
ที่ดีที่สุดของ
10 อัลกอริทึมการเรียนรู้ของเครื่องที่ดีที่สุด
แม้ว่าเราจะมีชีวิตอยู่ในช่วงเวลาแห่งนวัตกรรมที่ไม่ธรรมดาในการเรียนรู้ของเครื่องที่เร่งด้วย GPU แต่งานวิจัยล่าสุดมัก (และโดดเด่น) นำเสนออัลกอริทึมที่มีอายุหลายทศวรรษ ในบางกรณีมีอายุ 70 ปี
บางคนอาจโต้แย้งว่าวิธีการที่เก่ากว่าเหล่านี้ตกอยู่ในค่ายของ 'การวิเคราะห์ทางสถิติ' มากกว่าการเรียนรู้ด้วยเครื่อง และชอบที่จะระบุวันที่การกำเนิดของภาคนี้ย้อนหลังไปถึงปี 1957 เท่านั้นด้วย การประดิษฐ์ Perceptron.
เมื่อพิจารณาถึงขอบเขตที่อัลกอริทึมรุ่นเก่าเหล่านี้รองรับและเชื่อมโยงกับแนวโน้มล่าสุดและการพัฒนาที่พาดหัวข่าวในแมชชีนเลิร์นนิง จึงเป็นจุดยืนที่โต้แย้งได้ ลองมาดูองค์ประกอบการสร้าง 'คลาสสิก' บางส่วนที่สนับสนุนนวัตกรรมล่าสุด รวมถึงผลงานที่ใหม่กว่าบางรายการที่กำลังเสนอราคาล่วงหน้าสำหรับ AI Hall of Fame
1: หม้อแปลงไฟฟ้า
ในปี พ.ศ. 2017 Google Research ได้นำความร่วมมือด้านการวิจัยมาสู่จุดสูงสุด กระดาษ ความสนใจคือสิ่งที่คุณต้องการ. งานนี้นำเสนอสถาปัตยกรรมใหม่ที่ส่งเสริม กลไกความสนใจ ตั้งแต่ 'piping' ในตัวเข้ารหัส/ตัวถอดรหัสและโมเดลเครือข่ายแบบเกิดซ้ำ ไปจนถึงเทคโนโลยีการเปลี่ยนแปลงศูนย์กลางในแบบของตัวเอง
แนวทางดังกล่าวได้รับการขนานนามว่า หม้อแปลงไฟฟ้าและตั้งแต่นั้นมาก็กลายเป็นระเบียบวิธีปฏิวัติการประมวลผลภาษาธรรมชาติ (NLP) โดยขับเคลื่อนโมเดลภาษาแบบถอยหลังอัตโนมัติและ AI poster-child GPT-3
![]()
Transformers แก้ปัญหาได้อย่างสง่างาม การถ่ายโอนลำดับหรือที่เรียกว่า 'การเปลี่ยนแปลง' ซึ่งเกี่ยวข้องกับการประมวลผลลำดับอินพุตเป็นลำดับเอาต์พุต หม้อแปลงยังรับและจัดการข้อมูลในลักษณะต่อเนื่อง แทนที่จะเป็นชุดต่อเนื่อง ทำให้มี 'การคงอยู่ของหน่วยความจำ' ซึ่งสถาปัตยกรรม RNN ไม่ได้ได้รับการออกแบบมาให้ได้รับ หากต้องการดูรายละเอียดภาพรวมของหม้อแปลงเพิ่มเติม โปรดดูที่ บทความอ้างอิงของเรา.
ตรงกันข้ามกับ Recurrent Neural Networks (RNNs) ที่เริ่มครองการวิจัย ML ในยุค CUDA สถาปัตยกรรม Transformer ก็สามารถทำได้ง่ายเช่นกัน ขนานกันซึ่งเปิดทางให้จัดการกับคลังข้อมูลที่ใหญ่กว่า RNN อย่างมีประสิทธิผล
การใช้งานยอดนิยม
Transformers ดึงดูดจินตนาการของสาธารณชนในปี 2020 ด้วยการเปิดตัว GPT-3 ของ OpenAI ซึ่งทำลายสถิติ 175 พันล้านพารามิเตอร์. ความสำเร็จอันน่าทึ่งที่เห็นได้ชัดนี้ถูกบดบังด้วยโครงการในภายหลัง เช่น ในปี 2021 ปล่อย Megatron-Turing NLG 530B ของ Microsoft ซึ่ง (ตามชื่อแนะนำ) มีพารามิเตอร์มากกว่า 530 พันล้านพารามิเตอร์

ไทม์ไลน์ของโครงการ Transformer NLP ระดับไฮเปอร์สเกล ที่มา: ไมโครซอฟท์
สถาปัตยกรรมหม้อแปลงไฟฟ้าได้ก้าวข้ามจาก NLP ไปสู่คอมพิวเตอร์วิทัศน์ โดยขับเคลื่อน a รุ่นใหม่ ของกรอบการสังเคราะห์ภาพเช่น OpenAI's CLIP และ DALL-Eซึ่งใช้การแมปโดเมนข้อความ>รูปภาพเพื่อทำให้รูปภาพที่ไม่สมบูรณ์เสร็จสมบูรณ์และสังเคราะห์รูปภาพใหม่จากโดเมนที่ผ่านการฝึกอบรม ท่ามกลางแอปพลิเคชันที่เกี่ยวข้องจำนวนมากขึ้นเรื่อยๆ

DALL-E พยายามทำให้ภาพบางส่วนของรูปปั้นครึ่งตัวของเพลโตสมบูรณ์ ที่มา: https://openai.com/blog/dall-e/
2: เครือข่ายปฏิปักษ์ทั่วไป (GAN)
แม้ว่า Transformers จะได้รับการรายงานข่าวจากสื่อเป็นพิเศษผ่านการเปิดตัวและการนำ GPT-3 มาใช้ เครือข่ายผู้ให้กำเนิด (GAN) ได้กลายเป็นแบรนด์ที่เป็นที่รู้จักและอาจเข้าร่วมในที่สุด deepfake เป็นคำกริยา
เสนอครั้งแรก ใน 2014 และใช้เป็นหลักในการสังเคราะห์ภาพ เครือข่ายผู้ก่อความไม่สงบ สถาปัตยกรรม ประกอบด้วยไฟล์ เครื่องกำเนิดไฟฟ้า และ ผู้เลือกปฏิบัติ. ตัวสร้างวนรอบภาพหลายพันภาพในชุดข้อมูล ซ้ำแล้วซ้ำอีกพยายามสร้างภาพเหล่านั้นใหม่ สำหรับความพยายามแต่ละครั้ง Discriminator จะให้คะแนนการทำงานของ Generator และส่ง Generator กลับไปเพื่อให้ทำงานได้ดีขึ้น แต่ไม่มีข้อมูลเชิงลึกเกี่ยวกับวิธีการสร้างใหม่ครั้งก่อนผิดพลาด

ที่มา: https://developers.google.com/machine-learning/gan/gan_structure
สิ่งนี้บังคับให้ Generator ต้องสำรวจลู่ทางหลายหลาก แทนที่จะเดินตามตรอกซอกซอยที่อาจเกิดขึ้นได้ ซึ่งจะมีผลถ้า Discriminator บอกว่าเกิดข้อผิดพลาดตรงไหน (ดู #8 ด้านล่าง) เมื่อการฝึกอบรมสิ้นสุดลง Generator จะมีแผนผังความสัมพันธ์ระหว่างจุดต่างๆ ในชุดข้อมูลอย่างละเอียดและครอบคลุม

จากกระดาษ การปรับปรุงสมดุล GAN โดยเพิ่มความตระหนักเชิงพื้นที่: เฟรมเวิร์กใหม่วนผ่านพื้นที่ซ่อนเร้นที่ลึกลับในบางครั้งของ GAN มอบเครื่องมือที่ตอบสนองต่อสถาปัตยกรรมการสังเคราะห์ภาพ ที่มา: https://genforce.github.io/eqgan/
โดยการเปรียบเทียบ นี่คือความแตกต่างระหว่างการเรียนรู้การเดินทางอันน่าเบื่อเพียงครั้งเดียวไปยังใจกลางกรุงลอนดอน หรือการแสวงหาอย่างเพียรพยายาม ความรู้.
ผลที่ได้คือชุดคุณสมบัติระดับสูงในพื้นที่แฝงของโมเดลที่ผ่านการฝึกอบรม ตัวบ่งชี้ความหมายสำหรับคุณลักษณะระดับสูงอาจเป็น 'บุคคล' ในขณะที่การสืบเชื้อสายมาจากความเฉพาะเจาะจงที่เกี่ยวข้องกับคุณลักษณะนี้อาจเปิดเผยคุณลักษณะที่เรียนรู้อื่นๆ เช่น 'เพศชาย' และ 'เพศหญิง' ในระดับที่ต่ำกว่า คุณสมบัติย่อยสามารถแบ่งออกเป็น 'ผมบลอนด์' 'คนผิวขาว' และอื่น ๆ
พัวพันคือ ประเด็นที่น่าสังเกต ในพื้นที่ซ่อนเร้นของ GAN และเฟรมเวิร์กตัวเข้ารหัส/ตัวถอดรหัส: รอยยิ้มบนใบหน้าของผู้หญิงที่สร้างโดย GAN เป็นคุณลักษณะที่พัวพันของ 'ตัวตน' ของเธอในพื้นที่แฝง หรือเป็นสาขาคู่ขนานกัน

ใบหน้าที่สร้างโดย GAN จากบุคคลนี้ไม่มีอยู่จริง ที่มา: https://this-person-does-not-exist.com/en
สองสามปีที่ผ่านมาได้ก่อให้เกิดการริเริ่มการวิจัยใหม่จำนวนมากขึ้นในส่วนนี้ บางทีอาจเป็นการปูทางสำหรับการแก้ไขสไตล์ Photoshop ระดับคุณลักษณะสำหรับพื้นที่แฝงของ GAN แต่ในขณะนี้ การเปลี่ยนแปลงหลายอย่างมีประสิทธิภาพ ' แพ็คเกจทั้งหมดหรือไม่มีอะไรเลย โดยเฉพาะอย่างยิ่ง การเปิดตัว EditGAN ของ NVIDIA ในช่วงปลายปี 2021 บรรลุผลสำเร็จ ความสามารถในการตีความในระดับสูง ในพื้นที่แฝงโดยใช้มาสก์การแบ่งส่วนความหมาย
การใช้งานยอดนิยม
นอกเหนือจากการมีส่วนร่วม (จริง ๆ แล้วค่อนข้างจำกัด) ในวิดีโอ Deepfake ยอดนิยมแล้ว GAN ที่เน้นภาพ/วิดีโอเป็นศูนย์กลางได้เพิ่มจำนวนมากขึ้นในช่วงสี่ปีที่ผ่านมา ทำให้นักวิจัยและสาธารณชนหลงใหล การติดตามอัตราการเวียนหัวและความถี่ของการเผยแพร่ใหม่เป็นสิ่งที่ท้าทาย แม้ว่าพื้นที่เก็บข้อมูล GitHub แอปพลิเคชั่น GAN ที่ยอดเยี่ยม มีวัตถุประสงค์เพื่อให้รายการที่ครอบคลุม
ตามทฤษฎีแล้ว Generative Adversarial Networks สามารถรับคุณสมบัติมาจากโดเมนที่มีกรอบที่ดี รวมทั้งข้อความ.
3: เอสวีเอ็ม
มีต้นกำเนิด ใน 1963, สนับสนุนเครื่องเวกเตอร์ (SVM) เป็นอัลกอริทึมหลักที่เกิดขึ้นบ่อยครั้งในการวิจัยใหม่ ภายใต้ SVM เวกเตอร์แมปการจัดการสัมพัทธ์ของจุดข้อมูลในชุดข้อมูล ในขณะที่ สนับสนุน เวกเตอร์กำหนดขอบเขตระหว่างกลุ่ม คุณลักษณะ หรือลักษณะต่างๆ
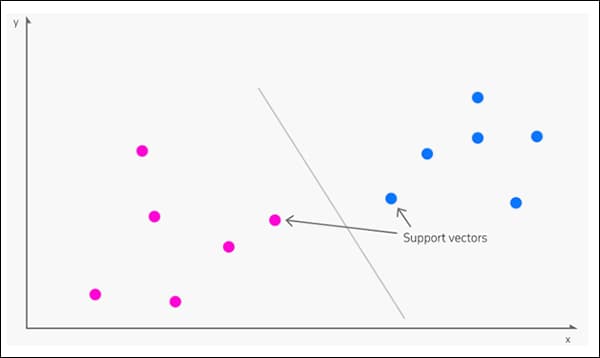
เวกเตอร์สนับสนุนกำหนดขอบเขตระหว่างกลุ่ม ที่มา: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
ขอบเขตที่ได้รับเรียกว่า ไฮเปอร์เพลน.
ในระดับคุณสมบัติต่ำ SVM คือ สองมิติ (ภาพด้านบน) แต่เมื่อมีจำนวนกลุ่มหรือประเภทที่เป็นที่รู้จักมากขึ้น ก็จะกลายเป็น สามมิติ.

อาร์เรย์ของจุดและกลุ่มที่ลึกขึ้นจำเป็นต้องมี SVM สามมิติ ที่มา: https://cml.rhul.ac.uk/svm.html
การใช้งานยอดนิยม
เนื่องจากการรองรับ Vector Machines สามารถจัดการกับข้อมูลมิติสูงหลายประเภทได้อย่างมีประสิทธิภาพและไม่เชื่อเรื่องพระเจ้า พวกเขาจึงขยายขอบเขตอย่างกว้างขวางในภาคส่วนการเรียนรู้ของเครื่องที่หลากหลาย รวมถึง การตรวจจับลึกปลอม, การจำแนกภาพ, การจำแนกคำพูดแสดงความเกลียดชัง, การวิเคราะห์ดีเอ็นเอ และ การทำนายโครงสร้างประชากร, หมู่คนอื่น ๆ อีกมากมาย
4: การรวมกลุ่ม K-Mean
การจัดกลุ่มโดยทั่วไปคือ การเรียนรู้โดยไม่ได้รับการดูแล วิธีการที่พยายามจัดหมวดหมู่จุดข้อมูลผ่าน การประมาณค่าความหนาแน่นการสร้างแผนที่การกระจายของข้อมูลที่กำลังศึกษา

K-Means รวมกลุ่มเทพ กลุ่ม และชุมชนในข้อมูล ที่มา: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-หมายถึงการจัดกลุ่ม ได้กลายเป็นแนวทางที่ได้รับความนิยมมากที่สุด โดยต้อนจุดข้อมูลให้เป็น 'K Groups' ที่โดดเด่น ซึ่งอาจระบุภาคส่วนประชากรศาสตร์ ชุมชนออนไลน์ หรือการรวบรวมข้อมูลลับที่เป็นไปได้อื่นๆ ที่รอการค้นพบในข้อมูลทางสถิติดิบ

รูปแบบกลุ่มในการวิเคราะห์ K-Means ที่มา: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
ค่า K เองเป็นปัจจัยที่กำหนดในยูทิลิตี้ของกระบวนการ และในการสร้างค่าที่เหมาะสมที่สุดสำหรับคลัสเตอร์ ในขั้นต้น ค่า K จะถูกกำหนดแบบสุ่ม และคุณสมบัติและลักษณะของเวกเตอร์เมื่อเปรียบเทียบกับค่าใกล้เคียง เพื่อนบ้านเหล่านั้นที่ใกล้เคียงกับจุดข้อมูลมากที่สุดด้วยค่าที่กำหนดแบบสุ่มจะได้รับการกำหนดให้กับคลัสเตอร์ของมันซ้ำ ๆ จนกว่าข้อมูลจะให้การจัดกลุ่มทั้งหมดที่กระบวนการอนุญาต
พล็อตสำหรับข้อผิดพลาดกำลังสองหรือ 'ต้นทุน' ของค่าที่แตกต่างกันระหว่างกลุ่มจะเปิดเผย จุดข้อศอก สำหรับข้อมูล:

'จุดข้อศอก' ในกราฟคลัสเตอร์ ที่มา: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
จุดหักศอกมีแนวคิดที่คล้ายคลึงกันกับวิธีที่การสูญเสียลดลงไปจนถึงผลตอบแทนที่ลดลงเมื่อสิ้นสุดเซสชันการฝึกอบรมสำหรับชุดข้อมูล แสดงถึงจุดที่จะไม่มีความแตกต่างระหว่างกลุ่มอีกต่อไป ซึ่งบ่งชี้ถึงช่วงเวลาที่จะไปยังขั้นตอนต่อไปในท่อส่งข้อมูล หรืออื่นๆ เพื่อรายงานสิ่งที่ค้นพบ
การใช้งานยอดนิยม
ด้วยเหตุผลที่ชัดเจน K-Means Clustering เป็นเทคโนโลยีหลักในการวิเคราะห์ลูกค้า เนื่องจากมีวิธีการที่ชัดเจนและอธิบายได้เพื่อแปลบันทึกการค้าจำนวนมากเป็นข้อมูลเชิงลึกด้านประชากรศาสตร์และ 'ลูกค้าเป้าหมาย'
นอกเหนือจากแอปพลิเคชันนี้ K-Means Clustering ยังถูกใช้สำหรับ การทำนายแผ่นดินถล่ม, การแบ่งส่วนภาพทางการแพทย์, การสังเคราะห์ภาพด้วย GAN, การจำแนกเอกสารและ การวางผังเมืองท่ามกลางศักยภาพและการใช้งานจริงอื่นๆ อีกมากมาย
5: ป่าสุ่ม
ป่าสุ่มเป็น การเรียนรู้ทั้งมวล วิธีการที่เฉลี่ยผลลัพธ์จากอาร์เรย์ของ ต้นไม้ตัดสินใจ เพื่อสร้างการคาดการณ์โดยรวมสำหรับผลลัพธ์

ที่มา: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
หากคุณได้ค้นคว้ามันแม้แต่น้อยจากการเฝ้าดู กลับไปสู่อนาคต ไตรภาค ซึ่งเป็นแผนผังการตัดสินใจนั้นค่อนข้างง่ายที่จะกำหนดกรอบความคิด: เส้นทางจำนวนหนึ่งอยู่ตรงหน้าคุณ และแต่ละเส้นทางก็แตกแขนงออกไปสู่ผลลัพธ์ใหม่ ซึ่งในทางกลับกันก็มีเส้นทางที่เป็นไปได้เพิ่มเติม
In การเรียนรู้การเสริมแรงคุณอาจล่าถอยจากเส้นทางและเริ่มต้นใหม่อีกครั้งจากท่าทางก่อนหน้า ในขณะที่ต้นไม้การตัดสินใจมุ่งมั่นกับการเดินทางของพวกเขา
ดังนั้นอัลกอริธึม Random Forest จึงเป็นการเดิมพันแบบกระจายสำหรับการตัดสินใจ อัลกอริทึมนี้เรียกว่า 'สุ่ม' เพราะมันสร้าง เฉพาะกิจ การเลือกและการสังเกตเพื่อให้เข้าใจถึง มัธยฐาน ผลรวมของผลลัพธ์จากอาร์เรย์แผนผังการตัดสินใจ
เนื่องจากต้องคำนึงถึงปัจจัยหลายหลาก วิธีการ Random Forest จึงแปลงเป็นกราฟที่มีความหมายได้ยากกว่าแผนผังการตัดสินใจ แต่มีแนวโน้มที่จะให้ประสิทธิผลมากกว่าอย่างเห็นได้ชัด
ต้นไม้การตัดสินใจขึ้นอยู่กับความเหมาะสมมากเกินไป ซึ่งผลลัพธ์ที่ได้จะเป็นข้อมูลเฉพาะและไม่น่าจะสรุปเป็นภาพรวมได้ การเลือกจุดข้อมูลตามอำเภอใจของ Random Forest ต่อสู้กับแนวโน้มนี้ โดยเจาะลึกถึงแนวโน้มตัวแทนที่มีความหมายและมีประโยชน์ในข้อมูล

การถดถอยของต้นไม้การตัดสินใจ ที่มา: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
การใช้งานยอดนิยม
เช่นเดียวกับอัลกอริธึมหลายรายการในรายการนี้ Random Forest มักจะทำงานเป็นตัวคัดแยกและกรองข้อมูล 'แต่เนิ่นๆ' และด้วยเหตุนี้จึงแสดงข้อมูลในเอกสารการวิจัยใหม่ๆ อย่างสม่ำเสมอ ตัวอย่างของการใช้ Random Forest ได้แก่ การสังเคราะห์ภาพด้วยคลื่นสนามแม่เหล็ก, การทำนายราคา Bitcoin, การแบ่งส่วนสำมะโน, การจัดประเภทข้อความ และ การตรวจจับการฉ้อโกงบัตรเครดิต.
เนื่องจาก Random Forest เป็นอัลกอริทึมระดับต่ำในสถาปัตยกรรมแมชชีนเลิร์นนิง จึงมีส่วนช่วยในประสิทธิภาพของวิธีการระดับต่ำอื่นๆ เช่นเดียวกับอัลกอริทึมการแสดงภาพ รวมถึง การรวมกลุ่มแบบอุปนัย, การแปลงคุณสมบัติการจัดประเภทของเอกสารข้อความ ใช้คุณสมบัติเบาบางและ แสดงท่อ.
6: ไร้เดียงสา เบยส์
ควบคู่ไปกับการประมาณค่าความหนาแน่น (ดู 4, เหนือ) ก เบยส์ไร้เดียงสา ตัวแยกประเภทเป็นอัลกอริทึมที่ทรงพลังแต่ค่อนข้างเบาที่สามารถประเมินความน่าจะเป็นตามคุณสมบัติที่คำนวณได้ของข้อมูล

คุณลักษณะความสัมพันธ์ในตัวแยกประเภท Bayes ไร้เดียงสา ที่มา: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
คำว่า 'ไร้เดียงสา' หมายถึงสมมติฐานใน ทฤษฎีบทของเบส์ คุณลักษณะที่ไม่เกี่ยวข้องกันเรียกว่า ความเป็นอิสระตามเงื่อนไข. หากคุณยอมรับจุดยืนนี้ การเดินและพูดเหมือนเป็ดนั้นไม่เพียงพอที่จะพิสูจน์ว่าเรากำลังจัดการกับเป็ด และไม่มีการสันนิษฐานที่ 'ชัดเจน' ก่อนเวลาอันควร
ความเข้มงวดทางวิชาการและการสืบสวนในระดับนี้จะเกินความจำเป็นหากมี 'สามัญสำนึก' แต่เป็นมาตรฐานที่มีค่าเมื่อสำรวจความคลุมเครือจำนวนมากและความสัมพันธ์ที่อาจไม่เกี่ยวข้องซึ่งอาจมีอยู่ในชุดข้อมูลแมชชีนเลิร์นนิง
ในเครือข่าย Bayesian ดั้งเดิม คุณลักษณะต่างๆ ขึ้นอยู่กับ ฟังก์ชั่นการให้คะแนนรวมถึงความยาวคำอธิบายขั้นต่ำและ การให้คะแนนแบบเบย์ซึ่งสามารถกำหนดข้อจำกัดกับข้อมูลในแง่ของการเชื่อมต่อโดยประมาณที่พบระหว่างจุดข้อมูล และทิศทางการไหลของการเชื่อมต่อเหล่านี้
ลักษณนามว่า Bayes ไร้เดียงสา ตรงกันข้าม ทำงานโดยสันนิษฐานว่าคุณลักษณะของวัตถุหนึ่งๆ นั้นเป็นอิสระต่อกัน จากนั้นจึงใช้ทฤษฎีบทของ Bayes เพื่อคำนวณความน่าจะเป็นของวัตถุหนึ่งๆ ตามคุณลักษณะของมัน
การใช้งานยอดนิยม
ตัวกรอง Naive Bayes เป็นตัวแทนที่ดีใน การทำนายโรคและการจัดหมวดหมู่เอกสาร, การกรองสแปม, การจำแนกความรู้สึก, ระบบผู้แนะนำและ การตรวจจับการฉ้อโกงรวมถึงแอปพลิเคชันอื่น ๆ
7: K- เพื่อนบ้านที่ใกล้ที่สุด (KNN)
เสนอครั้งแรกโดย US Air Force School of Aviation Medicine ใน 1951และต้องปรับตัวให้เข้ากับฮาร์ดแวร์คอมพิวเตอร์ที่ล้ำสมัยในช่วงกลางศตวรรษที่ 20 K-เพื่อนบ้านที่ใกล้ที่สุด (KNN) เป็นอัลกอริทึมแบบลีนที่ยังคงโดดเด่นในเอกสารทางวิชาการและการริเริ่มการวิจัยการเรียนรู้ด้วยเครื่องของภาคเอกชน
KNN ถูกเรียกว่า 'ผู้เรียนรู้ที่ขี้เกียจ' เนื่องจากมันสแกนชุดข้อมูลอย่างละเอียดถี่ถ้วนเพื่อประเมินความสัมพันธ์ระหว่างจุดข้อมูล แทนที่จะต้องการการฝึกอบรมโมเดลแมชชีนเลิร์นนิงเต็มรูปแบบ

การจัดกลุ่ม KNN แหล่งที่มา: https://scikit-learn.org/stable/modules/neighbors.html
แม้ว่า KNN จะมีรูปทรงเพรียวบางทางสถาปัตยกรรม แต่วิธีการที่เป็นระบบทำให้เกิดความต้องการที่โดดเด่นในการดำเนินการอ่าน/เขียน และการใช้งานในชุดข้อมูลขนาดใหญ่มากอาจเป็นปัญหาได้หากไม่มีเทคโนโลยีเสริม เช่น Principal Component Analysis (PCA) ซึ่งสามารถแปลงชุดข้อมูลที่ซับซ้อนและมีปริมาณมากได้ เข้าไปข้างใน การแบ่งกลุ่มตัวแทน ที่ KNN สามารถเคลื่อนที่ได้โดยใช้ความพยายามน้อยลง
A ผลการศึกษาล่าสุด ประเมินประสิทธิภาพและความประหยัดของอัลกอริธึมจำนวนมากที่ได้รับมอบหมายให้คาดการณ์ว่าพนักงานจะลาออกจากบริษัทหรือไม่ โดยพบว่า KNN ที่เก็บกักน้ำยังคงเหนือกว่าคู่แข่งสมัยใหม่ในแง่ของความแม่นยำและประสิทธิภาพในการทำนาย
การใช้งานยอดนิยม
สำหรับแนวคิดและการดำเนินการที่เรียบง่ายยอดนิยม KNN ไม่ได้ติดอยู่ในยุค 1950 – มันถูกดัดแปลงให้เป็น แนวทางที่เน้น DNN มากขึ้น ในข้อเสนอปี 2018 โดย Pennsylvania State University และยังคงเป็นกระบวนการกลางขั้นต้น (หรือเครื่องมือวิเคราะห์หลังการประมวลผล) ในกรอบการเรียนรู้ของเครื่องที่ซับซ้อนกว่ามาก
ในการกำหนดค่าต่างๆ KNN ถูกนำมาใช้หรือสำหรับ การตรวจสอบลายเซ็นออนไลน์, การจำแนกภาพ, การขุดข้อความ, การทำนายพืชผลและ การจดจำใบหน้านอกเหนือจากแอปพลิเคชันและองค์กรอื่นๆ

ระบบจดจำใบหน้าที่ใช้ KNN ในการฝึกอบรม Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: กระบวนการตัดสินใจของมาร์คอฟ (MDP)
กรอบทางคณิตศาสตร์ที่นำเสนอโดย Richard Bellman นักคณิตศาสตร์ชาวอเมริกัน ใน 1957, Markov Decision Process (MDP) เป็นหนึ่งในบล็อกพื้นฐานที่สุดของ การเรียนรู้การเสริมแรง สถาปัตยกรรม อัลกอริทึมเชิงแนวคิดในตัวของมันเอง ได้รับการดัดแปลงเป็นอัลกอริทึมอื่นๆ จำนวนมาก และเกิดขึ้นซ้ำบ่อยครั้งในการวิจัย AI/ML ในปัจจุบัน
MDP สำรวจสภาพแวดล้อมของข้อมูลโดยใช้การประเมินสถานะปัจจุบัน (เช่น 'ตำแหน่ง' ที่อยู่ในข้อมูล) เพื่อตัดสินใจว่าโหนดใดของข้อมูลที่จะสำรวจต่อไป

ที่มา: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
กระบวนการตัดสินใจขั้นพื้นฐานของมาร์คอฟจะให้ความสำคัญกับความได้เปรียบในระยะสั้นมากกว่าวัตถุประสงค์ระยะยาวที่ต้องการมากกว่า ด้วยเหตุผลนี้ มักจะฝังอยู่ในบริบทของสถาปัตยกรรมนโยบายที่ครอบคลุมมากขึ้นในการเรียนรู้แบบเสริมแรง และมักจะอยู่ภายใต้ปัจจัยจำกัดเช่น รางวัลส่วนลดและตัวแปรสภาพแวดล้อมอื่น ๆ ที่ปรับเปลี่ยนซึ่งจะป้องกันไม่ให้เร่งรีบไปสู่เป้าหมายทันทีโดยไม่คำนึงถึงผลลัพธ์ที่ต้องการในวงกว้าง
การใช้งานยอดนิยม
แนวคิดระดับต่ำของ MDP แพร่หลายทั้งในการวิจัยและการใช้งานแมชชีนเลิร์นนิง มันถูกเสนอให้ ระบบป้องกันความปลอดภัย IoT, การเก็บเกี่ยวปลาและ การคาดการณ์ตลาด.
นอกจากมัน การบังคับใช้ที่ชัดเจน สำหรับหมากรุกและเกมต่อเนื่องที่เคร่งครัดอื่นๆ MDP ยังเป็นคู่แข่งโดยธรรมชาติสำหรับ การฝึกอบรมขั้นตอนของระบบหุ่นยนต์อย่างที่เราเห็นในวิดีโอด้านล่าง

9: ความถี่เอกสารความถี่คำผกผัน
ระยะความถี่ (TF) หารจำนวนครั้งที่คำปรากฏในเอกสารด้วยจำนวนคำทั้งหมดในเอกสารนั้น ด้วยประการฉะนี้ คำว่า ประทับตรา ปรากฏหนึ่งครั้งในบทความหนึ่งพันคำมีความถี่ของคำเท่ากับ 0.001 โดยตัวของมันเอง TF นั้นไร้ประโยชน์โดยมากในฐานะตัวบ่งชี้ความสำคัญของคำศัพท์ เนื่องจากข้อเท็จจริงที่ว่าบทความที่ไม่มีความหมาย (เช่น a, และ , และ it) ครอบงำ
เพื่อให้ได้ค่าที่มีความหมายสำหรับคำศัพท์ Inverse Document Frequency (IDF) จะคำนวณ TF ของคำในเอกสารหลายชุดในชุดข้อมูล โดยให้คะแนนต่ำเป็นความถี่สูงมาก คำหยุดเช่นบทความ. เวกเตอร์คุณลักษณะที่เป็นผลลัพธ์จะถูกทำให้เป็นมาตรฐานเป็นค่าทั้งหมด โดยแต่ละคำจะกำหนดน้ำหนักที่เหมาะสม

TF-IDF ให้น้ำหนักความเกี่ยวข้องของคำศัพท์โดยพิจารณาจากความถี่ของเอกสารหลายฉบับ โดยมีตัวบ่งชี้ความเด่นชัดที่เกิดขึ้นได้ยากกว่า ที่มา: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
แม้ว่าวิธีการนี้จะป้องกันไม่ให้คำสำคัญทางความหมายสูญหายไป ค่าผิดปกติการกลับค่าน้ำหนักความถี่ไม่ได้หมายความว่าคำที่มีความถี่ต่ำนั้นโดยอัตโนมัติ ไม่ ผิดปกติเพราะบางสิ่งหายาก และ ไร้ค่า ดังนั้นคำที่มีความถี่ต่ำจะต้องพิสูจน์คุณค่าของมันในบริบททางสถาปัตยกรรมที่กว้างขึ้นโดยนำเสนอ (แม้ในความถี่ต่ำต่อเอกสาร) ในเอกสารจำนวนหนึ่งในชุดข้อมูล
แม้จะมี อายุTF-IDF เป็นวิธีที่มีประสิทธิภาพและเป็นที่นิยมสำหรับการกรองเริ่มต้นในเฟรมเวิร์กการประมวลผลภาษาธรรมชาติ
การใช้งานยอดนิยม
เนื่องจาก TF-IDF ได้มีส่วนร่วมอย่างน้อยในการพัฒนาอัลกอริธึม PageRank ที่ลึกลับของ Google ในช่วงยี่สิบปีที่ผ่านมา มันจึงกลายเป็น นำมาใช้กันอย่างแพร่หลาย เป็นกลยุทธ์ SEO ที่บิดเบือน ทั้งๆ ที่ในปี 2019 ของ John Mueller การปฏิเสธ ความสำคัญต่อผลการค้นหา
เนื่องจากความลับเกี่ยวกับ PageRank จึงไม่มีหลักฐานที่ชัดเจนว่า TF-IDF คืออะไร ไม่ ปัจจุบันเป็นกลยุทธ์ที่มีประสิทธิภาพในการเพิ่มอันดับของ Google ผู้ก่อความไม่สงบ การสนทนา ในหมู่ผู้เชี่ยวชาญด้าน IT เมื่อเร็ว ๆ นี้บ่งชี้ถึงความเข้าใจที่เป็นที่นิยม ถูกต้องหรือไม่ว่าการใช้คำในทางที่ผิดอาจยังส่งผลให้ตำแหน่ง SEO ดีขึ้น (แม้ว่าจะเพิ่มเติม ข้อกล่าวหาการละเมิดการผูกขาด และ โฆษณาเกินจริง เบลอขอบเขตของทฤษฎีนี้)
10: โคตรลาดสุ่ม
โคตรลาดสุ่ม (SGD) เป็นวิธีที่ได้รับความนิยมมากขึ้นในการเพิ่มประสิทธิภาพการฝึกอบรมโมเดลแมชชีนเลิร์นนิง
Gradient Descent เป็นวิธีการเพิ่มประสิทธิภาพและจากนั้นจึงวัดปริมาณการปรับปรุงที่โมเดลทำระหว่างการฝึก
ในแง่นี้ 'การไล่ระดับสี' บ่งบอกถึงความลาดเอียงลง (แทนที่จะเป็นการไล่ระดับสี โปรดดูภาพด้านล่าง) โดยที่จุดสูงสุดของ 'เนินเขา' ทางด้านซ้าย แสดงถึงจุดเริ่มต้นของกระบวนการฝึกอบรม ในขั้นตอนนี้ แบบจำลองยังไม่เห็นข้อมูลทั้งหมดแม้แต่ครั้งเดียว และยังไม่ได้เรียนรู้เพียงพอเกี่ยวกับความสัมพันธ์ระหว่างข้อมูลเพื่อสร้างการแปลงที่มีประสิทธิภาพ

การไล่ระดับสีลงมาในเซสชั่นการฝึก FaceSwap เราจะเห็นว่าการฝึกซ้อมมีที่ราบมาช่วงหนึ่งในช่วงครึ่งหลัง แต่ในที่สุดก็ฟื้นตัวขึ้นตามระดับความลาดเอียงไปสู่การบรรจบกันที่ยอมรับได้
จุดต่ำสุดทางด้านขวาแสดงถึงการบรรจบกัน (จุดที่แบบจำลองมีประสิทธิภาพที่สุดเท่าที่จะเป็นไปได้ภายใต้ข้อจำกัดและการตั้งค่าที่กำหนด)
การไล่ระดับสีทำหน้าที่เป็นบันทึกและทำนายความแตกต่างระหว่างอัตราข้อผิดพลาด (ความแม่นยำที่แบบจำลองได้แมปความสัมพันธ์ของข้อมูลในปัจจุบัน) และน้ำหนัก (การตั้งค่าที่มีอิทธิพลต่อวิธีที่แบบจำลองจะเรียนรู้)
บันทึกความคืบหน้านี้สามารถใช้เพื่อแจ้ง ตารางอัตราการเรียนรู้ซึ่งเป็นกระบวนการอัตโนมัติที่บอกให้สถาปัตยกรรมมีความละเอียดและแม่นยำมากขึ้น เนื่องจากรายละเอียดที่คลุมเครือในช่วงแรกเปลี่ยนเป็นความสัมพันธ์และการแมปที่ชัดเจน ผลที่ตามมาคือ การไล่ระดับสี (Gradient Loss) จะแสดงแผนที่แบบทันท่วงทีว่าการฝึกควรดำเนินต่อไปที่ใด และควรดำเนินการอย่างไร
นวัตกรรมของ Stochastic Gradient Descent คือการอัปเดตพารามิเตอร์ของแบบจำลองในแต่ละตัวอย่างการฝึกอบรมต่อการวนซ้ำ ซึ่งโดยทั่วไปจะเพิ่มความเร็วในการเดินทางสู่การบรรจบกัน เนื่องจากการกำเนิดของชุดข้อมูลแบบไฮเปอร์สเกลในช่วงไม่กี่ปีที่ผ่านมา SGD ได้รับความนิยมเพิ่มขึ้นเมื่อเร็ว ๆ นี้โดยเป็นวิธีการหนึ่งที่เป็นไปได้ในการแก้ไขปัญหาด้านลอจิสติกส์ที่ตามมา
ในทางกลับกัน SGD มี ผลกระทบเชิงลบ สำหรับการปรับขนาดคุณลักษณะ และอาจต้องมีการทำซ้ำมากขึ้นเพื่อให้ได้ผลลัพธ์เดียวกัน โดยต้องมีการวางแผนเพิ่มเติมและพารามิเตอร์เพิ่มเติม เมื่อเทียบกับ Gradient Descent ปกติ
การใช้งานยอดนิยม
เนื่องจากความสามารถในการกำหนดค่าและแม้จะมีข้อบกพร่อง SGD จึงกลายเป็นอัลกอริธึมการปรับให้เหมาะสมที่ได้รับความนิยมสูงสุดสำหรับการติดตั้งโครงข่ายประสาทเทียม การกำหนดค่าหนึ่ง SGD ที่กำลังโดดเด่นในเอกสารการวิจัย AI/ML ใหม่คือตัวเลือกของ Adaptive Moment Estimation (ADAM, แนะนำ ใน 2015) เครื่องมือเพิ่มประสิทธิภาพ
ADAM ปรับอัตราการเรียนรู้สำหรับแต่ละพารามิเตอร์แบบไดนามิก ('อัตราการเรียนรู้ที่ปรับเปลี่ยน') รวมถึงรวมผลลัพธ์จากการอัปเดตก่อนหน้าเข้ากับการกำหนดค่าที่ตามมา ('โมเมนตัม') นอกจากนี้ยังสามารถกำหนดค่าให้ใช้นวัตกรรมใหม่ในภายหลัง เช่น เนสเตรอฟ โมเมนตัม.
อย่างไรก็ตาม บางคนยืนยันว่าการใช้โมเมนตัมสามารถเพิ่มความเร็ว ADAM (และอัลกอริธึมที่คล้ายกัน) ให้เป็น ข้อสรุปย่อยที่เหมาะสม. เช่นเดียวกับส่วนที่ขาดเลือดออกส่วนใหญ่ของภาคส่วนการวิจัยการเรียนรู้ของเครื่อง SGD ก็อยู่ในระหว่างดำเนินการ
เผยแพร่ครั้งแรกเมื่อวันที่ 10 กุมภาพันธ์ 2022 แก้ไขเมื่อวันที่ 10 กุมภาพันธ์ 20.05 EET – การจัดรูปแบบ















