Sztuczna inteligencja
Regresja liniowa w dziedzinie nauki o danych
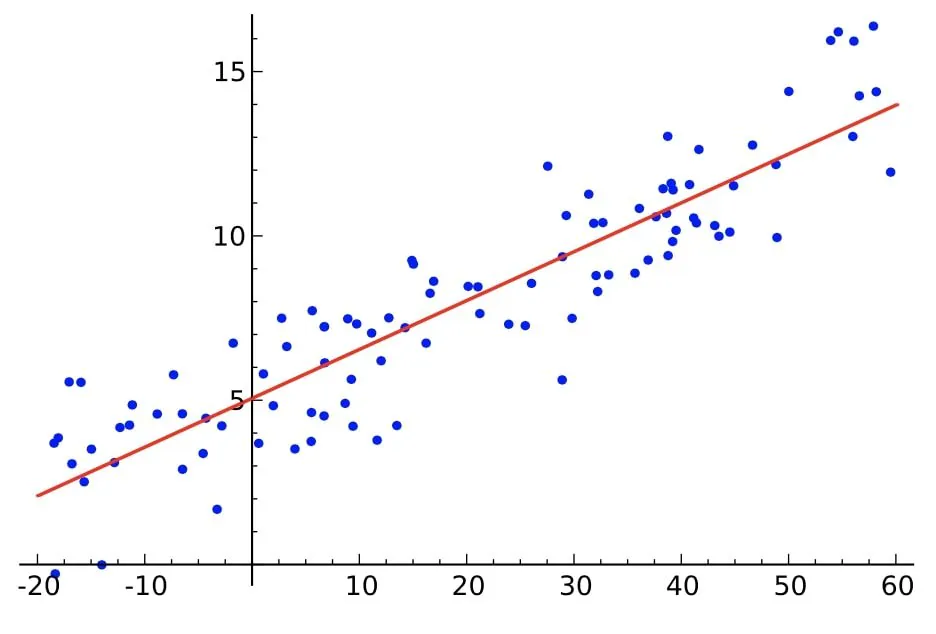
Nauka o danych jest ogromną dziedziną, która rozwija się z każdym dniem. Dziś, największe firmy szukają profesjonalnych naukowców danych, którzy posiadają silną wiedzę o dziedzinie i jej powiązanych pojęciach. Aby dobrze radzić sobie w tej dziedzinie, ważne jest posiadanie gruntownej wiedzy o wszystkich algorytmach nauki o danych. Jednym z najbardziej podstawowych algorytmów nauki o danych jest prosta regresja liniowa. Każdy naukowiec danych powinien wiedzieć, jak używać tego algorytmu do rozwiązywania problemów i uzyskiwania wartościowych wyników.
Prosta regresja liniowa jest metodą określania relacji między zmiennymi wejściowymi i wyjściowymi. Zmienne wejściowe są uważane za zmienne niezależne lub predyktory, a zmienne wyjściowe są zmiennymi zależnymi lub odpowiedziami. W prostej regresji liniowej brana jest pod uwagę tylko jedna zmienna wejściowa.
Rzeczywisty przykład prostej regresji liniowej
Rozważmy zbiór danych składający się z dwóch parametrów: liczby godzin pracy i ilości wykonanej pracy. Prosta regresja liniowa ma na celu odgadnąć ilość wykonanej pracy, jeśli godziny pracy są podane. Rysowana jest linia regresji, która generuje minimalny błąd. Tworzone jest również równanie liniowe, które można następnie wykorzystać do niemal każdego zestawu danych.
Zasady, które obrazują cel prostej regresji liniowej:
Prosta regresja liniowa służy do prognozowania relacji między zmiennymi w zestawie danych i wyciągania wartościowych wniosków. Prosta regresja liniowa jest głównie stosowana do wyznaczania statystycznej relacji między zmiennymi, która nie jest wystarczająco dokładna. Cztery podstawowe zasady obrazują stosowanie prostej regresji liniowej. Poniżej wymieniono te zasady:
- Relacja między dwiema zmiennymi jest liniowa i addytywna: Funkcja liniowa jest ustalona dla każdej pary zmiennych zależnych i niezależnych. Nachylenie tej linii jest różne od wartości zmiennych dostępnych w zestawie danych. Zmienne zależne mają addytywny wpływ na wartości zmiennych niezależnych.
- Błędy są statystycznie niezależne: Ten zasad można rozważyć dla zestawu danych, który zawiera informacje związane z czasem i serią. Błędy kolejne takiego zestawu danych nie korelują i są statystycznie niezależne.
- Błędy mają stałą wariancję (homoscedastyczność): Homoscedastyczność błędów można rozważyć na podstawie różnych parametrów. Parametry te obejmują czas, inne prognozy i inne zmienne.
- Normalność rozkładu błędów: Jest to ważny zasad, ponieważ wspiera trzy powyższe. Jeśli nie można ustalić relacji między zmiennymi w zestawie danych lub jeśli którykolwiek z powyższych zasad nie jest spełniony, to wszystkie prognozy i wnioski wytworzone przez model są błędne. Te wnioski nie mogą być wykorzystane dalej w projekcie, ponieważ nie uzyska się rzeczywistych wyników, jeśli wykorzystuje się błędne i mylące dane.
Zalety prostej regresji liniowej
- Metoda ta jest niezwykle łatwa w użyciu, a wyniki można uzyskać bez wysiłku.
- Metoda ta ma znacznie mniejszą złożoność niż inne algorytmy nauki o danych, zwłaszcza jeśli relacja między zmiennymi zależnymi i niezależnymi jest znana.
- Przeuczenie jest powszechnym stanem, który występuje, gdy ta metoda przyjmuje bezsensowne informacje. Aby rozwiązać ten problem, dostępna jest technika regularyzacji, która redukuje problem przeuczenia, zmniejszając złożoność.
Wady prostej regresji liniowej
- Chociaż problem przeuczenia można wyeliminować, nie można go zignorować. Metoda może przyjmować bezsensowne dane i również eliminować wartościowe informacje. W takim przypadku wszystkie prognozy i wnioski dotyczące danego zestawu danych będą błędne i nie dadzą wartościowych wyników.
- Problem danych odstających jest również bardzo powszechny. Danych odstających uważa się za błędne wartości, które nie odpowiadają dokładnym danym. Gdy takie wartości są brane pod uwagę, cały model wytworzy mylące wyniki, które nie są przydatne.
- W prostej regresji liniowej zakłada się, że zestaw danych ma niezależne dane. To założenie jest błędne, ponieważ może występować zależność między zmiennymi.
Prosta regresja liniowa jest przydatną techniką do określania relacji różnych zmiennych wejściowych i wyjściowych w zestawie danych. Istnieje wiele rzeczywistych zastosowań prostej regresji liniowej. Ten algorytm nie wymaga dużej mocy obliczeniowej i może być łatwo wdrożony. Równania i wnioski wywodzone mogą być dalej rozwijane i są niezwykle proste do zrozumienia. Jednak niektórzy specjaliści uważają, że prosta regresja liniowa nie jest odpowiednią metodą do stosowania w różnych aplikacjach, ponieważ istnieje wiele założeń, które mogą być udowodnione jako błędne. Dlatego konieczne jest stosowanie tej techniki wszędzie, gdzie może być poprawnie zastosowana.












