人工智能
AI帮助紧张的演讲者在视频会议中“读懂房间”

2013年,一项关于常见恐惧症的调查确定,公开演讲的前景对于大多数受访者来说比死亡的前景还要糟糕。这种综合征被称为口吃恐惧症。
COVID-19引发的从“面对面”会议到在线Zoom会议的转变,使用Zoom和Google Spaces等平台,出乎意料地并没有改善这种情况。当会议中有大量参与者时,我们的自然威胁评估能力会因低分辨率的参与者行和图标以及难以读懂微妙的面部表情和身体语言的视觉信号而受到损害。例如,Skype被发现是传递非语言暗示的糟糕平台。
演讲者对感知到的兴趣和反应性的影响已经被充分记录下来,对于我们大多数人来说也很直观。模糊的观众反应会导致演讲者犹豫并退回到填充性言语,无法判断他们的论点是否得到同意、鄙视或漠不关心,经常使演讲者和听众都感到不舒服。
在COVID-19限制和预防措施的压力下,问题可能会变得更加严重,过去两年中,计算机视觉和情感研究社区已经提出了一些改进的观众反馈方案。
基于硬件的解决方案
然而,大多数这些方案都需要额外的设备或复杂的软件,这可能会引起隐私或后勤问题——相对较高的成本或其他资源受限的方法,这些方法是在疫情之前的。2001年,MIT提出了Galvactivator,一种手戴设备,推断出观众参与者的情绪状态,在一次为期一天的研讨会中进行了测试。

2001年,MIT的Galvactivator,测量皮肤电导反应,以尝试了解观众情绪和参与度。 来源:https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
学术界也在“点击器”的可能部署上投入了大量精力,作为观众响应系统(ARS),一种增加观众积极参与度的措施(这自动增加了参与度,因为它迫使观众成为主动的反馈节点),也被设想为一种鼓励演讲者的方式。
其他尝试“连接”演讲者和观众的方法包括心率监测,使用复杂的可穿戴设备来利用脑电图,欢呼计,基于计算机视觉的表情识别,用于办公桌工作者,以及在演讲过程中使用观众发送的表情符号。

2017年,LMU慕尼黑和斯图加特大学的联合学术研究项目EngageMeter。 来源:http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
作为观众分析领域中一个有利可图的子领域,私营部门对凝视估计和跟踪产生了特别的兴趣——系统中,每个观众(他们可能最终需要演讲)都受到眼球跟踪作为参与度和赞同的指标。
所有这些方法都相当耗时。它们中的大多数都需要额外的设备、复杂的软件或订阅昂贵的商业API——或这些限制性因素的任何组合。
因此,过去18个月中,人们对基于仅仅是视频会议的常用工具的极简主义系统的开发产生了兴趣。
隐晦地报告观众赞同
为此,东京大学和卡内基梅隆大学之间的新研究合作提出了一个可以使用标准视频会议工具(如Zoom)的新系统,仅使用带有轻量级凝视和姿势估计软件的Web-cam启用的网站。在这种方式下,甚至不需要本地浏览器插件。
用户的点头和估计的眼球注意力被转换为代表性数据,并以“实时”的方式反馈给演讲者,允许对内容吸引观众的程度进行“实时”的测试——以及至少在某种程度上指示演讲者可能正在失去观众兴趣的话语时期。
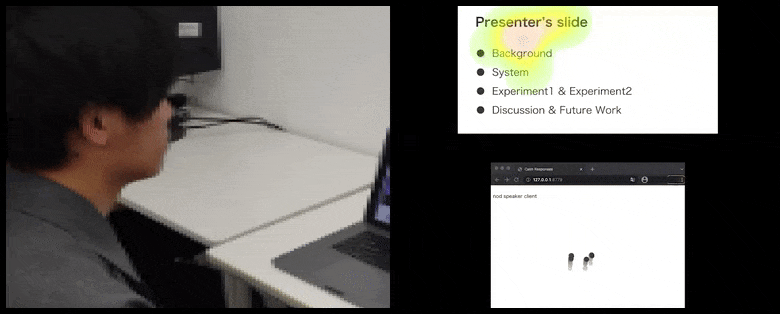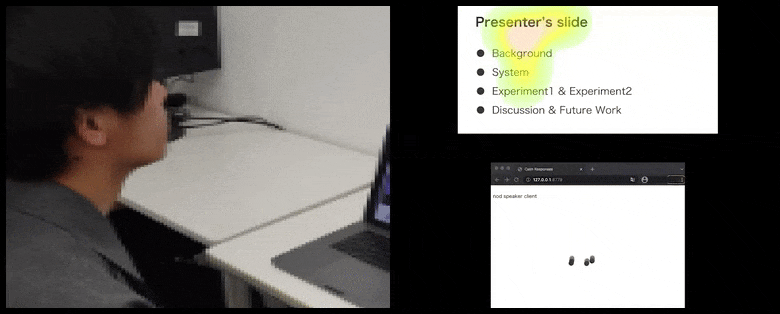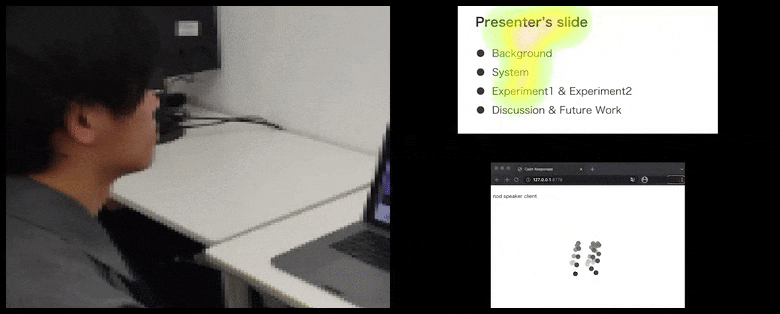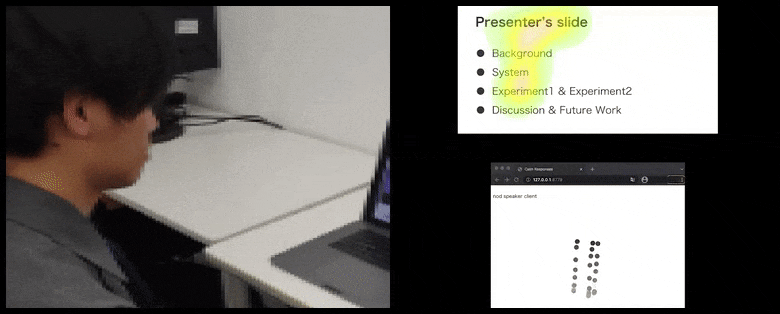
使用CalmResponses,用户的注意力和点头被添加到观众反馈池中,并转换为一个可以让演讲者受益的视觉表示。请参阅文章末尾的嵌入式视频以获取更多详细信息和示例。 来源:https://www.youtube.com/watch?v=J_PhB4FCzk0
在许多学术情况下,例如在线讲座,学生可能对演讲者完全不可见,因为他们没有打开摄像头,可能是因为他们对自己的背景或当前外貌感到自卑。CalmResponses可以通过报告演讲者如何查看内容以及是否点头来解决这个棘手的障碍,而无需观众打开摄像头。
该论文题为《CalmResponses:远程通信中显示集体观众反应》,这是东京大学和卡内基梅隆大学两名研究人员的联合作品。
作者提供了一个基于Web的演示,并在GitHub上发布了源代码。
CalmResponses框架
CalmResponses对点头的兴趣,而不是其他可能的头部姿势,是基于研究(其中一些可以追溯到达尔文时代),表明超过80%的所有听众的头部运动都是点头(即使他们表示不同意)。同时,眼球运动已被证明是对兴趣或参与度的可靠指标。
CalmResponses使用HTML、CSS和JavaScript实现,包括三个子系统:观众客户端、演讲者客户端和服务器。观众客户端通过WebSockets将用户的凝视或头部运动数据从用户的网络摄像头传输到云应用程序平台Heroku。

观众点头在CalmResponses中被可视化。在这种情况下,运动可视化不仅对演讲者可见,也对整个观众可见。 来源:https://arxiv.org/pdf/2204.02308.pdf
对于项目的眼球跟踪部分,研究人员使用了WebGazer,一种轻量级、基于JavaScript的浏览器眼球跟踪框架,可以直接从网站运行,延迟很低(请参阅上面的链接以获取研究人员自己的基于Web的实现)。
由于简单的实现和粗略的、聚合的反应识别比高精度的凝视和姿势估计更重要,因此输入的姿势数据在被用于整体反应估计之前会根据平均值进行平滑处理。
点头动作通过JavaScript库clmtrackr进行评估,该库通过规则化的特征点平均值将面部模型拟合到检测到的图像或视频中的面部。为了实现经济高效和低延迟,作者的实现中仅主动监测检测到的鼻子特征点,因为这足以跟踪点头动作。
用户的鼻尖位置创建了一个轨迹,贡献于点头相关的观众反应池,并以聚合的方式可视化给所有参与者。
热力图
虽然点头活动以动态移动的点表示(请参阅上面的图像和文章末尾的视频),但视觉注意力以热力图的形式报告,显示演讲者和观众在共享的演示屏幕或视频会议环境中关注的焦点所在。

所有参与者都可以看到一般用户注意力的焦点所在。该论文没有提到这一功能是否在用户可以看到其他参与者的“画廊”时可用,这可能会由于各种原因显示出对特定参与者的虚假关注。
测试
为CalmResponses制定了两个测试环境,采用了三种不同的情况:在“条件B”(基线)中,作者复制了一个典型的在线学生讲座,大多数学生关闭了摄像头,演讲者无法看到观众的面部;在“条件CR-E”中,演讲者可以看到凝视反馈(热力图);在“条件CR-N”中,演讲者可以看到观众的点头和凝视活动。
第一个实验场景包括条件B和条件CR-E;第二个实验场景包括条件B和条件CR-N。从演讲者和观众那里获得了反馈。
在每个实验中,评估了三个因素:演讲的客观和主观评估(包括演讲者关于演讲进展的自我报告问卷);“填充”言语的事件数量,表明暂时的不安全感和犹豫;以及定性的评论。这些标准是演讲质量和演讲者焦虑的常见估计器。
测试池由38人组成,年龄在19-44岁之间,包括29名男性和9名女性,平均年龄24.7岁,全部为日语或中文母语者,全部流利地掌握日语。他们被随机分成五组,每组6-7名参与者,且没有任何参与者相互认识。
测试是在Zoom上进行的,第一场实验中有五位演讲者,第二场实验中有六位演讲者。

填充条件以橙色框标记。一般来说,填充内容随着系统的增加而减少。
研究人员指出,一位演讲者的填充内容大大减少,在“条件CR-N”中,演讲者很少说填充短语。请参阅论文以获取详细和详尽的结果;然而,最显著的结果是来自演讲者和观众参与者的主观评估。
观众的评论包括:
“我觉得我参与了演讲”[AN2],“我不确定演讲者的演讲是否有所改善,但我从其他人的头部运动可视化中感到一种团结感。”[AN6]
“我不确定演讲者的演讲是否有所改善,但我从其他人的头部运动可视化中感到一种团结感。”
研究人员指出,该系统引入了一种新的人工暂停到演讲者的演讲中,因为演讲者倾向于参考视觉系统来评估观众的反馈,然后再继续。
他们还指出了一种“白大褂效应”,在实验环境中很难避免,其中一些参与者感到被监测的生物数据的安全影响所束缚。
结论
像这样的系统的一个显著优势是,所有非标准的辅助技术在使用后完全消失。没有残留的浏览器插件需要卸载,也没有需要引导用户安装或导航的可能性,用户可能没有足够的权限安装本地软件,包括浏览器插件和扩展。
虽然评估的面部和眼球运动可能不如在使用专用本地机器学习框架(如YOLO系列)时那么精确,但这种几乎无摩擦的观众评估方法为典型的视频会议场景提供了足够的精度,用于广泛的情绪和态度分析。最重要的是,它非常廉价。
请参阅下面的项目视频以获取更多详细信息和示例。
首次发布于2022年4月11日。












