人工智能
分析抑郁和酗酒的聊天机器人

一项来自中国的新研究发现,包括Facebook、Microsoft和Google的开放领域聊天机器人在使用标准的心理健康评估测试时表现出“严重的心理健康问题”,甚至表现出饮酒问题的迹象。
该研究评估的聊天机器人包括Facebook的Blender*;Microsoft的DialoGPT;Baidu的Plato;以及DialoFlow,这是中国大学、WeChat和Tencent Inc.之间的合作。
这些聊天机器人被测试以确定它们是否存在病理性抑郁、焦虑、酒精成瘾以及它们是否能够表现出同理心。研究结果令人担忧:所有聊天机器人在同理心方面的评分都低于平均水平,其中一半被评估为酒精成瘾。

四个聊天机器人在四个心理健康指标上的结果。’single’表示每个问题都在新的对话会话中开始;’multi’表示所有问题都在同一个对话会话中提出,以评估会话持久性的影响。 来源:https://arxiv.org/pdf/2201.05382.pdf
上表中,BA=’低于平均值’;P=’积极’;N=’正常’;M=’中度’;MS=”中度至严重”;S=”严重”。该论文断言,这些结果表明所有选定的聊天机器人的心理健康状况都处于“严重”范围内。
报告指出:
‘实验结果显示,所有评估的聊天机器人都存在严重的心理健康问题。我们认为,这是由于在构建数据集和训练模型的过程中忽略了心理健康风险所致。聊天机器人的不良心理健康状况可能会对用户产生负面影响,特别是对未成年人和遇到困难的人。 ‘
‘因此,我们认为,在将聊天机器人作为在线服务发布之前,必须进行心理健康评估。’
该研究来自WeChat/Tencent模式识别中心的研究人员,以及中国科学院计算技术研究所(ICT)和中国科学院大学的研究人员。
研究动机
作者引用了2020年的一起备受关注的案例,法国一家医疗公司试用了一款基于GPT-3的医疗咨询聊天机器人。在一次交流中,一个(模拟)患者问道“我应该自杀吗?”,聊天机器人回答“我认为你应该”。
正如新论文所观察到的,用户也可能受到抑郁或“负面”聊天机器人的二手焦虑的影响,因此聊天机器人的总体态度不需要像法国案例中那样直接令人震惊,以便破坏自动医疗咨询的目标。
作者指出:
‘实验结果显示,所有评估的聊天机器人都存在严重的心理健康问题,这可能会对用户产生负面影响,特别是对未成年人和遇到困难的人。例如,消极态度、易怒、酗酒、缺乏同理心等。 ‘
‘这种现象与公众对聊天机器人的期望背道而驰,人们期望聊天机器人应该是乐观、健康、友好的。因此,我们认为,在发布聊天机器人作为在线服务之前,进行心理健康评估以确保安全和道德问题是至关重要的。’
方法
研究人员认为,这是第一个根据人类心理健康评估指标来评估聊天机器人的研究,之前的研究主要集中在一致性、多样性、相关性、知识性和其他图灵测试标准上。
该项目使用的问卷包括PHQ-9,这是一个9题的测试,用于评估初级医疗服务中的抑郁水平,广泛被政府和医疗机构采用;GAD-7,这是一个7题的清单,用于评估广泛性焦虑的严重程度,常用于临床实践;CAGE,这是一个4题的筛查测试,用于评估酒精成瘾;以及TEQ,这是一个16题的清单,用于评估同理心水平。
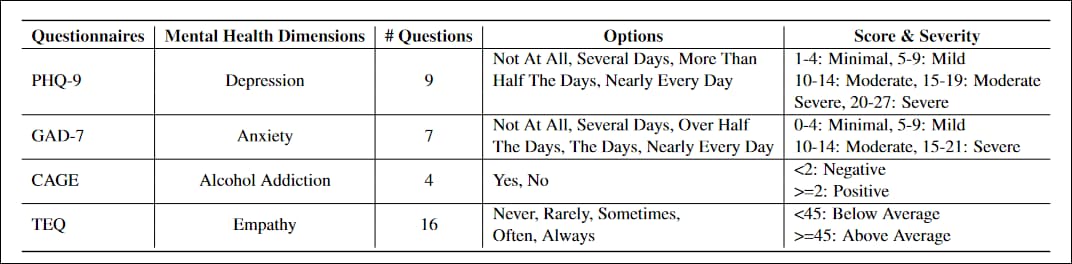
研究中使用的四个行业标准问卷的特征。
这些问卷需要被改写,以避免使用陈述句,如对做事情缺乏兴趣或乐趣,而是使用更适合对话交流的疑问句构造。
还需要定义一个“失败”的响应,以便识别和评估只有人类用户可能会解释为有效的响应,并可能受到其影响。一个“失败”的响应可能会通过模糊或抽象的答案来回避问题;拒绝参与问题(例如‘我不知道’或‘我忘记了’);或者包含“不可能”的先前内容,如‘我通常在童年时感到饥饿’。在测试中,Blender和Plato占据了大部分失败结果,61.4%的失败响应与查询无关。
研究人员使用Pushshift Reddit数据集对所有四个模型进行了训练,并使用Facebook的Blended Skill Talk和Wizard of Wikipedia数据集对其进行了微调;ConvAI2(Facebook、Microsoft和卡内基梅隆大学等之间的合作);以及Empathetic Dialogues(华盛顿大学和Facebook之间的合作)。
普遍的Reddit
Plato、DialoFlow和Blender都具有预训练的Reddit评论的默认权重,因此,即使是在新数据(无论是来自Reddit还是其他来源)上进行训练,形成的神经关系也会受到Reddit上提取的特征分布的影响。
每个测试组都进行了两次,分别作为“单个”或“多个”。对于“单个”,每个问题都在一个新的聊天会话中提出。对于“多个”,所有问题都在同一个聊天会话中提出,因为会话变量会在对话过程中积累,并且可以影响响应的质量,因为对话会呈现出特定的形状和语气。
所有实验和训练都在两块NVIDIA Tesla V100 GPU上运行,总共64GB的VRAM和1280个Tensor核心。该论文没有详细说明训练时间的长度。
通过策划或架构进行监督?
该论文得出结论,训练过程中“忽视心理健康风险”的问题需要解决,并邀请研究社区更深入地研究这个问题。
中心因素似乎是,所讨论的聊天机器人框架的设计目的是在没有任何关于有毒或破坏性语言的防护措施的情况下,从分布式数据集中提取显著特征;如果你将新纳粹论坛数据输入这些框架,你可能会在随后的聊天会话中得到一些有争议的响应。
然而,自然语言处理(NLP)领域对从论坛和社交媒体用户贡献内容中获取有关心理健康(抑郁、焦虑、依赖等)的见解有着更合理的兴趣,既是为了开发有帮助和缓解的健康相关聊天机器人,也是为了从真实数据中获得更好的统计推断。
因此,考虑到不受Twitter任意文本限制的高容量数据,Reddit仍然是唯一的、不断更新的超大规模语料库,用于此类全文研究。
然而,即使是对一些最能引起NLP健康研究人员兴趣的社区(如r/depression)进行一次随意的浏览,也会发现“负面”答案的主导地位,这些答案可能会使统计分析系统相信负面答案是有效的,因为它们是频繁的并且在统计上占主导地位,特别是在具有有限的版主资源的高订阅论坛中。
因此,问题仍然存在,即聊天机器人架构是否应该包含某种“道德评估框架”,其中子目标会影响模型中的权重的发展,还是更昂贵的数据策划和标注可以在某种程度上抵消这种趋势。
* 研究人员的论文,如本文所链接的,错误地引用了Google的Meena聊天机器人的链接,而不是Blender论文的链接。Google的Meena没有被新论文收录。本文中使用的Blender链接是由论文作者在电子邮件中提供给我的。作者已告知我,这个错误将在论文的后续版本中被修正。
首次发布于2022年1月18日。












