AI 101
อะไรคือ CNNs (Convolutional Neural Networks)?
คุณอาจสงสัยว่า Facebook หรือ Instagram สามารถจดจำใบหน้าในภาพอัตโนมัติได้อย่างไร หรือว่า Google สามารถค้นหาเว็บสำหรับภาพที่คล้ายกันโดยการอัปโหลดภาพของคุณเองได้อย่างไร คุณลักษณะเหล่านี้เป็นตัวอย่างของการมองเห็นของคอมพิวเตอร์ และได้รับการสนับสนุนจาก โครงข่ายประสาทเทียมแบบโครงข่ายการกรอง (CNNs) แต่สิ่งเหล่านี้คืออะไร ลองดูโครงสร้างของ CNN และเข้าใจว่าพวกมันทำงานอย่างไร
อะไรคือโครงข่ายประสาทเทียม?
ก่อนที่เราจะพูดถึงโครงข่ายประสาทเทียมแบบโครงข่ายการกรอง ลองนิยามโครงข่ายประสาทเทียมแบบปกติก่อน มี บทความอื่น เกี่ยวกับโครงข่ายประสาทเทียมแบบปกติ ดังนั้นเราจึงไม่จะลึกเกินไป แต่เพื่อกำหนดให้เข้าใจง่าย โครงข่ายประสาทเทียมแบบปกติเป็นแบบจำลองการคำนวณที่ได้รับแรงบันดาลใจจากสมองมนุษย์ โครงข่ายประสาทเทียมแบบปกติทำงานโดยการรับข้อมูลและจัดการข้อมูลโดยการปรับ “น้ำหนัก” ซึ่งเป็นข้อสันนิษฐานเกี่ยวกับวิธีที่คุณลักษณะของข้อมูลเข้าสัมพันธ์กันและกันและกับชั้นเรียนของวัตถุ เมื่อโครงข่ายถูกฝึกอบรม ค่าของน้ำหนักจะถูกปรับและพวกเขาจะหวังว่าจะสอดคล้องกับน้ำหนักที่จับข้อสัมพันธ์ระหว่างคุณลักษณะได้อย่างแม่นยำ
นี่คือวิธีการทำงานของโครงข่ายประสาทเทียมแบบปกติ และ CNNs ประกอบด้วยสองส่วน: โครงข่ายประสาทเทียมแบบปกติและกลุ่มของโครงข่ายการกรอง
อะไรคือโครงข่ายการกรอง?
อะไรคือ “การกรอง” ที่เกิดขึ้นในโครงข่ายประสาทเทียมแบบโครงข่ายการกรอง? การกรองเป็นการดำเนินการทางคณิตศาสตร์ที่สร้างชุดของน้ำหนัก ซึ่งสร้างการแสดงออกของส่วนหนึ่งของภาพ ชุดน้ำหนักนี้เรียกว่า เคอร์เนลหรือฟิลเตอร์ ฟิลเตอร์ที่สร้างขึ้นนั้นเล็กกว่าภาพเข้าสุดทั้งหมด และครอบคลุมเฉพาะส่วนหนึ่งของภาพเท่านั้น ค่าในฟิลเตอร์จะถูกคูณกับค่าในภาพ ฟิลเตอร์จะถูกย้ายไปเพื่อสร้างการแสดงออกของส่วนใหม่ของภาพ และกระบวนการจะทำซ้ำจนกว่าภาพทั้งหมดจะถูกครอบคลุม
วิธีอื่นที่จะคิดเกี่ยวกับเรื่องนี้คือการนึกภาพกำแพงอิฐ โดยอิฐแทนพิกเซลในภาพเข้าสุดที่มองเห็นได้ “หน้าต่าง” ถูกเลื่อนไปมา沿กำแพง ซึ่งเป็นฟิลเตอร์ อิฐที่มองเห็นได้จากหน้าต่างคือพิกเซลที่มีค่าถูกคูณด้วยค่าในฟิลเตอร์ ด้วยเหตุนี้ วิธีการสร้างน้ำหนักด้วยฟิลเตอร์จึงเรียกว่า “วิธีการหน้าต่างเลื่อน”
การกรองจะถูกย้ายไปรอบภาพเข้าสุดทั้งหมด และผลลัพธ์จากฟิลเตอร์คือแถวและคอลัมน์ของค่า ซึ่งแสดงถึงภาพทั้งหมด แถวและคอลัมน์นี้เรียกว่า “แผนที่คุณลักษณะ”
ทำไมการกรองจึงจำเป็น?
การกรองมีจุดมุ่งหมายเพื่อให้โครงข่ายประสาทเทียมสามารถตีความพิกเซลในภาพเป็นค่าจำนวนได้ ฟังก์ชันของโครงข่ายการกรองคือการแปลงภาพเป็นค่าจำนวนเชิงตัวเลขที่โครงข่ายประสาทเทียมสามารถตีความและดึงรูปแบบที่เกี่ยวข้องออกมาได้ งานของฟิลเตอร์ในโครงข่ายการกรองคือการสร้างแถวและคอลัมน์ของค่าที่สามารถส่งเข้าสู่ชั้นหลังของโครงข่ายประสาทเทียมได้ ซึ่งจะเรียนรู้รูปแบบในภาพ
ฟิลเตอร์และช่องสี
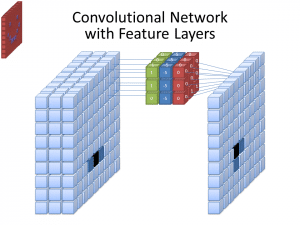
ภาพ: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNNs ไม่ใช้ฟิลเตอร์เพียงตัวเดียวในการเรียนรู้รูปแบบจากภาพเข้าสุดที่มองเห็นได้ ฟิลเตอร์หลายตัวถูกใช้ เนื่องจากระบบที่สร้างโดยฟิลเตอร์ต่างๆ นำไปสู่การแสดงออกที่ซับซ้อนและ豊富ของภาพเข้าสุดที่มองเห็นได้ จำนวนฟิลเตอร์ที่พบบ่อยสำหรับ CNNs คือ 32, 64, 128 และ 512 ฟิลเตอร์มากเท่าไหร่ โอกาสที่ CNN จะมองเห็นข้อมูลเข้าสุดที่มองเห็นได้และเรียนรู้จากมันมากเท่านั้น
CNN วิเคราะห์ความแตกต่างของค่าพิกเซลเพื่อกำหนดขอบเขตของวัตถุ ในภาพสีเทา CNN จะมองเห็นความแตกต่างระหว่างสีดำและสีขาวเท่านั้น เมื่อภาพเป็นภาพสี CNN จะต้องคำนึงถึงช่องสีสามช่อง – แดง สีเขียว และสีน้ำเงิน – ด้วย ฟิลเตอร์จะมีช่องสี 3 ช่อง เช่นเดียวกับภาพที่มองเห็นได้ จำนวนช่องสีที่ฟิลเตอร์มีเรียกว่า “ความลึก” และจำนวนช่องสีในฟิลเตอร์จะต้องตรงกับจำนวนช่องสีในภาพ
โครงข่ายการกรอง (CNN) โครงสร้าง
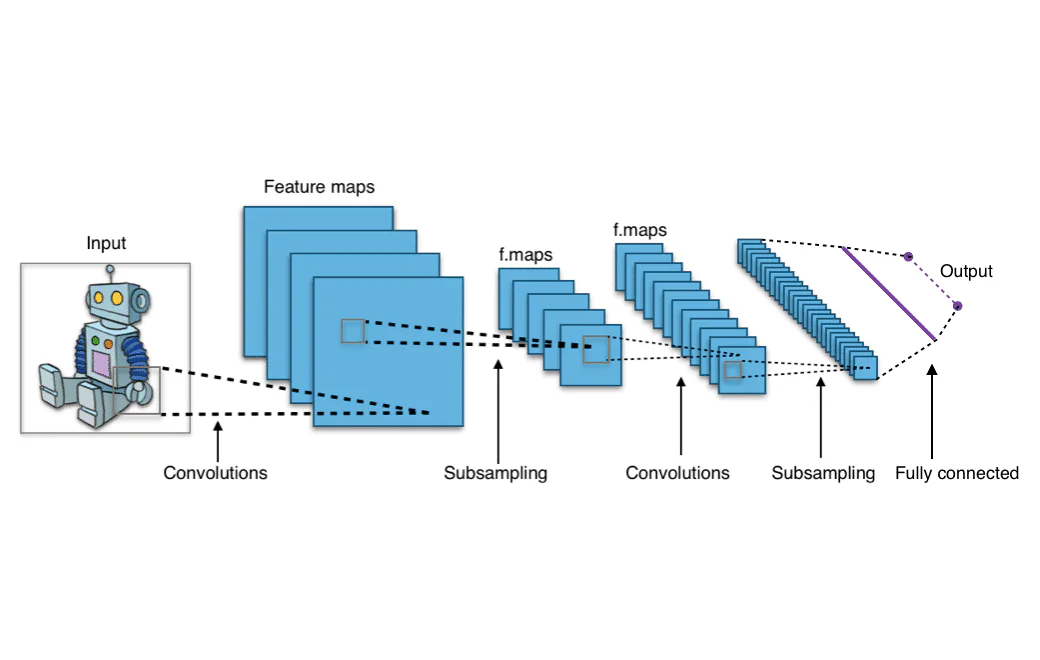
มา看看โครงสร้างที่สมบูรณ์ของโครงข่ายการกรอง โครงข่ายการกรองจะพบในชั้นต้นของทุกโครงข่ายการกรอง เนื่องจากจำเป็นต้องแปลงข้อมูลภาพเป็นแถวและคอลัมน์ของค่าจำนวนเชิงตัวเลข แต่โครงข่ายการกรองสามารถตามหลังโครงข่ายการกรองอื่นได้ ซึ่งหมายความว่าชั้นเหล่านี้สามารถซ้อนกัน ผลลัพธ์จากชั้นหนึ่งสามารถผ่านการกรองเพิ่มเติมและจัดกลุ่มเป็นรูปแบบที่เกี่ยวข้องได้
ชั้นต้นของ ConvNet มีหน้าที่ในการดึงคุณลักษณะระดับต้น เช่น พิกเซลที่ประกอบเป็นเส้นตรง ชั้นหลังของ ConvNet จะรวมเส้นเหล่านี้เข้าด้วยกันเป็นรูปทรง เมื่อกระบวนการนี้ดำเนินต่อไปจนกว่า ConvNet จะจดจำรูปทรงที่ซับซ้อน เช่น สัตว์ ใบหน้ามนุษย์ และรถยนต์
หลังจากที่ข้อมูลผ่านชั้นการกรองทั้งหมดแล้ว จะเข้าสู่ส่วนเชื่อมต่ออย่างหนาแน่นของ CNN ส่วนเชื่อมต่ออย่างหนาแน่นคือสิ่งที่โครงข่ายประสาทเทียมแบบปกติมีลักษณะเหมือนกัน ซึ่งเป็นชุดของโหนดที่จัดเรียงเป็นชั้นและเชื่อมต่อกัน ข้อมูลจะผ่านชั้นเชื่อมต่ออย่างหนาแน่นเหล่านี้ ซึ่งเรียนรู้รูปแบบที่ถูกดึงออกมาโดยชั้นการกรอง และด้วยเหตุนี้ โครงข่ายจึงสามารถจดจำวัตถุได้










