Anderson 视角
一种“侦探”AI 可以从多个来源识别晦涩的人物

牛津大学的研究人员开发了一种人工智能启用的系统,可以通过对视频进行类似侦探的、多领域调查来全面识别视频中的人物,包括从上下文和各种公开可用的次要来源中,包括将音频源与互联网上的视觉材料进行匹配。
虽然研究集中在识别公众人物(如电视节目和电影中出现的人物)上,但从上下文推断身份的原理在理论上适用于任何在在线来源中出现面部、声音或姓名的人。
的确,论文中定义的名气概念并不局限于娱乐业工作者,研究人员宣称“我们将那些在网上有很多自己的图像的人称为名人”。
直接到视频
牛津大学工程科学系视觉几何小组的研究人员概述了激发这项工作的人类式调查方法:
“想象一下你正在观看一个视频,遇到一个新的人。为了自信地识别他们,你首先会在视频中寻找他们的名字线索,例如屏幕上的文本、他们的名字被提及在演讲中,或者在互联网档案中的演员名单中。你可能会找到一些证据来验证这个名字是正确的,通过在线搜索这个人。”
论文中提出的方法是完全自动化的,消除了所有额外的手动标记(不包括在线来源提供者可能执行的标记)。该系统也被证明可以在没有任何域适应需要的情况下在三个无关的数据集上良好地工作。
讨论这项工作的应用,研究人员指出未标记的、不透明的视频数据的指数增长,以及需要从这些数据中推导出身份信息而不需要昂贵的人工注释的新系统的必要性:
‘[数据的]庞大规模,加上缺乏相关元数据,使得索引、分析和导航这些内容变得越来越困难。依赖额外的手动人工注释不再可行,而没有有效的方法来导航这些视频,这批知识基本上是无法访问的。’
这种索引引擎的性质开启了搜索结果超链接直接到达视频中搜索主题出现的点的可能性,如项目提供的概念验证网页搜索所示。
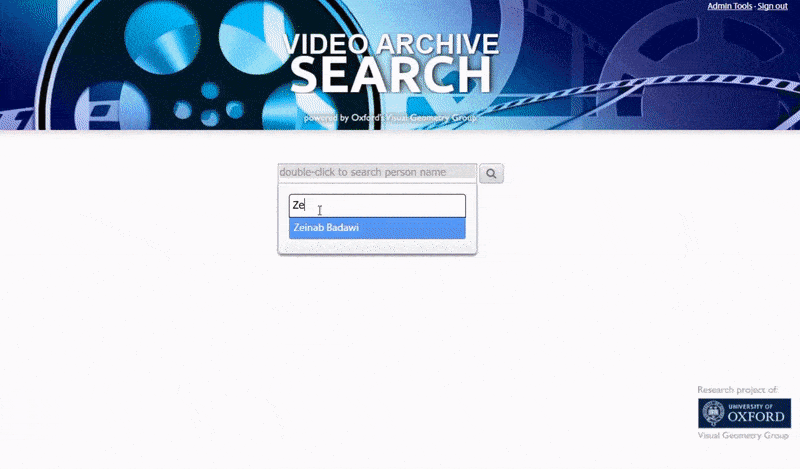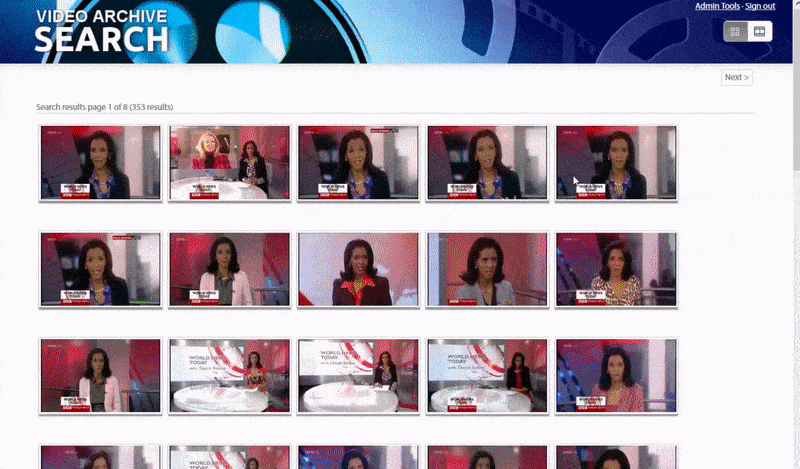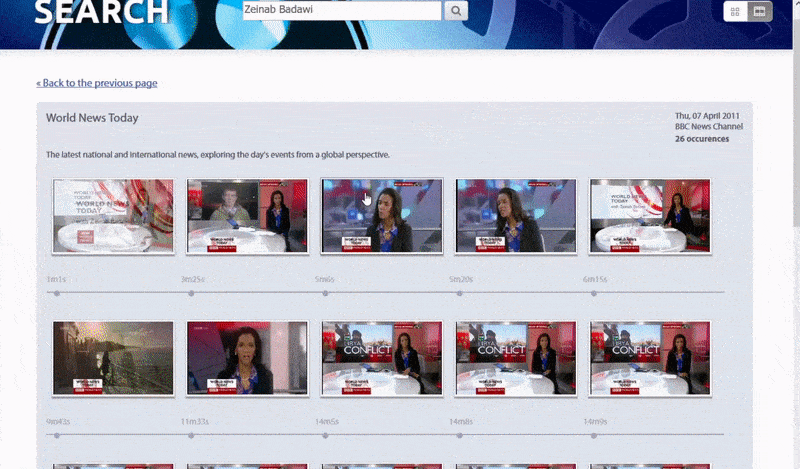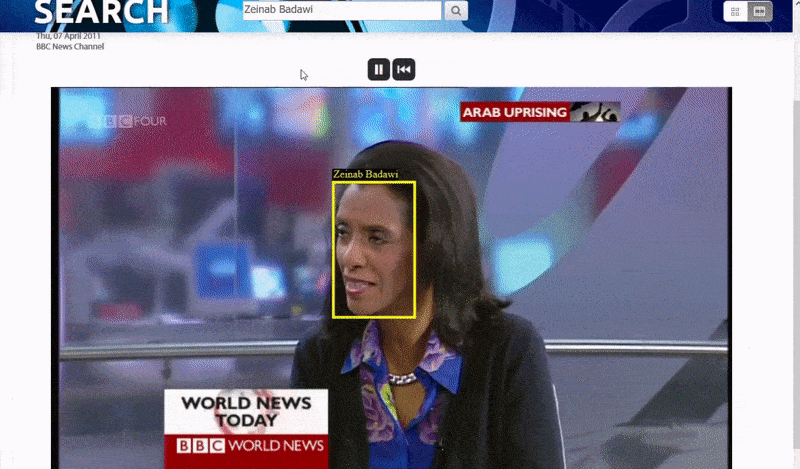
牛津系统允许搜索已识别的人的实例。搜索结果直接将查看者带到视频中已识别的人出现的点,并且可以从该点播放视频. 来源:https://www.robots.ox.ac.uk/~vgg/research/person_id_in_video/
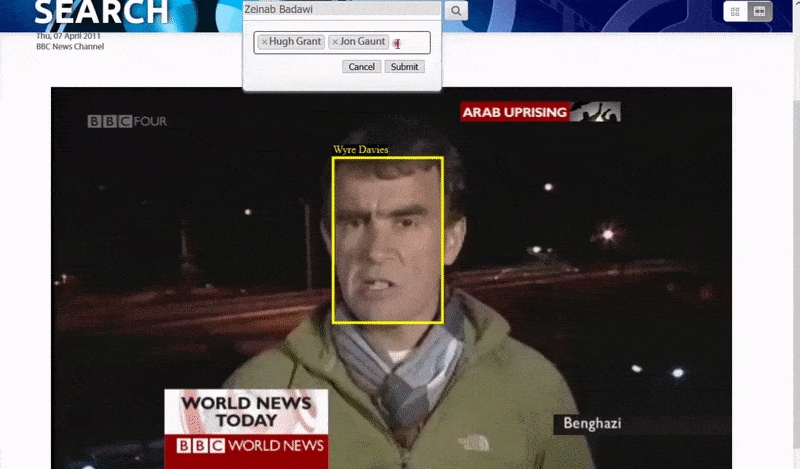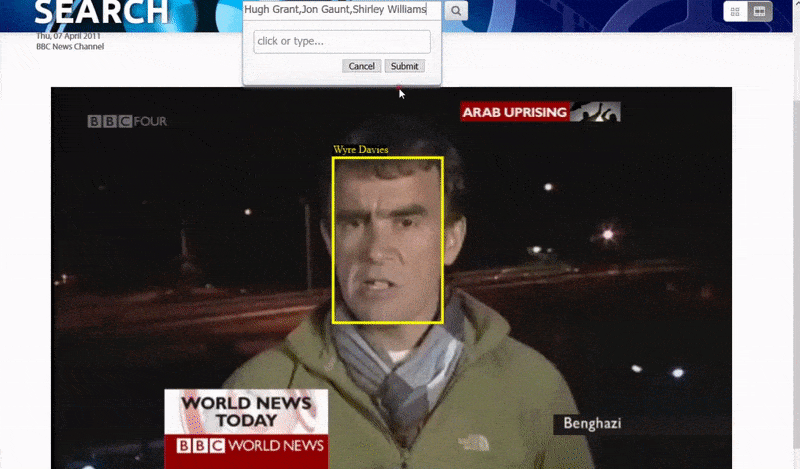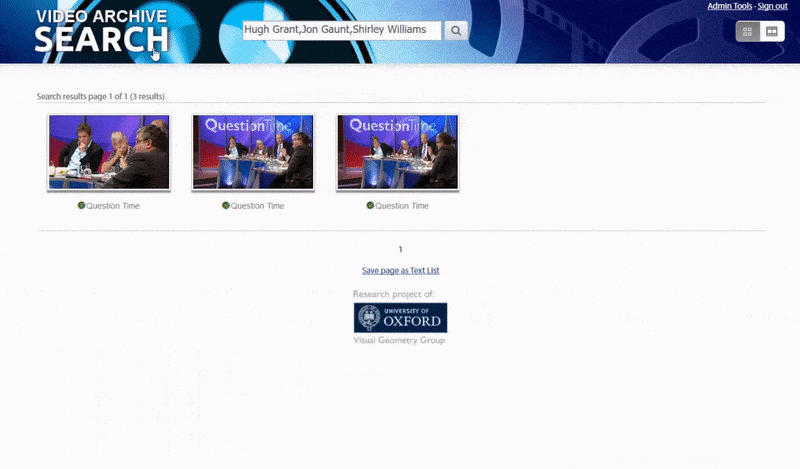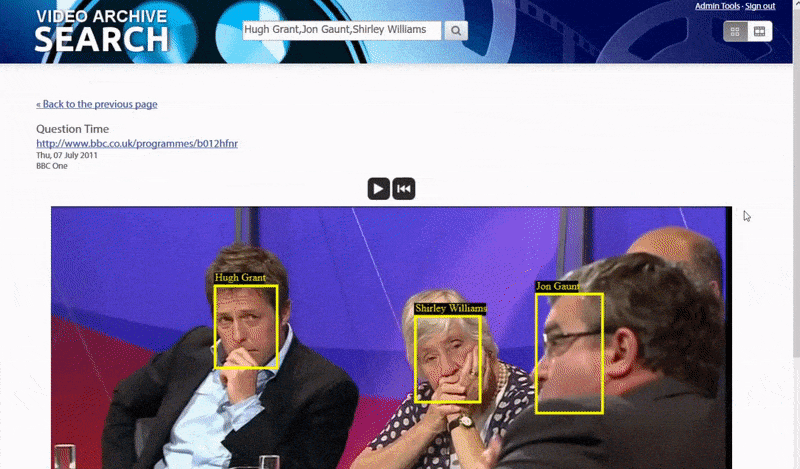
系统识别“晦涩”人物的一种方法是通过他们与他人的关联的上下文。因此,搜索引擎非常适合搜索同一视频中出现的多个身份:
大人物和小人物
系统首先解决“低垂果实”——那些在公共网络资源中面部被如此彻底索引以至于识别他们相对简单的人,通过匹配元数据或视频中的OCR文本与公共数据资源(如IMDB列表)进行匹配。视频字幕、字幕和其他视频中的光栅文本也被用来验证身份。

候选名称可以通过光栅文本的光学字符识别或其他来源的实际文本自动发现。因此,人们可以在没有个人用户针对其名称运行任何查询的情况下自动索引,而无需参与人工智能启用的社交网络. 来源:https://www.robots.ox.ac.uk/~vgg/publications/2021/Brown21/brown21.pdf
当网络面向图像和视频确认人物身份时,调查确认身份。但是,当人物更加晦涩时,其他方法被采用,包括从视频音轨中提取的音频,可以用作确认身份的佐证。虽然这项工作中没有涉及,但逻辑上,这种框架也可以使用纯音频源以及视频中的音频组件。
自我繁殖的身份万神殿
除了从光栅化或纯文本中生成候选名称外,牛津项目还使用语音识别技术来识别仅在音频内容中被提及的名称。因此,一个身份可以通过一个人或两个人仅仅提及一个不在场的第三个人来初始化。
牛津项目引入的保障措施是,候选人必须出现在IMDB数据库中,但去掉这一任意限制可以显著扩大系统的潜在范围,因为它完全依赖于网页可爬取的资源。

因此,通过结合包括从光栅文本、实际文本、基于语音的提及和非常有限的视觉材料中推导出的名称,成为可能识别视觉网络存在度低的个体。
从技术上讲,也有可能建立一个个人资料,该个人资料最初没有任何图像或视频关联,但最终可以将图像或视频附加到该个人资料中,当其他因素与新摄取的视频源相关时。
测试数据集
研究人员使用三个数据集来评估系统的有效性:MediaEval,它包含2010-2015年间捕获的Creative Commons社交媒体派生和社区图像资源(包括维基百科和Flickr);牛津小组自己的2017年Sherlock数据集,它包含来自现代BBC改编版的柯南道尔经典角色;以及为该项目特别创建的BBC视频数据集,该数据集使用来自BBC的各种注释新闻片段。

系统在各种数据集环境中成功,包括面部被反射或黑暗遮挡的情况。
该过程还利用了实时图像搜索排名。
该系统在三个模型上产生了高精度的结果。在Sherlock数据集的情况下,研究人员惊讶地发现,该新系统比使用支持向量机(SVM)在多路分类器中的前一种方法提高了3-6%,尽管新工作中使用的最近邻分类器是一种较弱的工具。
影响
牛津项目中的大多数伦理或实际约束都是由研究人员自己施加的,例如通过要求发现的身份必须在IMDB中存在来定义“名气”,以及仅测试系统对尊重Creative Commons许可的既定学术数据集。
然而,该项目的基本架构描绘了一种通用方法,不仅可以识别具有低或零视觉存在的“晦涩”个体(因为一个名字的简单提及可以产生一个可以随着时间的推移发展的身份令牌),而且可以实际创建一个由递归和机械的好奇心驱动的个体矩阵,而不是由需求或显式标记数据(如包含PII元数据的社交媒体照片上传)驱动。
该项目不使用地理位置数据或其他可能在贡献文件中找到的元数据维度,例如默认上传到社交媒体的地理位置信息(如果这些信息未被用户偏好删除)。然而,使用这些额外的数据维度来加强确认过程并没有明显的障碍。
虽然牛津项目以常见于机器学习项目的方式修剪异常值(几乎没有存在的身份,以及未在IMDB中列出的身份),但这些最小的信息可以比具有更多代表性信息的情况下更有效地识别一个未知的人。如果异常值正是你要找的东西(即网络足迹很少的个体),稀疏数据可以是非常具有指示性的。
可用性
牛津研究人员将该项目的功能封装到一个类似Google的搜索引擎中,可以通过Docker下载和安装在本地机器上(尽管2021年5月论文的安装说明目前包含Docker工具要求的过时信息,这可能会阻碍该过程)。

目前似乎没有一个在线版本涵盖了该项目在所有三个数据集上的实现,尽管BBC新闻数据集的结果可以在http://zeus.robots.ox.ac.uk/bbc_search/免费查询。












