Cybersicherheit
Warum adversarialen Bildangriffe kein Witz sind
Den Angriff auf Bilderkennungssysteme mit sorgfältig erstellten adversarialen Bildern wurde in den letzten fünf Jahren als amüsant, aber trivialer Beweis des Konzepts betrachtet. Neue Forschung aus Australien legt jedoch nahe, dass die ungezwungene Verwendung hochpopulärer Bild-Datensätze für kommerzielle KI-Projekte ein anhaltendes neues Sicherheitsproblem schaffen könnte.
Für ein paar Jahre jetzt hat eine Gruppe von Akademikern an der University of Adelaide versucht, etwas Wichtiges über die Zukunft von AI-basierten Bilderkennungssystemen zu erklären.
Es ist etwas, das schwierig (und sehr teuer) zu beheben wäre, und das unerhört teuer zu beheben wäre, wenn die aktuellen Trends in der Bilderkennungsforschung in 5-10 Jahren in kommerzielle und industrielle Einsatz umgesetzt werden.
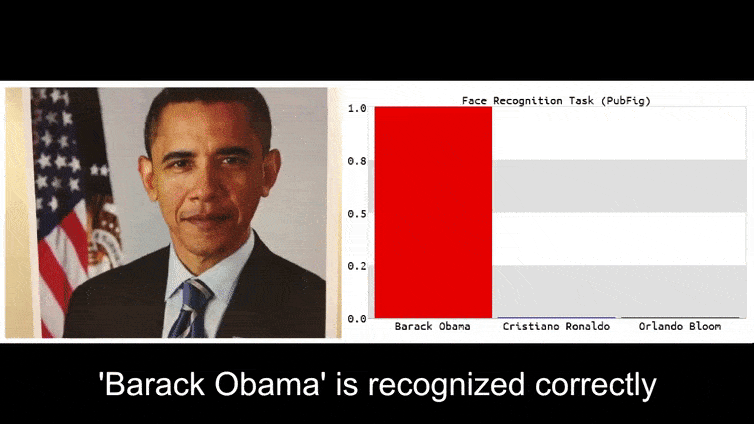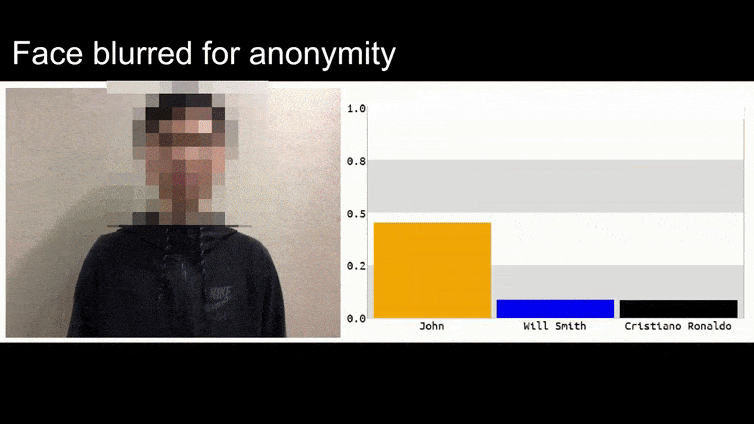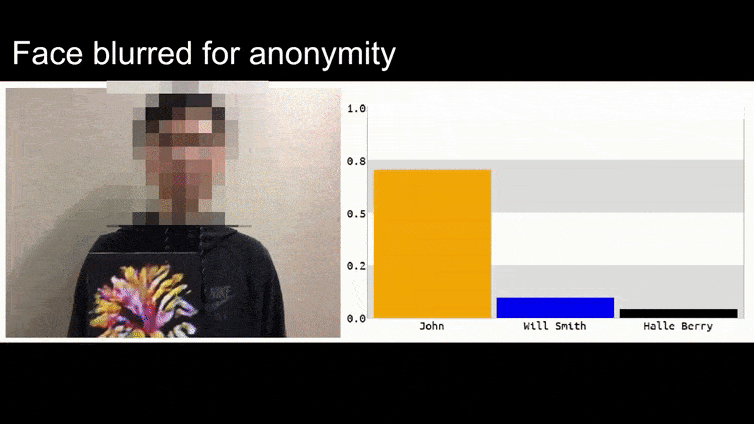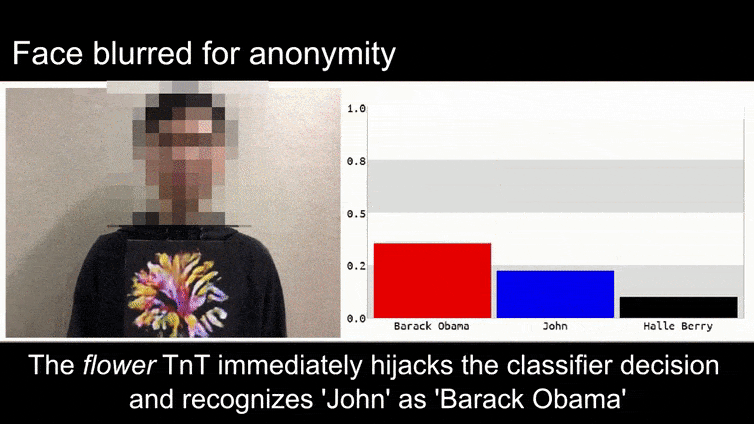
Bevor wir uns damit befassen, werfen wir einen Blick auf eine Blume, die als Präsident Barack Obama klassifiziert wird, aus einem der sechs Videos, die das Team auf der Projektseite veröffentlicht hat:
Quelle: https://www.youtube.com/watch?v=Klepca1Ny3c
In dem obigen Bild wird ein Gesichtserkennungssystem, das offensichtlich weiß, wie man Barack Obama erkennt, hereingelegt und ist zu 80% sicher, dass ein anonymisierter Mann, der ein gefertigtes, gedrucktes adversariales Bild einer Blume hält, auch Barack Obama ist. Das System interessiert sich nicht einmal dafür, dass das “falsche Gesicht” auf der Brust des Subjekts und nicht auf seinen Schultern ist.
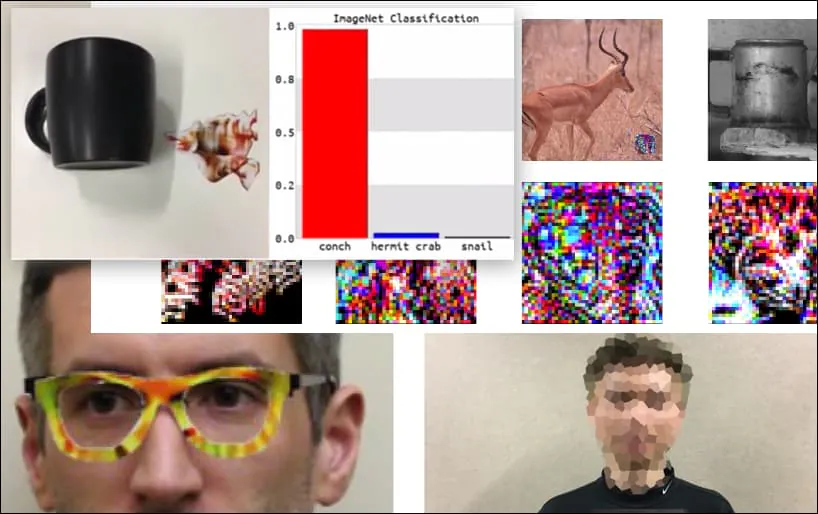
Obwohl es beeindruckend ist, dass die Forscher es geschafft haben, diese Art von Identitätsübernahme zu erreichen, indem sie ein kohärentes Bild (eine Blume) anstelle des üblichen Zufallsrauschens generieren, scheint es, dass solche albernen Ausbeutungen ziemlich regelmäßig in Sicherheitsforschungen auf dem Gebiet des Computer Vision auftauchen. Zum Beispiel die seltsam gemusterten Brillen, die 2016 in der Lage waren, Gesichtserkennung zu täuschen, oder speziell gefertigte adversarialen Bilder, die versuchen, Verkehrsschilder umzuschreiben.
Wenn Sie interessiert sind, ist das Convolutional Neural Network (CNN)-Modell, das in dem obigen Beispiel angegriffen wird, VGGFace (VGG-16), das auf dem PubFig-Datensatz der Columbia University trainiert wurde. Andere Angriffsbeispiele, die von den Forschern entwickelt wurden, verwendeten unterschiedliche Ressourcen in verschiedenen Kombinationen.

Eine Tastatur wird als Muschel umklassifiziert, in einem WideResNet50-Modell auf ImageNet. Die Forscher haben auch sichergestellt, dass das Modell keine Voreingenommenheit gegenüber Muscheln hat. Siehe das vollständige Video für erweiterte und zusätzliche Demonstrationen unter https://www.youtube.com/watch?v=dhTTjjrxIcU
Bilderkennung als aufkommender Angriffsweg
Die vielen beeindruckenden Angriffe, die die Forscher skizzieren und illustrieren, sind keine Kritik an einzelnen Datensätzen oder spezifischen maschinellen Lernarchitekturen, die sie verwenden. Sie können auch nicht leicht durch das Umschalten von Datensätzen oder Modellen, das Retrainieren von Modellen oder andere “einfache” Abhilfen verteidigt werden, die ML-Praktiker veranlassen, über sporadische Demonstrationen dieser Art von Trickserei zu spotten.
Vielmehr veranschaulichen die Ausbeutungen des Adelaide-Teams eine zentrale Schwäche in der gesamten aktuellen Architektur der Bilderkennungsentwicklung; eine Schwäche, die viele zukünftige Bilderkennungssysteme der leichten Manipulation durch Angreifer aussetzen und alle nachfolgenden Abwehrmaßnahmen auf dem Rückfuß stellen könnte.
Stellen Sie sich vor, dass die neuesten adversarialen Angriffsbilder (wie die Blume oben) als “Zero-Day-Exploits” zu den Sicherheitssystemen der Zukunft hinzugefügt werden, genauso wie aktuelle Anti-Malware- und Antiviren-Frameworks ihre Virendefinitionen jeden Tag aktualisieren.
Das Potenzial für neue adversarialen Bildangriffe wäre unerschöpflich, weil die Grundarchitektur des Systems keine nachgelagerten Probleme vorhergesehen hat, wie es bei dem Internet, dem Millennium-Bug und dem schiefen Turm von Pisa der Fall war.
Wie also schaffen wir die Voraussetzungen für dies?
Das Abrufen von Daten für einen Angriff
Adversarialen Bilder wie das “Blumen”-Beispiel oben werden durch den Zugriff auf die Bild-Datensätze erzeugt, die die Computermodelle trainiert haben. Sie benötigen keinen “privilegierten” Zugriff auf Trainingsdaten (oder Modellarchitekturen), da die meisten populären Datensätze (und viele trainierte Modelle) in einem robusten und ständig aktualisierten Torrent-Szenario verfügbar sind.
Zum Beispiel ist der renommierte Riese der Computer-Vision-Datensätze, ImageNet, über Torrent verfügbar, umgeht seine üblichen Einschränkungen und macht wichtige sekundäre Elemente wie Validierungsmengen verfügbar.

Quelle: https://academictorrents.com
Wenn Sie die Daten haben, können Sie (wie die Adelaide-Forscher bemerken) effektiv jeden beliebten Datensatz “reverse-engineeren”, wie zum Beispiel CityScapes oder CIFAR.
Im Falle von PubFig, dem Datensatz, der das “Obama-Blumen”-Beispiel ermöglichte, hat die Columbia University eine wachsende Tendenz bei Urheberrechtsproblemen im Zusammenhang mit der Weiterverteilung von Bild-Datensätzen angegangen, indem sie Forschern Anweisungen gibt, wie sie den Datensatz über kuratierte Links reproduzieren können, anstatt die Kompilation direkt verfügbar zu machen, und bemerkt ‘Dies scheint der Weg zu sein, den andere große webbasierte Datenbanken zu entwickeln scheinen’.
In den meisten Fällen ist das nicht notwendig: Kaggle schätzt, dass die zehn beliebtesten Bild-Datensätze in der Computer-Vision sind: CIFAR-10 und CIFAR-100 (beide direkt herunterladbar); CALTECH-101 und 256 (beide verfügbar und derzeit als Torrents verfügbar); MNIST (offiziell verfügbar, auch auf Torrents); ImageNet (siehe oben); Pascal VOC (verfügbar, auch auf Torrents); MS COCO (verfügbar, und auf Torrents); Sports-1M (verfügbar); und YouTube-8M (verfügbar).
Diese Verfügbarkeit ist auch repräsentativ für den breiteren Bereich verfügbarer Computer-Vision-Bild-Datensätze, da Unsichtbarkeit der Tod in einer “publizieren oder untergehen”-Kultur der Open-Source-Entwicklung ist.
In jedem Fall verschärfen die Knappheit an verwaltbaren neuen Datensätzen, die hohen Kosten für die Entwicklung von Bild-Sätzen, die Abhängigkeit von “alten Favoriten” und die Tendenz, einfach ältere Datensätze anzupassen, alle das Problem, das im neuen Adelaide-Papier skizziert wird.
Typische Kritik an adversarialen Bildangriffsmethoden
Die häufigste und anhaltendste Kritik von maschinellen Lern-Ingenieuren an der Effektivität der neuesten adversarialen Bildangriffstechniken ist, dass der Angriff spezifisch für einen bestimmten Datensatz, ein bestimmtes Modell oder beides ist; dass er nicht “verallgemeinerbar” auf andere Systeme ist; und dass er daher nur eine triviale Bedrohung darstellt.
Die zweithäufigste Beschwerde ist, dass der adversarialen Bildangriff ‘white box’ ist, was bedeutet, dass Sie direkten Zugriff auf die Trainingsumgebung oder Daten benötigen. Dies ist tatsächlich ein unwahrscheinliches Szenario, in den meisten Fällen – zum Beispiel, wenn Sie die Trainingsprozesse für die Gesichtserkennungssysteme der Metropolitan Police von London ausnutzen wollten, müssten Sie sich in NEC einhacken, entweder mit einer Konsole oder einer Axt.
Das langfristige “DNA”-Erbe populärer Computer-Vision-Datensätze
Was die erste Kritik betrifft, sollten wir nicht nur berücksichtigen, dass eine Handvoll Computer-Vision-Datensätze die Branche Jahr für Jahr dominieren (z. B. ImageNet für mehrere Arten von Objekten, CityScapes für Fahrzeugszenen und FFHQ für Gesichtserkennung); sondern auch, dass sie als einfache annotierte Bild-Daten “plattformunabhängig” und hochgradig übertragbar sind.
Je nach Fähigkeit wird jedes Computer-Vision-Trainings-Modell einige Merkmale von Objekten und Klassen im ImageNet-Datensatz finden. Einige Architekturen können mehr Merkmale finden als andere oder nützlichere Verbindungen herstellen als andere, aber alle sollten mindestens die höchstentwickelten Merkmale finden:

ImageNet-Daten mit der Mindestanzahl korrekter Identifizierungen – ‘hochentwickelte’ Merkmale.
Es sind diese “hochentwickelten” Merkmale, die einen Datensatz unterscheiden und “fingerprinten” und die zuverlässigen “Haken” sind, an denen eine langfristige adversarialen Bildangriffsmethode aufgehängt werden kann, die über verschiedene Systeme hinweg wachsen und mit dem “alten” Datensatz Schritt halten kann, während dieser in neuen Forschungen und Produkten fortgeführt wird.
Eine fortschrittlichere Architektur wird genauere und granulare Identifizierungen, Merkmale und Klassen erzeugen:

Jedoch wird die adversarialen Angriffsgenerierung, die mehr auf diese niedrigeren Merkmale angewiesen ist (z. B. “junger weißer Mann” anstelle von “Gesicht”), desto weniger effektiv in Übertragung oder späteren Architekturen, die verschiedene Versionen des ursprünglichen Datensatzes verwenden – wie zum Beispiel eine Teilmenge oder einen gefilterten Satz, in dem viele der ursprünglichen Bilder aus dem vollständigen Datensatz nicht vorhanden sind:

Adversarialen Angriffe auf “zeroed”, vorab trainierte Modelle
Was ist mit Fällen, in denen Sie einfach ein vorab trainiertes Modell herunterladen, das ursprünglich auf einem sehr populären Datensatz trainiert wurde, und es völlig neuen Daten geben?
Das Modell wurde bereits auf ImageNet trainiert, und alles, was übrig bleibt, sind die Gewichte, die möglicherweise Wochen oder Monate zum Trainieren benötigt haben und jetzt bereit sind, Ihnen zu helfen, ähnliche Objekte wie diejenigen zu identifizieren, die im ursprünglichen (jetzt abwesenden) Datensatz vorhanden waren.

Mit den ursprünglichen Daten, die aus der Trainingsarchitektur entfernt wurden, bleibt die ‘Vorprägung’ des Modells, Objekte auf die Weise zu klassifizieren, die es ursprünglich gelernt hat, was im Wesentlichen dazu führen wird, dass viele der ursprünglichen ‘Signaturen’ sich neu bilden und erneut anfällig für die gleichen alten adversarialen Bildangriffsmethoden werden.
Diese Gewichte sind wertvoll. Ohne die Daten oder die Gewichte haben Sie im Wesentlichen eine leere Architektur ohne Daten. Sie müssen es von Grund auf trainieren, bei großem Zeitaufwand und Rechenressourcen, genau wie die ursprünglichen Autoren es taten (wahrscheinlich auf leistungsfähigerer Hardware und mit einem höheren Budget als Ihnen zur Verfügung steht).
Das Problem ist, dass die Gewichte bereits ziemlich gut geformt und widerstandsfähig sind. Obwohl sie sich während des Trainings ein wenig anpassen werden, werden sie auf Ihren neuen Daten ähnlich verhalten wie auf den ursprünglichen Daten, wodurch sie signifikante Merkmale erzeugen, auf die ein adversarialer Angriffssystem zurückgreifen kann.
Langfristig bewahrt dies auch das “DNA”-Erbe von Computer-Vision-Datensätzen, die zwölf oder mehr Jahre alt sind und möglicherweise eine bemerkenswerte Evolution von Open-Source-Bemühungen bis hin zu kommerziellen Einsatz experienced haben – sogar in Fällen, in denen die ursprünglichen Trainingsdaten vollständig am Anfang des Projekts entfernt wurden. Einige dieser kommerziellen Einsatz können noch Jahre nicht erfolgen.
Kein White Box benötigt
Was die zweite häufige Kritik an adversarialen Bildangriffssystemen betrifft, haben die Autoren des neuen Papiers festgestellt, dass ihre Fähigkeit, Erkennungssysteme mit gefertigten Bildern von Blumen zu täuschen, hochgradig übertragbar auf eine Reihe von Architekturen ist.
Während sie bemerken, dass ihre “Universal NaTuralistic adversarial paTches” (TnT)-Methode die erste ist, die erkennbare Bilder (anstatt Zufallsrauschens) verwendet, um Bilderkennungssysteme zu täuschen, erklären die Autoren auch:
‘[TnTs] sind effektiv gegen mehrere State-of-the-Art-Klassifizierer, von denen, die in der Large-Scale Visual Recognition-Aufgabe des ImageNet-Datensatzes bis hin zu VGG-Face-Modellen in der Gesichtserkennungsaufgabe des PubFig-Datensatzes in sowohl zielgerichteten als auch unzielgerichteten Angriffen.
‘TnTs können die Natürlichkeit aufweisen, die mit den Auslösern in Trojan-Angriffsmethoden erreichbar ist; und ii) die Verallgemeinerung und Übertragbarkeit von adversarialen Beispielen auf andere Netzwerke.
‘Dies wirft Sicherheits- und Sicherheitsbedenken hinsichtlich bereits eingesetzter DNNs sowie zukünftiger DNN-Einsätze auf, in denen Angreifer unscheinbare, natürliche Objekt-Patches verwenden können, um neuronale Netzwerksysteme zu täuschen, ohne das Modell zu manipulieren und die Entdeckung zu riskieren.’
Die Autoren schlagen vor, dass herkömmliche Gegenmaßnahmen, wie die Verschlechterung der sauberen Genauigkeit eines Netzwerks, möglicherweise einige Verteidigung gegen TnT-Patches bieten könnten, aber dass ‘TnTs immer noch erfolgreich diese SOTA-bewiesenen Abwehrmethoden umgehen können, mit den meisten verteidigenden Systemen, die 0% Robustheit erreichen’.
Mögliche andere Lösungen umfassen federatives Lernen, bei dem die Herkunft der beitragenden Bilder geschützt wird, und neue Ansätze, die Daten direkt während des Trainings “verschlüsseln” könnten, wie einer kürzlich vorgeschlagenen von der Nanjing University of Aeronautics and Astronautics.
Auch in diesen Fällen wäre es wichtig, auf wirklich neuen Bild-Daten zu trainieren – inzwischen sind die Bilder und die damit verbundenen Annotationen in den kleinen, prominenten CV-Datensätzen so tief in Entwicklungszyklen auf der ganzen Welt verankert, dass sie eher Software als Daten zu sein scheinen; Software, die oft in den letzten Jahren nicht wesentlich aktualisiert wurde.
Zusammenfassung
Adversarialen Bildangriffe werden ermöglicht, nicht nur durch Open-Source-Machine-Learning-Praktiken, sondern auch durch eine Unternehmens-KI-Entwicklungs-Kultur, die motiviert ist, etablierte Computer-Vision-Datensätze aus mehreren Gründen wiederverwendet: Sie haben bereits ihre Wirksamkeit bewiesen; sie sind viel billiger als “von vorne zu beginnen”; und sie werden von Vorreitern und Organisationen in Wissenschaft und Wirtschaft auf hohem Niveau mit Finanzierung und Personal betrieben, was für ein einzelnes Unternehmen schwer zu replizieren wäre.
Zusätzlich liegen die Daten in vielen Fällen, in denen die Daten nicht ursprünglich sind (z. B. anders als CityScapes), vor den jüngsten Kontroversen um Datenschutz und Datenerfassungspraktiken, was diese älteren Datensätze in einer Art rechtlicher Niemandsland belässt, das aus Sicht eines Unternehmens wie ein “sicherer Hafen” aussehen mag.
TnT-Angriffe! Universelle natürliche adversarialen Patches gegen Deep Neural Network-Systeme ist koautoriert von Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe von der University of Adelaide, zusammen mit Shiqing Ma von der Abteilung für Informatik an der Rutgers University.
Aktualisiert am 1. Dezember 2021, 7:06 Uhr GMT+2 – korrigierte Tippfehler.












