AI 101
Czym jest uczenie ze wzmocnieniem?
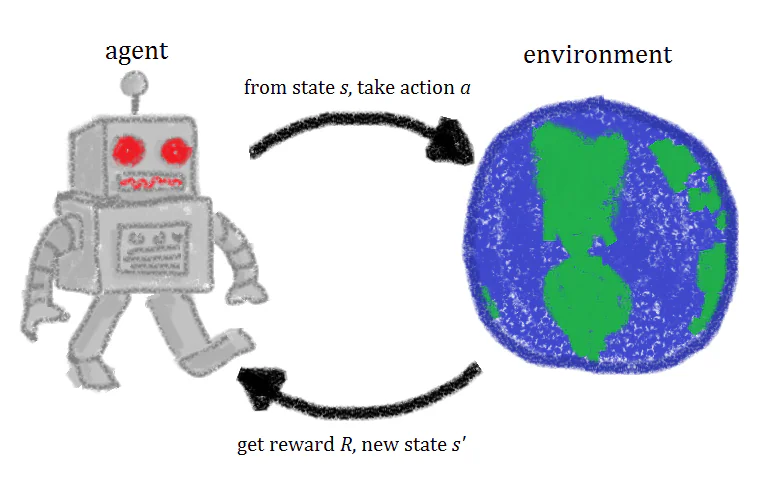
Czym jest uczenie ze wzmocnieniem?
Mówiąc najprościej, uczenie ze wzmocnieniem to technika uczenia maszynowego, która polega na trenowaniu sztucznego agenta inteligencji poprzez powtarzanie akcji i związanych z nimi nagród. Agent uczący się ze wzmocnieniem eksperymentuje w środowisku, podejmując działania i otrzymując nagrody, gdy podejmie właściwe akcje. Z czasem agent uczy się podejmować działania, które zmaksymalizują jego nagrodę. To szybka definicja uczenia ze wzmocnieniem, ale przyjrzenie się bliżej koncepcjom stojącym za uczeniem ze wzmocnieniem pomoże ci uzyskać lepsze, bardziej intuicyjne jego zrozumienie. Termin „uczenie ze wzmocnieniem” został zaadaptowany z koncepcji wzmocnienia w psychologii. Z tego powodu poświęćmy chwilę na zrozumienie psychologicznej koncepcji wzmocnienia. W psychologicznym sensie termin wzmocnienie odnosi się do czegoś, co zwiększa prawdopodobieństwo wystąpienia określonej reakcji/działania. Ta koncepcja wzmocnienia jest centralną ideą teorii warunkowania sprawczego, zaproponowanej początkowo przez psychologa B.F. Skinnera. W tym kontekście wzmocnieniem jest wszystko, co powoduje wzrost częstotliwości danego zachowania. Jeśli pomyślimy o możliwych wzmocnieniach dla ludzi, mogą to być rzeczy takie jak pochwała, podwyżka w pracy, słodycze i zabawne aktywności. W tradycyjnym, psychologicznym sensie istnieją dwa rodzaje wzmocnienia. Istnieje wzmocnienie pozytywne i wzmocnienie negatywne. Wzmocnienie pozytywne to dodanie czegoś, aby zwiększyć zachowanie, jak danie psu smakołyka, gdy jest grzeczny. Wzmocnienie negatywne polega na usunięciu bodźca, aby wywołać zachowanie, jak wyłączenie głośnych dźwięków, aby nakłonić do wyjścia płochliwego kota.
Wzmocnienie pozytywne i negatywne
Wzmocnienie pozytywne zwiększa częstotliwość zachowania, podczas gdy wzmocnienie negatywne ją zmniejsza. Ogólnie rzecz biorąc, wzmocnienie pozytywne jest najczęściej używanym typem wzmocnienia w uczeniu ze wzmocnieniem, ponieważ pomaga modelom maksymalizować wydajność w danym zadaniu. Nie tylko to, ale wzmocnienie pozytywne prowadzi model do wprowadzania bardziej trwałych zmian, zmian, które mogą stać się spójnymi wzorcami i utrzymywać się przez długi czas. W przeciwieństwie do tego, chociaż wzmocnienie negatywne również sprawia, że zachowanie jest bardziej prawdopodobne, jest ono używane do utrzymania minimalnego standardu wydajności, a nie do osiągnięcia maksymalnej wydajności modelu. Wzmocnienie negatywne w uczeniu ze wzmocnieniem może pomóc zapewnić, że model jest trzymany z dala od niepożądanych działań, ale nie może tak naprawdę sprawić, że model będzie eksplorować pożądane działania.
Trenowanie agenta uczącego się ze wzmocnieniem
Kiedy agent uczący się ze wzmocnieniem jest trenowany, używa się czterech różnych składników lub stanów w treningu: stanów początkowych (Stan 0), nowego stanu (Stan 1), akcji i nagród. Wyobraź sobie, że trenujemy agenta uczącego się ze wzmocnieniem do gry w platformówkę, gdzie celem AI jest dotarcie do końca poziomu poprzez poruszanie się w prawo po ekranie. Stan początkowy gry jest pobierany ze środowiska, co oznacza, że analizowana jest pierwsza klatka gry i przekazywana modelowi. Na podstawie tych informacji model musi podjąć decyzję o działaniu. Podczas początkowych faz treningu te działania są losowe, ale w miarę jak model jest wzmacniany, pewne działania staną się bardziej powszechne. Po podjęciu działania środowisko gry jest aktualizowane i tworzony jest nowy stan lub klatka. Jeśli działanie podjęte przez agenta przyniosło pożądany rezultat, powiedzmy w tym przypadku, że agent nadal żyje i nie został trafiony przez wroga, agent otrzymuje pewną nagrodę i staje się bardziej prawdopodobne, że zrobi to samo w przyszłości. Ten podstawowy system jest stale zapętlany, dzieje się raz za razem, i za każdym razem agent stara się nauczyć czegoś więcej i zmaksymalizować swoją nagrodę.
Zadania epizodyczne a ciągłe
Zadania uczenia ze wzmocnieniem można zazwyczaj zaliczyć do jednej z dwóch różnych kategorii: zadań epizodycznych i zadań ciągłych. Zadania epizodyczne będą wykonywać pętlę uczenia/treningu i poprawiać swoją wydajność, aż do spełnienia pewnych kryteriów końcowych i zakończenia treningu. W grze może to być dotarcie do końca poziomu lub wpadnięcie w pułapkę, taką jak kolce. W przeciwieństwie do tego, zadania ciągłe nie mają kryteriów zakończenia, zasadniczo kontynuując trening w nieskończoność, aż inżynier zdecyduje się zakończyć trening.
Monte Carlo a różnica czasowa
Istnieją dwa podstawowe sposoby uczenia lub trenowania agenta uczącego się ze wzmocnieniem. W podejściu Monte Carlo nagrody są dostarczane agentowi (jego wynik jest aktualizowany) tylko na końcu epizodu treningowego. Innymi słowy, tylko wtedy, gdy zostanie spełniony warunek zakończenia, model dowiaduje się, jak dobrze sobie poradził. Może następnie użyć tych informacji do aktualizacji i gdy rozpocznie się kolejna runda treningowa, będzie reagował zgodnie z nowymi informacjami. Metoda różnicy czasowej różni się od metody Monte Carlo tym, że szacowanie wartości, czyli szacowanie wyniku, jest aktualizowane w trakcie epizodu treningowego. Gdy model przejdzie do następnego kroku czasowego, wartości są aktualizowane.
Eksploracja a eksploatacja
Trenowanie agenta uczącego się ze wzmocnieniem jest aktem równoważenia, obejmującym balansowanie między dwoma różnymi metrykami: eksploracją i eksploatacją. Eksploracja to akt zbierania większej ilości informacji o otaczającym środowisku, podczas gdy eksploatacja to wykorzystanie informacji już znanych o środowisku do zdobywania punktów nagrody. Jeśli agent tylko eksploruje i nigdy nie eksploatuje środowiska, pożądane działania nigdy nie zostaną wykonane. Z drugiej strony, jeśli agent tylko eksploatuje i nigdy nie eksploruje, agent nauczy się wykonywać tylko jedną akcję i nie odkryje innych możliwych strategii zdobywania nagród. Dlatego równoważenie eksploracji i eksploatacji jest kluczowe przy tworzeniu agenta uczącego się ze wzmocnieniem.
Zastosowania uczenia ze wzmocnieniem
Uczenie ze wzmocnieniem może być stosowane w szerokiej gamie ról i najlepiej nadaje się do zastosowań, w których zadania wymagają automatyzacji. Automatyzacja zadań do wykonania przez roboty przemysłowe to jeden z obszarów, w których uczenie ze wzmocnieniem okazuje się przydatne. Uczenie ze wzmocnieniem może być również używane do problemów takich jak eksploracja tekstu, tworząc modele zdolne do podsumowywania długich tekstów. Badacze eksperymentują również z wykorzystaniem uczenia ze wzmocnieniem w dziedzinie opieki zdrowotnej, gdzie agenci uczący się ze wzmocnieniem zajmują się zadaniami takimi jak optymalizacja polityki leczenia. Uczenie ze wzmocnieniem mogłoby być również wykorzystane do personalizacji materiałów edukacyjnych dla studentów.
Podsumowanie uczenia ze wzmocnieniem
Uczenie ze wzmocnieniem to potężna metoda konstruowania agentów AI, która może prowadzić do imponujących i czasem zaskakujących rezultatów. Trenowanie agenta poprzez uczenie ze wzmocnieniem może być złożone i trudne, ponieważ wymaga wielu iteracji treningowych i delikatnej równowagi dychotomii eksploracja/eksploatacja. Jednakże, jeśli się powiedzie, agent stworzony za pomocą uczenia ze wzmocnieniem może wykonywać złożone zadania w szerokiej gamie różnych środowisk.








