
AI 101
Was ist lineare Regression?
Was ist lineare Regression?
Die lineare Regression ist ein Algorithmus zur Vorhersage oder Visualisierung von a Beziehung zwischen zwei verschiedenen Merkmalen/Variablen. Bei linearen Regressionsaufgaben werden zwei Arten von Variablen untersucht: die abhängige Variable und die unabhängige Variable. Die unabhängige Variable ist die Variable, die für sich allein steht und nicht von der anderen Variablen beeinflusst wird. Wenn die unabhängige Variable angepasst wird, schwanken die Werte der abhängigen Variablen. Die abhängige Variable ist die Variable, die untersucht wird, und sie ist das, was das Regressionsmodell auflöst bzw. vorherzusagen versucht. Bei linearen Regressionsaufgaben besteht jede Beobachtung/Instanz sowohl aus dem abhängigen Variablenwert als auch dem unabhängigen Variablenwert.
Das war eine kurze Erklärung der linearen Regression, aber stellen wir sicher, dass wir zu einem besseren Verständnis der linearen Regression gelangen, indem wir uns ein Beispiel dafür ansehen und die dabei verwendete Formel untersuchen.
Lineare Regression verstehen
Angenommen, wir verfügen über einen Datensatz, der die Festplattengrößen und die Kosten dieser Festplatten abdeckt.
Nehmen wir an, dass der Datensatz, den wir haben, aus zwei verschiedenen Merkmalen besteht: der Speichermenge und den Kosten. Je mehr Speicher wir für einen Computer kaufen, desto höher sind die Anschaffungskosten. Wenn wir die einzelnen Datenpunkte in einem Streudiagramm darstellen, erhalten wir möglicherweise ein Diagramm, das etwa so aussieht:

Das genaue Speicher-Kosten-Verhältnis kann je nach Hersteller und Festplattenmodell variieren, aber im Allgemeinen beginnt der Trend der Daten unten links (wo Festplatten sowohl billiger sind als auch eine geringere Kapazität haben) und geht weiter oben rechts (wo die Laufwerke teurer sind und eine höhere Kapazität haben).
Wenn wir die Speichermenge auf der X-Achse und die Kosten auf der Y-Achse hätten, würde eine Linie, die die Beziehung zwischen den X- und Y-Variablen erfasst, in der unteren linken Ecke beginnen und nach rechts oben verlaufen.
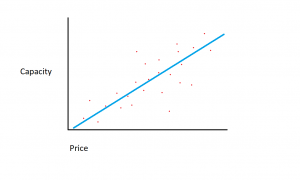
Die Funktion eines Regressionsmodells besteht darin, eine lineare Funktion zwischen den X- und Y-Variablen zu bestimmen, die die Beziehung zwischen den beiden Variablen am besten beschreibt. Bei der linearen Regression wird davon ausgegangen, dass Y aus einer Kombination der Eingabevariablen berechnet werden kann. Der Zusammenhang zwischen den Eingangsgrößen (X) und den Zielgrößen (Y) lässt sich darstellen, indem man im Diagramm eine Linie durch die Punkte zieht. Die Linie stellt die Funktion dar, die die Beziehung zwischen X und Y am besten beschreibt (z. B. jedes Mal, wenn X um 3 zunimmt, erhöht sich Y um 2). Das Ziel besteht darin, eine optimale „Regressionslinie“ oder die Linie/Funktion zu finden, die am besten zu den Daten passt.
Linien werden typischerweise durch die Gleichung dargestellt: Y = m*X + b. X bezieht sich auf die abhängige Variable, während Y die unabhängige Variable ist. Dabei ist m die Steigung der Linie, definiert durch den „Anstieg“ über dem „Lauf“. Praktiker des maschinellen Lernens stellen die berühmte Steigungsliniengleichung etwas anders dar und verwenden stattdessen diese Gleichung:
y(x) = w0 + w1 * x
In der obigen Gleichung ist y die Zielvariable, während „w“ die Parameter des Modells ist und die Eingabe „x“ ist. Die Gleichung lautet also: „Die Funktion, die Y abhängig von X ergibt, ist gleich den Parametern des Modells multipliziert mit den Merkmalen.“ Die Parameter des Modells werden während des Trainings angepasst, um die am besten geeignete Regressionslinie zu erhalten.
Multiple lineare Regression

Foto: Cbaf über Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Der oben beschriebene Prozess gilt für die einfache lineare Regression oder die Regression von Datensätzen, bei denen es nur ein einziges Merkmal/eine unabhängige Variable gibt. Eine Regression kann jedoch auch mit mehreren Merkmalen durchgeführt werden. Im Fall von "multiple lineare Regression“ wird die Gleichung um die Anzahl der im Datensatz gefundenen Variablen erweitert. Mit anderen Worten: Während die Gleichung für die reguläre lineare Regression y(x) = w0 + w1 * x lautet, lautet die Gleichung für die multiple lineare Regression y(x) = w0 + w1x1 plus die Gewichtungen und Eingaben für die verschiedenen Merkmale. Wenn wir die Gesamtzahl der Gewichte und Merkmale als w(n)x(n) darstellen, könnten wir die Formel wie folgt darstellen:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Nachdem die Formel für die lineare Regression erstellt wurde, verwendet das maschinelle Lernmodell unterschiedliche Werte für die Gewichte und zeichnet unterschiedliche Anpassungslinien. Denken Sie daran, dass das Ziel darin besteht, die Linie zu finden, die am besten zu den Daten passt, um zu bestimmen, welche der möglichen Gewichtskombinationen (und damit welche mögliche Linie) am besten zu den Daten passt und die Beziehung zwischen den Variablen erklärt.
Eine Kostenfunktion wird verwendet, um zu messen, wie nahe die angenommenen Y-Werte an den tatsächlichen Y-Werten liegen, wenn ein bestimmter Gewichtungswert gegeben ist. Die Kostenfunktion Bei der linearen Regression handelt es sich um den mittleren quadratischen Fehler, der einfach den durchschnittlichen (quadratischen) Fehler zwischen dem vorhergesagten Wert und dem wahren Wert für alle verschiedenen Datenpunkte im Datensatz annimmt. Mit der Kostenfunktion werden Kosten berechnet, die die Differenz zwischen dem vorhergesagten Zielwert und dem wahren Zielwert erfassen. Wenn die Anpassungslinie weit von den Datenpunkten entfernt ist, sind die Kosten höher, während die Kosten umso geringer werden, je näher die Linie der Erfassung der wahren Beziehungen zwischen Variablen kommt. Anschließend werden die Gewichte des Modells angepasst, bis die Gewichtskonfiguration gefunden wird, die den geringsten Fehler erzeugt.










