
AI 101
ต้นไม้การตัดสินใจคืออะไร?
ต้นไม้การตัดสินใจคืออะไร?
A ต้นไม้ตัดสินใจ เป็นอัลกอริธึมการเรียนรู้ของเครื่องที่มีประโยชน์ซึ่งใช้สำหรับทั้งงานการถดถอยและการจัดหมวดหมู่ ชื่อ “แผนผังการตัดสินใจ” มาจากข้อเท็จจริงที่ว่าอัลกอริทึมจะแบ่งชุดข้อมูลออกเป็นส่วนเล็กๆ เรื่อยๆ จนกว่าข้อมูลจะถูกแบ่งออกเป็นอินสแตนซ์เดียว ซึ่งจากนั้นจึงจัดประเภท หากคุณต้องเห็นภาพผลลัพธ์ของอัลกอริธึม วิธีการแบ่งหมวดหมู่จะมีลักษณะคล้ายต้นไม้และใบไม้จำนวนมาก
นั่นเป็นคำจำกัดความสั้นๆ ของแผนผังการตัดสินใจ แต่เราจะเจาะลึกลงไปว่าโครงสร้างการตัดสินใจทำงานอย่างไร การมีความเข้าใจที่ดีขึ้นเกี่ยวกับวิธีการทำงานของแผนผังการตัดสินใจ รวมถึงกรณีการใช้งาน จะช่วยให้คุณรู้ว่าควรใช้เมื่อใดในระหว่างโครงการแมชชีนเลิร์นนิงของคุณ
รูปแบบของแผนผังการตัดสินใจ
ต้นไม้ตัดสินใจคือ มากเหมือนผังงาน ในการใช้ผังงาน คุณเริ่มต้นที่จุดเริ่มต้นหรือรากของแผนภูมิ จากนั้นขึ้นอยู่กับวิธีที่คุณตอบเกณฑ์การกรองของโหนดเริ่มต้นนั้น คุณจะย้ายไปยังโหนดที่เป็นไปได้ถัดไป กระบวนการนี้จะทำซ้ำจนกว่าจะถึงจุดสิ้นสุด
แผนผังการตัดสินใจทำงานในลักษณะเดียวกัน โดยโหนดภายในทุกโหนดในแผนผังเป็นเกณฑ์การทดสอบ/การกรองบางประเภท โหนดที่อยู่ด้านนอกซึ่งเป็นจุดสิ้นสุดของต้นไม้คือป้ายกำกับสำหรับจุดข้อมูลที่เป็นปัญหา และเรียกว่า "ใบไม้" สาขาที่นำจากโหนดภายในไปยังโหนดถัดไปคือคุณสมบัติหรือคำเชื่อมของคุณสมบัติ กฎที่ใช้ในการจำแนกจุดข้อมูลคือเส้นทางที่วิ่งจากรูทไปยังลีฟ
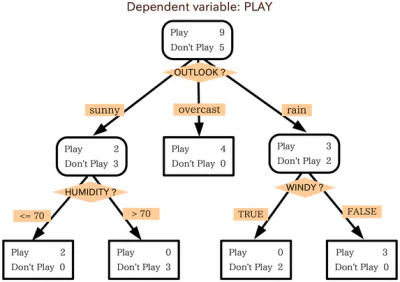
อัลกอริทึมสำหรับแผนผังการตัดสินใจ
แผนผังการตัดสินใจทำงานโดยใช้อัลกอริทึมซึ่งแบ่งชุดข้อมูลออกเป็นแต่ละจุดข้อมูลตามเกณฑ์ที่แตกต่างกัน การแยกเหล่านี้ทำได้ด้วยตัวแปรต่างๆ หรือคุณลักษณะต่างๆ ของชุดข้อมูล ตัวอย่างเช่น หากเป้าหมายคือการระบุว่าคุณลักษณะอินพุตอธิบายสุนัขหรือแมวหรือไม่ ตัวแปรที่แยกข้อมูลออกอาจเป็น "กรงเล็บ" และ "เปลือกไม้"
อัลกอริทึมใดที่ใช้ในการแยกข้อมูลออกเป็นสาขาและใบไม้ มีหลายวิธีที่สามารถใช้ในการแยกต้นไม้ แต่วิธีการแยกที่ใช้กันมากที่สุดน่าจะเป็นเทคนิคที่เรียกว่า "แยกไบนารีแบบเรียกซ้ำ". เมื่อดำเนินการแยกด้วยวิธีนี้ กระบวนการจะเริ่มต้นที่รูทและจำนวนคุณลักษณะในชุดข้อมูลแสดงถึงจำนวนการแยกที่เป็นไปได้ ฟังก์ชันจะใช้เพื่อกำหนดความถูกต้องของการแยกแต่ละส่วนที่เป็นไปได้ซึ่งมีค่าใช้จ่าย และการแยกจะทำโดยใช้เกณฑ์ที่เสียสละความแม่นยำน้อยที่สุด กระบวนการนี้ดำเนินการซ้ำและกลุ่มย่อยถูกสร้างขึ้นโดยใช้กลยุทธ์ทั่วไปเดียวกัน
เพื่อที่จะ กำหนดต้นทุนของการแยกจะใช้ฟังก์ชันต้นทุน ฟังก์ชันต้นทุนที่แตกต่างกันจะใช้สำหรับงานการถดถอยและงานการจัดประเภท เป้าหมายของฟังก์ชันต้นทุนทั้งสองคือการกำหนดว่าสาขาใดมีค่าการตอบสนองที่ใกล้เคียงกันมากที่สุด หรือสาขาที่เป็นเนื้อเดียวกันมากที่สุด พิจารณาว่าคุณต้องการข้อมูลทดสอบของบางคลาสให้เป็นไปตามเส้นทางที่กำหนด และสิ่งนี้สมเหตุสมผลโดยสัญชาตญาณ
ในแง่ของฟังก์ชันต้นทุนการถดถอยสำหรับการแยกไบนารีแบบเรียกซ้ำ อัลกอริทึมที่ใช้ในการคำนวณต้นทุนมีดังนี้:
ผลรวม(y – การทำนาย)^2
การคาดคะเนสำหรับจุดข้อมูลกลุ่มใดกลุ่มหนึ่งคือค่าเฉลี่ยของการตอบสนองของข้อมูลการฝึกอบรมสำหรับกลุ่มนั้น จุดข้อมูลทั้งหมดถูกรันผ่านฟังก์ชันต้นทุนเพื่อกำหนดต้นทุนสำหรับการแยกที่เป็นไปได้ทั้งหมด และเลือกการแยกที่มีค่าใช้จ่ายต่ำสุด
เกี่ยวกับฟังก์ชันต้นทุนสำหรับการจำแนกประเภท ฟังก์ชันมีดังนี้
G = ผลรวม(pk * (1 – pk))
นี่คือคะแนน Gini และเป็นการวัดประสิทธิภาพของการแบ่ง โดยพิจารณาจากจำนวนของคลาสต่างๆ ในกลุ่มที่เป็นผลมาจากการแยก กล่าวอีกนัยหนึ่งคือวัดว่ากลุ่มต่างๆ เป็นอย่างไรหลังจากการแยก การแยกที่เหมาะสมคือเมื่อกลุ่มทั้งหมดที่เกิดจากการแยกประกอบด้วยอินพุตจากคลาสเดียวเท่านั้น หากมีการสร้างการแบ่งที่เหมาะสมที่สุด ค่า "pk" จะเป็น 0 หรือ 1 และ G จะเท่ากับศูนย์ คุณอาจเดาได้ว่าการแบ่งกรณีที่แย่ที่สุดคือการแยกคลาสที่มีตัวแทน 50-50 ในกรณีของการจำแนกประเภทไบนารี ในกรณีนี้ ค่า “pk” จะเป็น 0.5 และ G จะเป็น 0.5 ด้วย
กระบวนการแยกจะสิ้นสุดลงเมื่อจุดข้อมูลทั้งหมดถูกเปลี่ยนเป็นใบไม้และจัดประเภท อย่างไรก็ตาม คุณอาจต้องการหยุดการเจริญเติบโตของต้นไม้แต่เนิ่นๆ ต้นไม้ขนาดใหญ่ที่ซับซ้อนมีแนวโน้มที่จะเกินขนาด แต่สามารถใช้วิธีการต่าง ๆ มากมายเพื่อต่อสู้กับสิ่งนี้ วิธีหนึ่งในการลด overfitting คือการระบุจำนวนจุดข้อมูลขั้นต่ำที่จะใช้ในการสร้าง leaf อีกวิธีหนึ่งในการควบคุม overfitting คือการจำกัดต้นไม้ให้มีความลึกสูงสุดที่กำหนด ซึ่งควบคุมว่าเส้นทางสามารถยืดจากรากไปยังใบไม้ได้นานแค่ไหน
อีกกระบวนการหนึ่งที่เกี่ยวข้องกับการสร้างแผนผังการตัดสินใจ กำลังตัดแต่งกิ่ง การตัดกิ่งสามารถช่วยเพิ่มประสิทธิภาพการทำงานของแผนผังการตัดสินใจได้โดยการดึงกิ่งก้านที่มีคุณลักษณะที่มีอำนาจการทำนายน้อย/ความสำคัญน้อยสำหรับแบบจำลองออก ด้วยวิธีนี้ ความซับซ้อนของแผนผังจะลดลง มีโอกาสน้อยที่จะเกินพอดี และเพิ่มอรรถประโยชน์ในการทำนายของโมเดล
เมื่อทำการตัดแต่งกิ่ง กระบวนการสามารถเริ่มต้นที่ด้านบนของต้นไม้หรือด้านล่างของต้นไม้ก็ได้ อย่างไรก็ตาม วิธีที่ง่ายที่สุดในการตัดคือการเริ่มต้นด้วย leaf และพยายามดรอปโหนดที่มีคลาสทั่วไปภายใน leaf นั้น หากความแม่นยำของโมเดลไม่ลดลงเมื่อดำเนินการเสร็จสิ้น การเปลี่ยนแปลงนั้นจะถูกรักษาไว้ มีเทคนิคอื่นๆ ที่ใช้ในการตัดแต่งกิ่ง แต่วิธีการที่อธิบายไว้ข้างต้น – การตัดแต่งกิ่งที่มีข้อผิดพลาดลดลง – น่าจะเป็นวิธีการตัดแต่งกิ่งต้นไม้ตัดสินใจที่ใช้บ่อยที่สุด
ข้อควรพิจารณาในการใช้แผนผังการตัดสินใจ
ต้นไม้ตัดสินใจ มักจะมีประโยชน์ เมื่อต้องมีการจำแนกประเภท แต่เวลาในการคำนวณเป็นข้อจำกัดที่สำคัญ แผนผังการตัดสินใจสามารถทำให้ชัดเจนว่าคุณลักษณะใดในชุดข้อมูลที่เลือกมีอำนาจในการทำนายมากที่สุด นอกจากนี้ ไม่เหมือนกับอัลกอริทึมการเรียนรู้ของเครื่องหลายตัวตรงที่กฎที่ใช้ในการจำแนกข้อมูลอาจตีความได้ยาก ต้นไม้การตัดสินใจสามารถแสดงกฎที่ตีความได้ ต้นไม้การตัดสินใจยังสามารถใช้ทั้งตัวแปรที่เป็นหมวดหมู่และตัวแปรต่อเนื่อง ซึ่งหมายความว่าจำเป็นต้องมีการประมวลผลล่วงหน้าน้อยกว่า เมื่อเปรียบเทียบกับอัลกอริทึมที่สามารถจัดการตัวแปรเหล่านี้ได้เพียงประเภทเดียวเท่านั้น
แผนภูมิการตัดสินใจมักจะทำงานได้ไม่ดีเมื่อใช้เพื่อกำหนดค่าของแอตทริบิวต์ต่อเนื่อง ข้อจำกัดอีกอย่างหนึ่งของแผนผังการตัดสินใจก็คือ เมื่อทำการจำแนกประเภท หากมีตัวอย่างการฝึกอบรมน้อยแต่มีหลายชั้นเรียน ต้นไม้การตัดสินใจมักจะไม่ถูกต้อง










