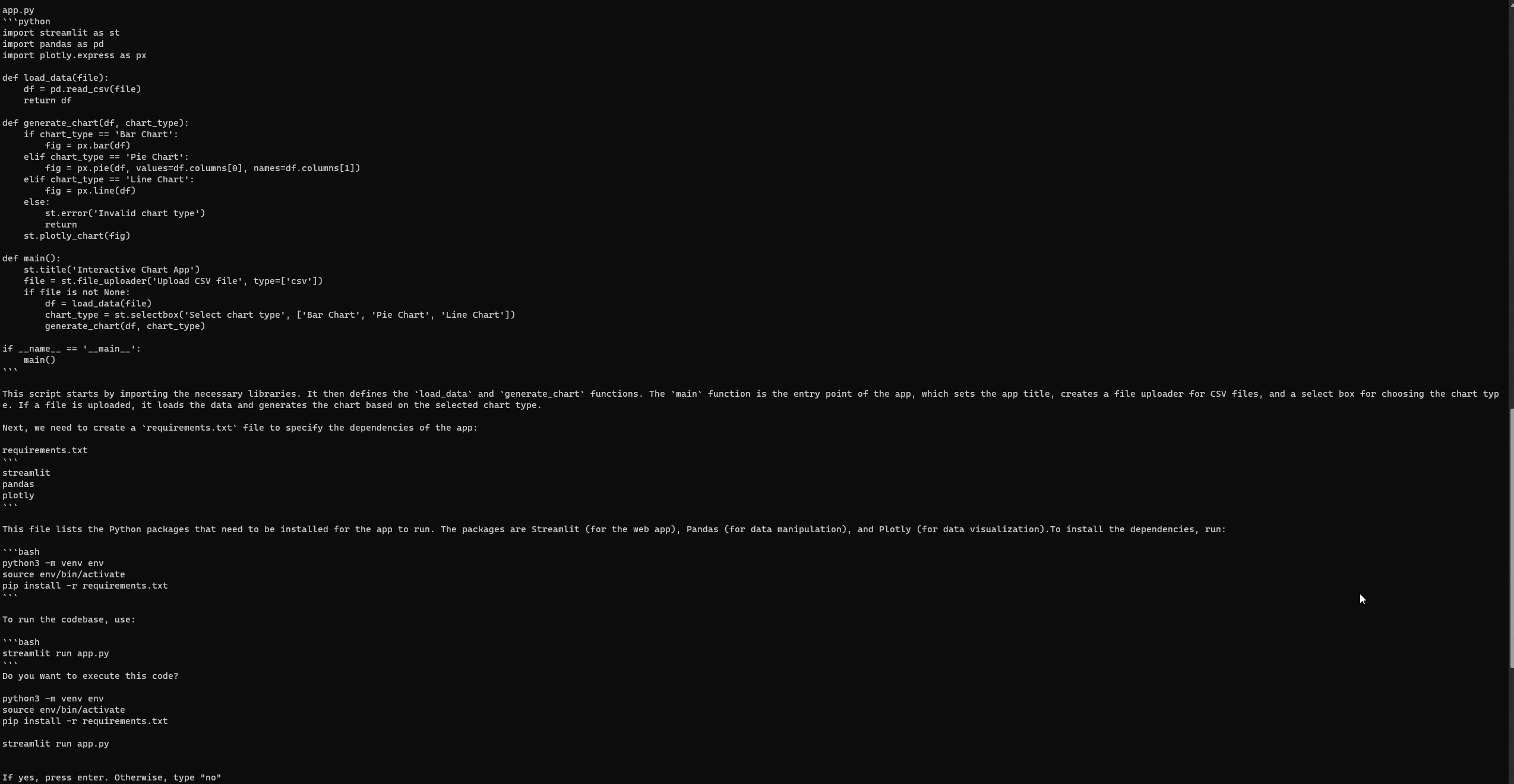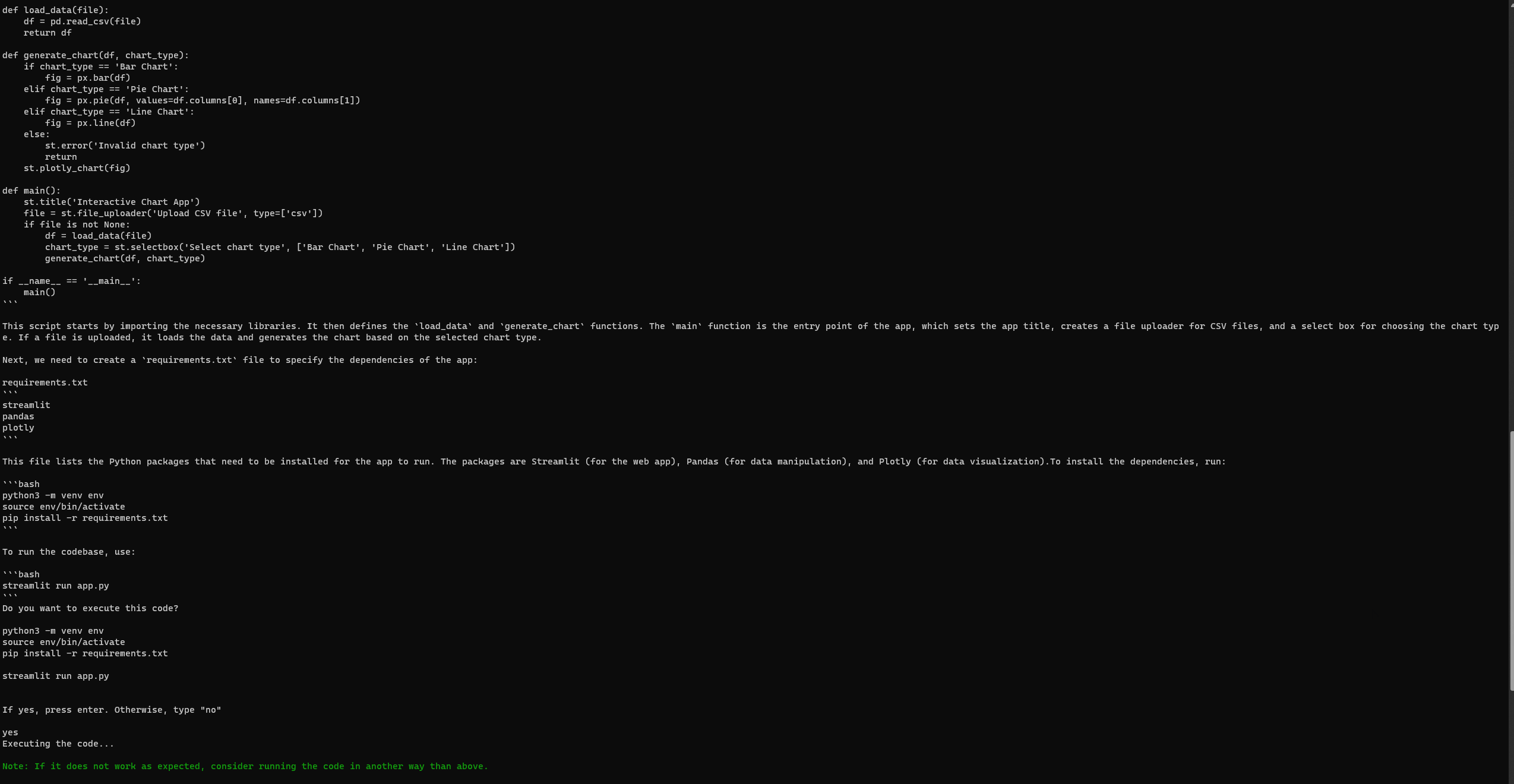
设置和运行GPT-Engineer
与Auto-GPT类似,GPT-Engineer有时也会遇到错误,即使设置完成。然而,在我的第三次尝试中,我成功访问了以下Streamlit网页。请确保您查看了官方 GPT-Engineer存储库的问题页面 中的任何错误。

使用GPT-Engineer生成的Streamlit应用程序
AI代理的当前瓶颈
运营费用
Auto-GPT执行的一个任务可能涉及多个步骤。重要的是,每个步骤都可能单独计费,增加成本。Auto-GPT可能陷入重复循环,无法交付承诺的结果。这种情况损害了其可靠性,并破坏了投资。
想象一下,您想使用Auto-GPT创建一篇短篇文章,文章的理想长度为8K令牌。在创建过程中,模型可能会深入多个中间步骤来完成内容。如果您使用GPT-4,具有8K上下文长度,则对于输入,您将被收取 $0.03 的费用。对于输出,成本将为 $0.06。现在,假设模型遇到一个意外的循环,多次重复某些部分。不仅过程变长了,每次重复也会增加成本。
为了防止这种情况:
设置使用限制 在OpenAI Billing & Limits:
- 硬限制:限制使用超过您的设置阈值。
- 软限制:当阈值达到时向您发送电子邮件警报。
功能限制
Auto-GPT的功能,如其源代码所示,具有某些限制。其问题解决策略由其固有函数和GPT-4 API提供的可访问性所管理。有关更深入的讨论和可能的解决方法,请考虑访问:Auto-GPT讨论。
AI对劳动力市场的影响
AI与劳动力市场之间的动态关系正在不断演变,并在这篇 研究论文 中有详细的记录。一个关键的收获是,虽然技术进步通常会使熟练工人受益,但它也会对从事常规任务的工人构成风险。事实上,技术进步可能会取代某些任务,但同时也会为多样化的劳动密集型任务铺平道路。

据估计,80%的美国工人可能会发现LLM(语言学习模型)会影响他们每日任务的10%。这一统计数据凸显了AI和人类角色之间的融合。
AI在工作中的双重角色:
- 积极方面:AI可以自动执行许多任务,从客户服务到财务建议,为小型企业提供缓解,这些企业缺乏资金来组建专门的团队。
- 担忧:自动化的好处引发了人们对潜在工作岗位流失的担忧,特别是在需要人类参与的领域,例如客户支持。与此同时,还有与AI访问机密数据相关的伦理困境。这需要一个强大的基础设施,以确保透明度、问责制和AI的道德使用。
结论
显然,像ChatGPT、Auto-GPT和GPT-Engineer这样的工具站在技术与其用户之间交互关系的变革前沿。这些AI代理具有开源运动的根源,体现了机器自主性的可能性,简化了从调度到软件开发的任务。
当我们步入一个AI更深入地融入我们日常生活的未来时,平衡AI的能力与保护人类角色的平衡变得至关重要。在更广泛的范围内,AI与劳动力市场的动态呈现出增长机会和挑战的双重图景,需要技术伦理和透明度的有意识整合。












