AI 101
Co to jest regresja liniowa?
Co to jest regresja liniowa?
Regresja liniowa to algorytm wykorzystywany do przewidywania lub wizualizacji relacji między dwiema różnymi cechami/zmiennymi. W zadaniach regresji liniowej istnieją dwa rodzaje zmiennych: zmienną niezależną i zmienną zależną. Zmienna niezależna to zmienna, która stoi sama, niezależnie od innej zmiennej. Podczas zmiany zmiennej niezależnej poziomy zmiennej zależnej będą się zmieniać. Zmienna zależna to zmienna, która jest badana, i jest to to, co model regresji próbuje przewidzieć. W zadaniach regresji liniowej każde obserwowanie/instancja składa się z wartości zmiennej zależnej i zmiennej niezależnej.
To było krótkie wyjaśnienie regresji liniowej, ale sprawmy, abyśmy lepiej zrozumieli regresję liniową, przyglądając się przykładowi i badając wzór, który jest używany.
Zrozumienie regresji liniowej
Załóżmy, że mamy zestaw danych dotyczących rozmiarów dysków twardych i ich kosztu.
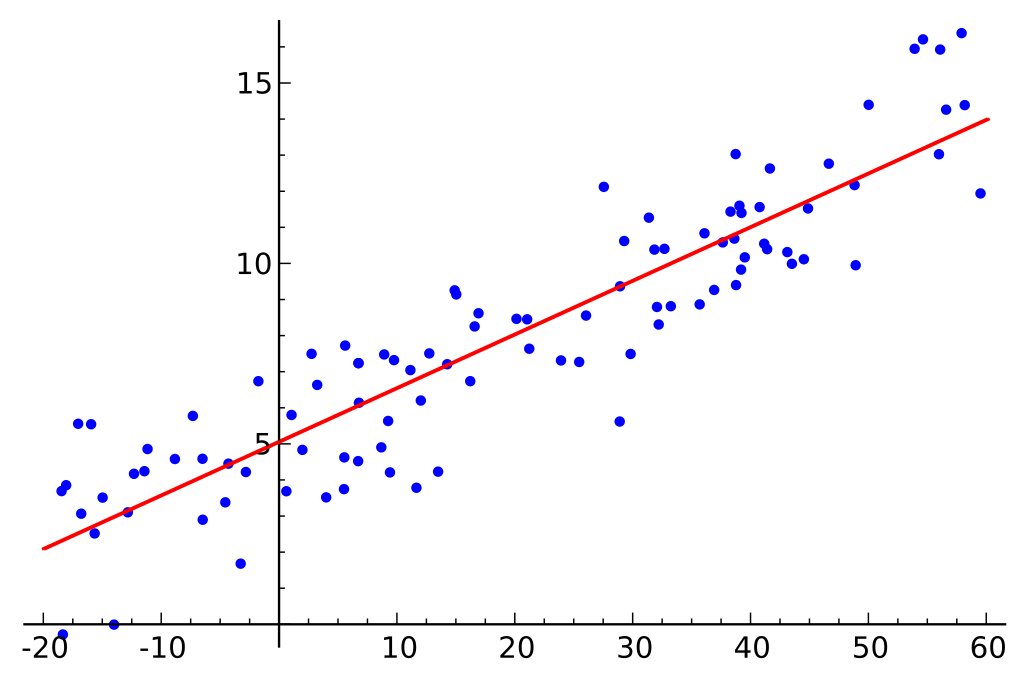
Wyobraźmy sobie, że nasz zestaw danych składa się z dwóch różnych cech: ilości pamięci i kosztu. Im więcej pamięci kupujemy dla komputera, tym więcej kosztuje zakup. Jeśli wykreślimy poszczególne punkty danych na wykresie rozproszenia, możemy uzyskać wykres, który wygląda mniej więcej tak:

Dokładne proporcje pamięci do kosztu mogą się różnić w zależności od producenta i modelu dysku twardego, ale ogólnie trend danych jest taki, że zaczyna się w lewym dolnym rogu (gdzie dyski twarde są tańsze i mają mniejszą pojemność) i przechodzi do prawego górnego rogu (gdzie dyski twarde są droższe i mają większą pojemność).
Jeśli mielibyśmy ilość pamięci na osi X i koszt na osi Y, linia opisująca relację między zmiennymi X i Y zaczynałaby się w lewym dolnym rogu i biegłaby do prawego górnego rogu.

Funkcja modelu regresji polega na znalezieniu liniowej funkcji między zmiennymi X i Y, która najlepiej opisuje relację między tymi zmiennymi. W regresji liniowej zakłada się, że Y można obliczyć z kombinacji zmiennych wejściowych. Relację między zmiennymi wejściowymi (X) i zmiennymi docelowymi (Y) można przedstawić, rysując linię przez punkty na wykresie. Linia reprezentuje funkcję, która najlepiej opisuje relację między X i Y (np. dla każdego wzrostu X o 3, Y wzrasta o 2). Celem jest znalezienie optymalnej “linii regresji” lub linii, która najlepiej pasuje do danych.
Linie są zwykle reprezentowane przez równanie: Y = m*X + b. X odnosi się do zmiennej zależnej, podczas gdy Y jest zmienną niezależną. Natomiast m jest nachyleniem linii, określonym przez “wzrost” do “biegu”. Praktycy machine learning reprezentują słynne równanie nachylenia linii nieco inaczej, używając tego równania:
y(x) = w0 + w1 * x
W powyższym równaniu y jest zmienną docelową, a “w” są parametrami modelu, a wejściem jest “x”. Równanie jest czytane jako: “Funkcja, która daje Y, w zależności od X, jest równa parametry modelu pomnożone przez cechy”. Parametry modelu są dostosowywane podczas szkolenia, aby uzyskać najlepszą linię regresji.
Wielokrotna regresja liniowa

Zdjęcie: Cbaf via Wikimedia Commons, domena publiczna (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Proces opisany powyżej dotyczy prostej regresji liniowej, czyli regresji na zestawach danych, w których jest tylko jedna cecha/zmienna niezależna. Jednak regresję można również wykonać z wieloma cechami. W przypadku “wielokrotnej regresji liniowej” równanie jest rozszerzane o liczbę zmiennych w zestawie danych. Innymi słowy, podczas gdy równanie dla zwykłej regresji liniowej jest y(x) = w0 + w1 * x, równanie dla wielokrotnej regresji liniowej byłoby y(x) = w0 + w1x1 plus wagi i dane wejściowe dla różnych cech. Jeśli oznaczymy łączną liczbę wag i cech jako w(n)x(n), możemy przedstawić wzór w ten sposób:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Po ustaleniu wzoru dla regresji liniowej, model machine learning będzie używał różnych wartości wag, rysując różne linie dopasowania. Pamiętaj, że celem jest znalezienie linii, która najlepiej pasuje do danych, aby określić, która z możliwych kombinacji wag (a więc która z możliwych linii) najlepiej pasuje do danych i opisuje relację między zmiennymi.
Funkcja kosztu jest używana do pomiaru, jak blisko założone wartości Y są do rzeczywistych wartości Y, gdy podana jest określona wartość wagi. Funkcja kosztu dla regresji liniowej jest błędem średnim kwadratowym, który po prostu oblicza średni (kwadratowy) błąd między przewidywaną wartością a prawdziwą wartością dla wszystkich punktów danych w zestawie. Funkcja kosztu jest używana do obliczania kosztu, który ujmuje różnicę między przewidywaną wartością docelową a prawdziwą wartością docelową. Jeśli linia dopasowania jest daleko od punktów danych, koszt będzie wyższy, podczas gdy koszt stanie się mniejszy, im bliżej linia zbliży się do uchwycenia prawdziwych relacji między zmiennymi. Wagi modelu są następnie dostosowywane, aż do znalezienia konfiguracji wag, która daje najmniejszą ilość błędu.








