ปัญญาประดิษฐ์
AI ช่วยให้ผู้พูดที่มีความกังวล ‘อ่านห้อง’ ระหว่างการประชุมทางวิดีโอ

ในปี 2013 การสำรวจเกี่ยวกับภาวะกลัวทั่วไปพบว่าความกังวลในการพูดต่อหน้าผู้คนนั้นแย่กว่าความกังวลในการตายสำหรับผู้ตอบแบบสอบถามส่วนใหญ่ ภาวะนี้เรียกว่า glossophobia
การย้ายจากการประชุม “ต่อหน้า” ไปยังการประชุมวิดีโอออนไลน์บนแพลตฟอร์ม เช่น Zoom และ Google Spaces ซึ่งได้รับแรงผลักดันจาก COVID-19 ไม่ได้ปรับปรุงสถานการณ์ เมื่อมีผู้เข้าร่วมจำนวนมาก ความสามารถในการประเมินภัยคุกคามตามธรรมชาติของเราจะถูกขัดขวางโดยแถวและไอคอนของผู้เข้าร่วมที่มีความละเอียดต่ำ และความยากในการอ่านสัญญาณภาพที่ละเอียดอ่อนของน้ำเสียงและภาษากาย การใช้ Skype เป็นต้น ถูกพบว่าเป็นแพลตฟอร์มที่ไม่ดีสำหรับการส่งสัญญาณที่ไม่ใช่คำพูด
ผลกระทบต่อประสิทธิภาพการพูดต่อหน้าผู้คนของการรับรู้ถึงความสนใจและความตอบสนองถูกบันทึกไว้อย่างดีแล้ว และเห็นได้ชัดเจนสำหรับเรา สัญญาณตอบรับจากผู้ฟังที่ไม่ชัดเจนสามารถทำให้ผู้พูดลังเลและกลายเป็นคำพูดที่ไม่จำเป็น โดยไม่รู้ว่าข้อโต้แย้งของพวกเขากำลังได้รับการตกลงรับ การดูถูก หรือการไม่สนใจ ซึ่งบ่อยครั้งทำให้เกิดประสบการณ์ที่ไม่สบายใจสำหรับทั้งผู้พูดและผู้ฟัง
ภายใต้แรงกดดันจากการเปลี่ยนแปลงที่ไม่คาดคิดไปสู่การประชุมวิดีโอออนไลน์ ซึ่งได้รับแรงผลักดันจากข้อจำกัดและมาตรการป้องกัน COVID-19 ปัญหานี้อาจแย่ลง และมีการเสนอระบบการให้ข้อมูลย้อนกลับจากผู้ฟังหลายระบบในชุมชนการวิจัยด้านการมองเห็นและอารมณ์ในช่วงสองสามปีที่ผ่านมา
วิธีแก้ปัญหาที่เน้นฮาร์ดแวร์
ส่วนใหญ่ของวิธีแก้ปัญหาเหล่านี้ต้องใช้อุปกรณ์เสริมหรือซอฟต์แวร์ที่ซับซ้อน ซึ่งสามารถทำให้เกิดปัญหาเกี่ยวกับความเป็นส่วนตัวหรือลอจิสติกส์ – วิธีการที่มีค่าใช้จ่ายสูงหรือจำกัดทรัพยากรอื่นๆ ในปี 2001 MIT เสนอ Galvactivator อุปกรณ์ที่สวมมือที่อนุมานสถานะทางอารมณ์ของผู้เข้าร่วม โดยทดสอบระหว่างการประชุมวันเดียว

From 2001, MIT’s Galvactivator, which measured skin conductivity response in an attempt to understand audience sentiment and engagement. Source: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
พลังงานทางวิชาการจำนวนมากได้ถูกอุทิศให้กับการใช้ ‘คลิกเกอร์’ เป็นระบบการตอบรับจากผู้ฟัง (ARS) วิธีการเพิ่มการมีส่วนร่วมอย่างแข็งขันจากผู้ฟัง (ซึ่งเพิ่มการมีส่วนร่วมโดยอัตโนมัติ เนื่องจากบังคับให้ผู้ฟังรับบทบาทเป็นโหนดการให้ข้อมูลย้อนกลับอย่างแข็งขัน) แต่ยังถูกมองว่าเป็นวิธีการเพิ่มความมั่นใจให้กับผู้พูด
ความพยายามอื่นๆ ในการ ‘เชื่อมต่อ’ ผู้พูดและผู้ฟัง ได้แก่ การติดตามอัตราการเต้นของหัวใจ การใช้อุปกรณ์ที่ซับซ้อนเพื่อใช้การวัดคลื่นสมอง ‘มิเตอร์เชียร์’ การรับรู้อารมณ์โดยใช้การวิเคราะห์ภาพบนเดสก์ท็อป และการใช้ไอโมจิจากผู้ฟังระหว่างการกล่าวสุนทรพจน์ของผู้พูด

From 2017, the EngageMeter, a joint academic research project from LMU Munich and the University of Stuttgart. Source: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
ในฐานะส่วนหนึ่งของพื้นที่การวิเคราะห์ผู้ฟังที่มีผลกำไร ส่วนตัวของภาคเอกชนได้ให้ความสนใจเป็นพิเศษในการประมาณการและการติดตามการมอง – ระบบที่ผู้ฟังแต่ละคน (ซึ่งอาจต้องพูดในทางกลับกัน) ถูกติดตามการมองเป็นดัชนีของการมีส่วนร่วมและการอนุมัติ
วิธีการเหล่านี้มีความเสี่ยงสูง มันส่วนใหญ่ต้องใช้อุปกรณ์เสริมหรือซอฟต์แวร์ที่ซับซ้อน ซึ่งสามารถทำให้เกิดปัญหาเกี่ยวกับความเป็นส่วนตัวหรือลอจิสติกส์ – วิธีการที่มีค่าใช้จ่ายสูงหรือจำกัดทรัพยากรอื่นๆ
ดังนั้น การพัฒนาระบบที่มีขนาดเล็กซึ่งใช้เครื่องมือวิดีโอการประชุมทั่วไปจึงได้รับความสนใจในช่วง 18 เดือนที่ผ่านมา
การรายงานการอนุมัติจากผู้ฟังอย่างไม่ชัดเจน
เพื่อจุดประสงค์นี้ การวิจัยร่วมใหม่ระหว่างมหาวิทยาลัยโตเกียวและมหาวิทยาลัยคาร์เนกีเมลลอนเสนอระบบใหม่ที่สามารถใช้งานได้กับเครื่องมือวิดีโอการประชุมมาตรฐาน (เช่น Zoom) โดยใช้เพียงเว็บไซต์ที่มีการติดตามการมองและท่าทางแบบเบาๆ ซึ่งสามารถหลีกเลี่ยงการจำเป็นในการใช้ปลั๊กอินของเบราว์เซอร์ได้
การก้มและความสนใจที่ประมาณการของผู้ฟังจะถูกแปลเป็นข้อมูลที่แสดงให้ผู้พูดเห็น เพื่อให้สามารถทดสอบ ‘สด’ ว่าเนื้อหานั้นได้รับการตอบรับจากผู้ฟังอย่างไร – และยังเป็นตัวบ่งชี้อย่างคร่าวๆ ว่าช่วงเวลาใดที่ผู้พูดอาจสูญเสียความสนใจของผู้ฟัง
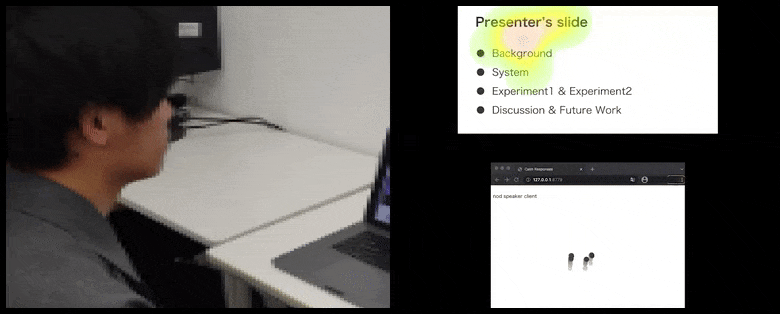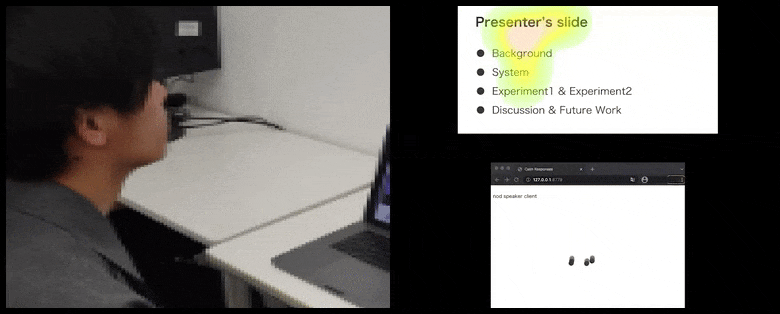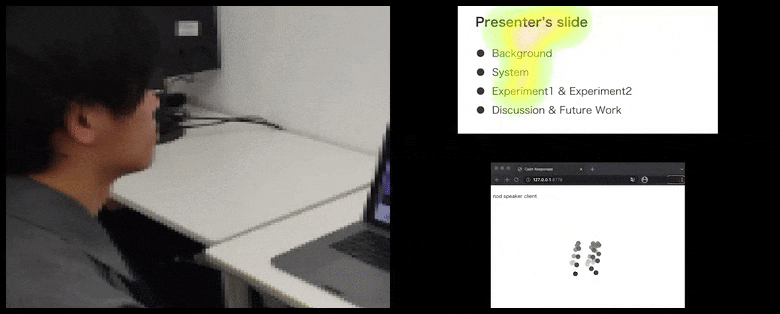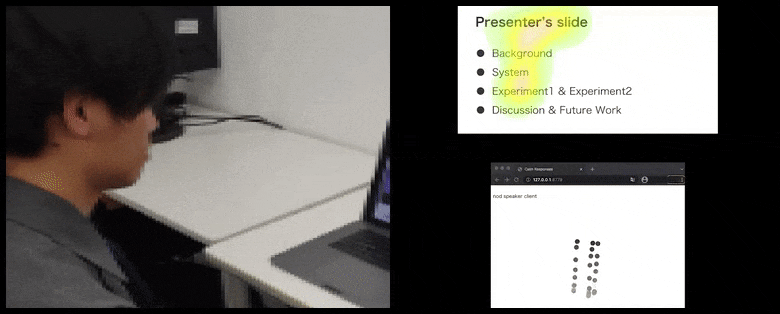
With CalmResponses, user attention and nodding is added to a pool of audience feedback and translated into a visual representation that can benefit the speaker. See embedded video at end of article for more detail and examples. Source: https://www.youtube.com/watch?v=J_PhB4FCzk0
ในหลายๆ สถานการณ์ เช่น การสอนออนไลน์ นักเรียนอาจไม่เห็นได้จากผู้พูด เนื่องจากพวกเขาไม่ได้เปิดกล้องเว็บแคมของตนเองเนื่องจากความกังวลเกี่ยวกับพื้นหลังหรือรูปลักษณ์ปัจจุบัน CalmResponses สามารถแก้ไขอุปสรรคที่ยากลำบากนี้ได้โดยการรายงานสิ่งที่รู้เกี่ยวกับการมองเห็นของผู้พูด และการก้ม โดยไม่ต้องมีการเปิดกล้องของผู้ฟัง
เอกสาร วิจัย มีชื่อเรื่อง CalmResponses: Displaying Collective Audience Reactions in Remote Communication และเป็นผลงานร่วมกันระหว่างนักวิจัยสองคนจาก UoT และหนึ่งคนจาก Carnegie Mellon
ผู้เขียนเสนอตัวอย่างเว็บแบบสดๆ และได้เผยแพร่ โค้ดต้นฉบับบน GitHub
โครงสร้าง CalmResponses
ความสนใจในเรื่องการก้มของ CalmResponses เทียบกับท่าทางอื่นๆ มีฐานะมาจากงานวิจัย (บางส่วนมาจากยุคของดาร์วิน) ที่แสดงว่ามากกว่า 80% ของการเคลื่อนไหวของหัวของผู้ฟังประกอบด้วยการก้ม (แม้ว่าพวกเขาจะ ไม่เห็นด้วย) ในเวลาเดียวกัน การเคลื่อนไหวของการมองได้ถูกแสดงให้เห็นใน หลายๆ การศึกษา ว่าเป็นดัชนีที่เชื่อถือได้ของความสนใจหรือการมีส่วนร่วม
CalmResponses ถูกสร้างขึ้นด้วย HTML, CSS และ JavaScript และประกอบด้วยสามส่วนย่อย: ส่วนย่อยสำหรับผู้ฟัง ส่วนย่อยสำหรับผู้พูด และเซิร์ฟเวอร์ ส่วนย่อยสำหรับผู้ฟังจะส่งผ่านข้อมูลการมองและท่าทางของผู้ฟังจากเว็บแคมผ่าน WebSockets บนแพลตฟอร์ม Heroku

Audience nodding visualized on the right in an animated movement under CalmResponses. In this case the movement visualization is available not only to the speaker, but to the entire audience. Source: https://arxiv.org/pdf/2204.02308.pdf
สำหรับส่วนของการติดตามการมองของโครงการนี้ นักวิจัยใช้ WebGazer ซึ่งเป็นเฟรมเวิร์กการติดตามการมองแบบเบาๆ ที่สามารถทำงานได้โดยตรงจากเว็บไซต์ (ดูลิงก์ด้านบนสำหรับการนำไปใช้ของนักวิจัย)
เนื่องจากความต้องการการนำไปใช้แบบง่ายๆ และการรับรู้การตอบรับแบบรวมมากกว่าความต้องการความแม่นยำสูงในการติดตามการมองและท่าทาง ข้อมูลท่าทางจะถูกทำให้เรียบง่ายตามค่าเฉลี่ยก่อนที่จะถูกพิจารณาในการประมาณการการตอบรับโดยรวม
การก้มจะถูกประเมินผ่านไลบรารี JavaScript clmtrackr ซึ่งสามารถติดตั้งแบบจำลองใบหน้าบนภาพหรือวิดีโอผ่าน การเปลี่ยนแปลงที่มีการควบคุม สำหรับการประหยัดและความเร็วในการตอบสนอง ระบบจะตรวจสอบเฉพาะจุดบนจมูกเท่านั้น
The movement of the user’s nose tip position creates a trail that contributes to the pool of audience response related to nodding, visualized in an aggregate manner to all participants.
แผนที่ความร้อน
ในขณะที่การก้มจะถูกแสดงเป็นจุดเคลื่อนไหวแบบไดนามิก (ดูภาพด้านบนและวิดีโอที่ปลายบทความ) การมองจะถูกแสดงในรูปแบบแผนที่ความร้อน ซึ่งแสดงให้ผู้พูดและผู้ฟังเห็นว่าจุดสนใจทั่วไปอยู่ที่ใดบนจอการนำเสนอหรือสภาพแวดล้อมการประชุมวิดีโอ

All participants can see where general user attention is focused. The paper makes no mention of whether this functionality is available when the user can see a ‘gallery’ of other participants, which could reveal specious focus on one particular participant, for various reasons.
การทดสอบ
สองสภาพแวดล้อมทดสอบถูกสร้างขึ้นสำหรับ CalmResponses ในรูปแบบของการศึกษาแบบ ablation ที่ไม่มีการแทรกแซง โดยใช้สถานการณ์ที่แตกต่างกันสามแบบ: ใน ‘Condition B’ (บรรทัดฐาน) ผู้วิจัยทำซ้ำการบรรยายออนไลน์ทั่วไป โดยที่นักเรียนส่วนใหญ่ปิดกล้องเว็บแคม และผู้พูดไม่สามารถเห็นใบหน้าของผู้ฟัง; ใน ‘Condition CR-E’ ผู้พูดสามารถเห็นการมองของผู้ฟัง (แผนที่ความร้อน); ใน ‘Condition CR-N’ ผู้พูดสามารถเห็นทั้งการก้มและการมองของผู้ฟัง
การทดสอบครั้งแรกประกอบด้วยเงื่อนไข B และ CR-E; การทดสอบครั้งที่สองประกอบด้วยเงื่อนไข B และ CR-N การให้ข้อมูลย้อนกลับได้รับจากทั้งผู้พูดและผู้ฟัง
ในแต่ละการทดลอง มีการประเมินสามปัจจัย: การประเมินแบบเป็น객观และแบบ主观ของการนำเสนอ (รวมถึงแบบสอบถามที่รายงานโดยผู้พูดเกี่ยวกับความรู้สึกเกี่ยวกับการนำเสนอ); จำนวนเหตุการณ์ของ ‘การกล่าวที่ไม่จำเป็น’ ซึ่งบ่งบอกถึงความไม่มั่นใจและลังเล; และคำอธิบายคุณภาพเหล่านี้เป็นตัวชี้วัดที่ ทั่วไป สำหรับการประเมิน คุณภาพของการกล่าวและความกังวลของผู้พูด
กลุ่มทดสอบประกอบด้วยคน 38 คน อายุ 19-44 ปี ประกอบด้วยชาย 29 คนและหญิง 9 คน โดยมีอายุเฉลี่ย 24.7 ปี ทั้งหมดเป็นคนญี่ปุ่นหรือจีน และพูดภาษาญี่ปุ่นได้ฟรี พวกเขาถูกแบ่งออกเป็นห้ากลุ่ม โดยมีผู้เข้าร่วม 6-7 คน และไม่มีใครรู้จักกันส่วนตัว
การทดสอบถูกดำเนินการบน Zoom โดยมีผู้พูดห้าคนในการทดสอบครั้งแรกและหกคนในการทดสอบครั้งที่สอง

Filler conditions marked as orange boxes. In general, filler content fell in reasonable proportion to increased audience feedback from the system.
นักวิจัยสังเกตเห็นว่าผู้พูดหนึ่งคนมีการลดลงอย่างมีนัยสำคัญของการกล่าวที่ไม่จำเป็น และใน ‘Condition CR-N’ ผู้พูดแทบจะไม่กล่าวคำที่ไม่จำเป็นเลย ดูเอกสารสำหรับผลลัพธ์ที่มีรายละเอียดและเป็นกรานูล; อย่างไรก็ตาม ผลลัพธ์ที่เห็นได้ชัดเจนที่สุดคือการประเมินแบบ主观จากผู้พูดและผู้ฟัง
คำอธิบายจากผู้ฟังรวมถึง:
‘I felt that I was involved in the presentations” [AN2], “I was not sure the speakers’ speeches were improved, but I felt a sense of unity from others’ head movements visualization.’ [AN6]
‘I was not sure the speakers’ speeches were improved, but I felt a sense of unity from others’ head movements visualization.’
นักวิจัยสังเกตเห็นว่าระบบนี้แนะนำการหยุดชั่วคราวใหม่เข้ามาในนำเสนอของผู้พูด เนื่องจากผู้พูดมีแนวโน้มที่จะอ้างอิงถึงระบบการมองเห็นเพื่อประเมินการให้ข้อมูลย้อนกลับจากผู้ฟังก่อนที่จะดำเนินการต่อ
พวกเขายังชี้ให้เห็นว่ามี ‘ผลกระทบจากเสื้อคลุมขาว’ ซึ่งยากที่จะหลีกเลี่ยงในสภาพแวดล้อมทดลอง โดยที่ผู้เข้าร่วมบางคนรู้สึกถูกจำกัดโดยผลกระทบด้านความปลอดภัยที่อาจเกิดขึ้นจากการถูกติดตามด้วยข้อมูลไบโอเมตริก
สรุป
ข้อได้เปรียบที่สำคัญของระบบอย่างนี้คือเทคโนโลยีเสริมที่ไม่มาตรฐานทั้งหมดจะหายไปหลังจากใช้งานแล้ว ไม่มีปลั๊กอินของเบราว์เซอร์ที่ต้องถอดออก หรือทำให้ผู้เข้าร่วมสงสัยว่าควรปล่อยให้พวกมันอยู่บนระบบหรือไม่; และไม่มีความจำเป็นที่จะแนะนำผู้ใช้ในการติดตั้ง (แม้ว่าเฟรมเวิร์กบนเว็บจะต้องมีการปรับเทียบเบื้องต้นเพียงหนึ่งหรือสองนาที) หรือที่จะนำทางผู้ใช้ในการติดตั้งซอฟต์แวร์ท้องถิ่น รวมถึงปลั๊กอินและ 익ステนชัน
แม้ว่าการเคลื่อนไหวของใบหน้าและตาที่ประเมินไม่ได้แม่นยำเท่าที่จะเป็นไปได้ในสถานการณ์ที่ใช้เฟรมเวิร์กการเรียนรู้ของเครื่องแบบท้องถิ่น (เช่น ซีรีส์ YOLO) แต่วิธีการที่ไม่มีแรงเสียดทานนี้ในการประเมินผู้ฟังให้ความแม่นยำที่เพียงพอสำหรับการวิเคราะห์ความรู้สึกและทัศนคติในสถานการณ์การประชุมวิดีโอทั่วไป สิ่งสำคัญที่สุดคือมันราคาไม่แพง
ดูวิดีโอที่เกี่ยวข้องด้านล่างสำหรับรายละเอียดและตัวอย่างเพิ่มเติม
First published 11th April 2022.












