Künstliche Intelligenz
Drei Herausforderungen vor Stable Diffusion

Die Veröffentlichung von stability.ai’s Stable Diffusion latent diffusion Bildsynthesemodell vor ein paar Wochen mag eine der bedeutendsten technologischen Enthüllungen seit DeCSS im Jahr 1999 sein; es ist sicherlich das größte Ereignis in der KI-generierten Bildgebung seit dem Deepfakes-Code im Jahr 2017 auf GitHub kopiert und in DeepFaceLab und FaceSwap forked wurde, sowie in die Echtzeit-Streaming-Deepfake-Software DeepFaceLive.
Mit einem Schlag wurden die Benutzerfrustrationen über die Inhaltsbeschränkungen in DALL-E 2’s Bildsynthese-API beiseitegefegt, als sich herausstellte, dass Stable Diffusions NSFW-Filter durch Ändern einer einzigen Codezeile deaktiviert werden konnte. Pornozentrierte Stable-Diffusion-Reddits schossen fast sofort aus dem Boden, und wurden ebenso schnell gekappt, während die Entwickler- und Benutzerlager sich auf Discord in offizielle und NSFW-Communities teilten, und Twitter begann, sich mit fantastischen Stable-Diffusion-Kreationen zu füllen.
Im Moment scheint jeder Tag einige erstaunliche Innovationen von den Entwicklern zu bringen, die das System angenommen haben, mit Plugins und Drittanbieter-Erweiterungen, die hastig für Krita, Photoshop, Cinema4D, Blender und viele andere Anwendungsplattformen geschrieben werden.
In der Zwischenzeit wird Promptcraft – die jetzt professionelle Kunst des ‘KI-Flüsterns’, die möglicherweise die kürzeste Karrieremöglichkeit seit ‘Filofax-Binder’ wird – bereits kommerzialisiert, während die frühe Monetarisierung von Stable Diffusion auf Patreon-Ebene stattfindet, mit der Gewissheit, dass noch anspruchsvollere Angebote kommen werden, für diejenigen, die nicht bereit sind, Conda-basierte Installs des Quellcodes zu navigieren oder die vorschriftlichen NSFW-Filter von webbasierten Implementierungen.
Das Tempo der Entwicklung und das freie Gefühl der Erkundung von Benutzern geht mit einer atemberaubenden Geschwindigkeit voran, dass es schwierig ist, sehr weit vorauszusehen. Im Wesentlichen wissen wir nicht genau, womit wir es zu tun haben, oder was alle Einschränkungen oder Möglichkeiten sein könnten.
Trotzdem lassen Sie uns einen Blick auf drei der interessantesten und herausforderndsten Hürden werfen, die die schnell gebildete und schnell wachsende Stable-Diffusion-Community zu überwinden hat.
1: Optimierung von Tile-basierten Pipelines
Vor dem Hintergrund begrenzter Hardware-Ressourcen und harter Grenzen bei der Auflösung von Trainingsbildern, scheint es wahrscheinlich, dass Entwickler Workarounds finden werden, um sowohl die Qualität als auch die Auflösung von Stable-Diffusion-Ausgaben zu verbessern. Viele dieser Projekte werden darauf abzielen, die Einschränkungen des Systems auszunutzen, wie seine native Auflösung von nur 512×512 Pixeln.
Wie immer der Fall bei Computer-Vision- und Bildsynthese-Initiativen ist, wurde Stable Diffusion auf quadratischen Bildern trainiert, in diesem Fall auf 512×512 Pixel umgestellt, damit die Quellbilder regularisiert und in die Einschränkungen der GPUs, die das Modell trainierten, passten.
Daher “denkt” Stable Diffusion (wenn es überhaupt denkt) in 512×512-Begriffen und sicherlich in quadratischen Begriffen. Viele Benutzer, die derzeit die Grenzen des Systems erkunden, berichten, dass Stable Diffusion die zuverlässigsten und am wenigsten fehlerhaften Ergebnisse bei dieser ziemlich eingeschränkten Seitenverhältnis (siehe “Extremitäten ansprechen” unten) liefert.
Obwohl verschiedene Implementierungen eine Aufskalierung via RealESRGAN (und können schlecht gerenderte Gesichter via GFPGAN beheben) bieten, entwickeln einige Benutzer derzeit Methoden, um Bilder in 512x512px-Sektionen aufzuteilen und die Bilder zusammenzufügen, um größere Zusammensetzungen zu erstellen.

Dieses 1024×576-Render, eine Auflösung, die normalerweise in einem einzigen Stable-Diffusion-Render unmöglich ist, wurde erstellt, indem die attention.py-Python-Datei aus dem DoggettX-Fork von Stable Diffusion (eine Version, die tile-basiertes Upscaling implementiert) in einen anderen Fork kopiert wurde. Quelle: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Obwohl einige Initiativen dieser Art originalen Code oder andere Bibliotheken verwenden, wird der txt2imghd-Port von GOBIG (ein Modus in der VRAM-hungrigen ProgRockDiffusion) bald diese Funktionalität zum Hauptzweig hinzufügen. Während txt2imghd ein dedizierter Port von GOBIG ist, umfassen andere Bemühungen von Community-Entwicklern unterschiedliche Implementierungen von GOBIG.

Ein bequem abstraktes Bild im ursprünglichen 512x512px-Render (links und zweites von links); aufgeskaliert von ESGRAN, das jetzt mehr oder weniger native ist, über alle Stable-Diffusion-Verteilungen; und mit ‘spezieller Aufmerksamkeit’ via einer Implementierung von GOBIG, die Details produziert, die, zumindest innerhalb der Grenzen des Bildabschnitts, besser aufgeskaliert erscheinen. Quelle: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Die Art von abstraktem Beispiel, das oben gezeigt wird, hat viele ‘kleine Königreiche’ von Details, die diese selbstbezogene Herangehensweise an das Upscaling unterstützen, aber die möglicherweise anspruchsvollere codegetriebene Lösungen erfordern, um nicht-repetitive, kohärente Aufskalierung zu produzieren, die nicht aussehen, als ob sie aus vielen Teilen zusammengesetzt worden wäre. Nicht zuletzt im Fall von Gesichtern, wo wir ungewöhnlich empfindlich auf Aberrationen oder ‘störende’ Artefakte reagieren. Daher werden Gesichter möglicherweise letztendlich eine dedizierte Lösung benötigen.
Stable Diffusion hat derzeit keinen Mechanismus, um die Aufmerksamkeit auf das Gesicht während eines Renderns in der gleichen Weise zu konzentrieren, wie Menschen Gesichtsinformationen priorisieren. Obwohl einige Entwickler in den Discord-Communities Methoden zur Implementierung dieser Art von ‘verbesserter Aufmerksamkeit’ in Betracht ziehen, ist es derzeit viel einfacher, das Gesicht manuell (und letztendlich automatisch) nach dem initialen Render zu verbessern.
Ein menschliches Gesicht hat eine interne und vollständige semantische Logik, die nicht in einem ‘Tile’ der unteren Ecke eines (z. B.) Gebäudes gefunden wird, und daher ist es derzeit möglich, sehr effektiv ‘hineinzuzoomen’ und ein ‘skizzenhaftes’ Gesicht in Stable-Diffusion-Ausgaben neu zu rendern.

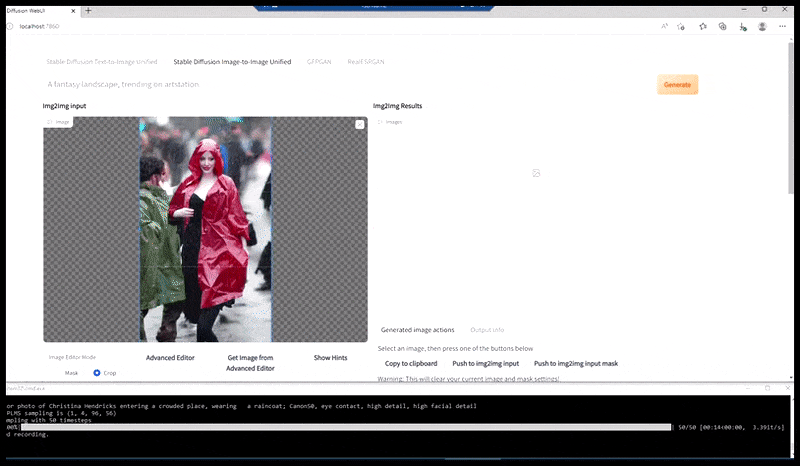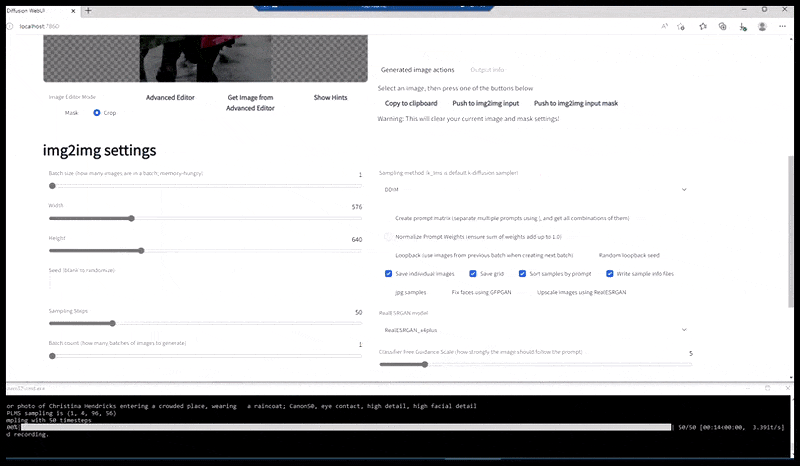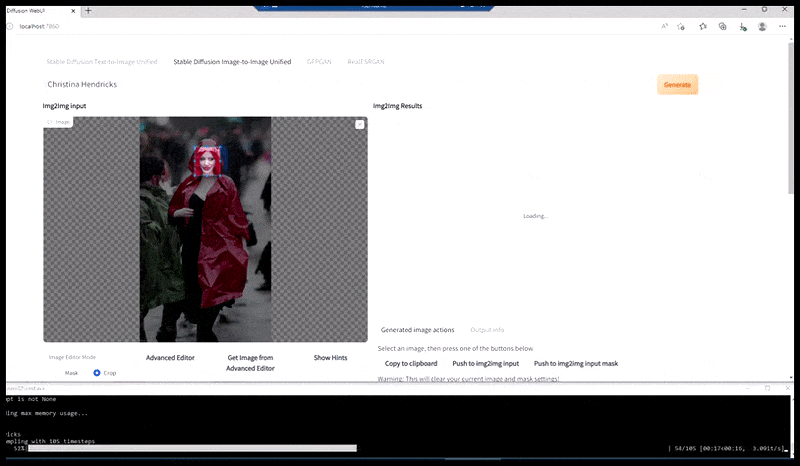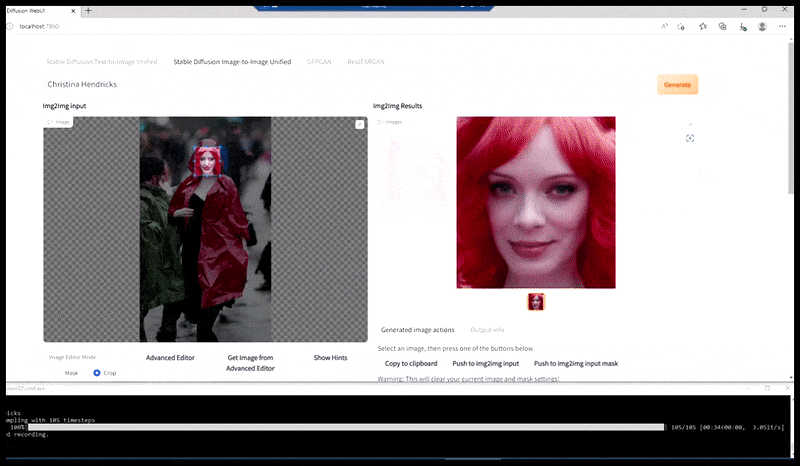
Links, Stable Diffusions erste Bemühung mit dem Prompt ‘Vollständiges Farbfoto von Christina Hendricks, die einen überfüllten Ort betritt, einen Regenmantel tragend; Canon50, Augenkontakt, hohe Details, hohe Gesichtsdetails’. Rechts, ein verbessertes Gesicht, das durch Einlegen des verschwommenen und skizzenhaften Gesichts aus dem ersten Render in die volle Aufmerksamkeit von Stable Diffusion mithilfe von Img2Img (siehe animierte Bilder unten) erhalten wurde.
In Abwesenheit einer dedizierten Textual-Inversion-Lösung (siehe unten) wird dies nur funktionieren, wenn die Daten verfügbar sind, d. h. für Prominentenbilder, bei denen die Person bereits gut in den LAION-Datensubsets vertreten ist, die Stable Diffusion trainiert haben. Daher wird es funktionieren, wenn es um die likes von Tom Cruise, Brad Pitt, Jennifer Lawrence und einen begrenzten Bereich echter Medienberühmtheiten geht, die in großer Zahl in den Quelldaten vorhanden sind.
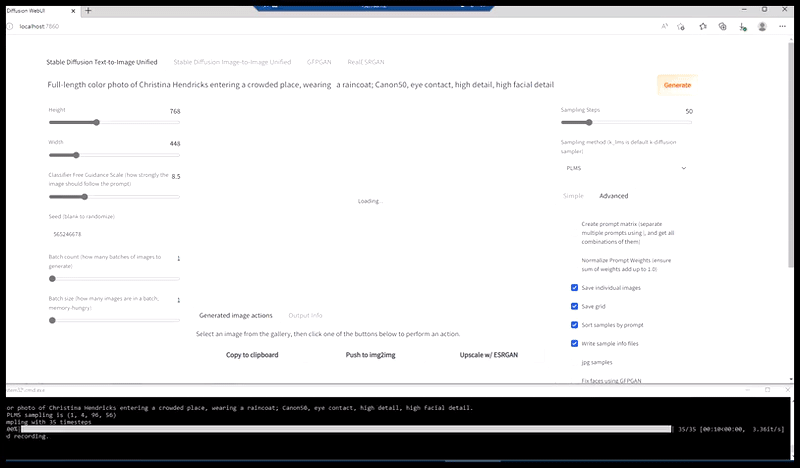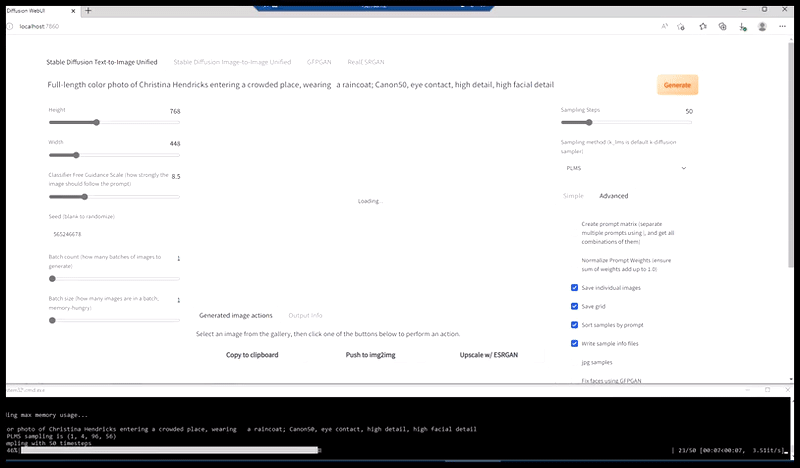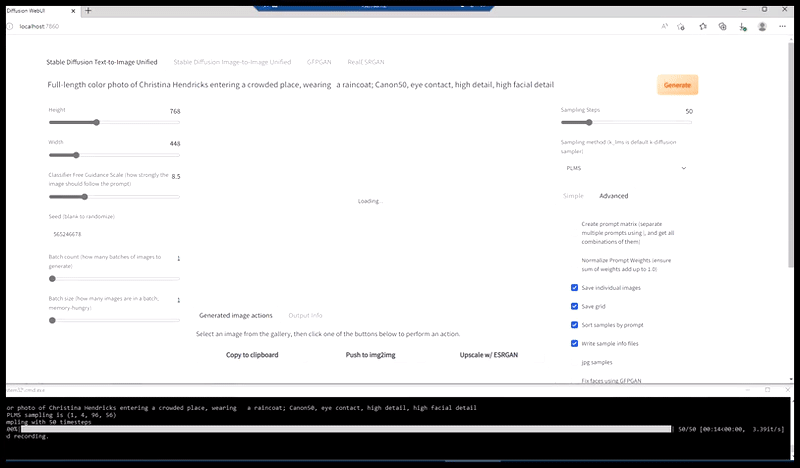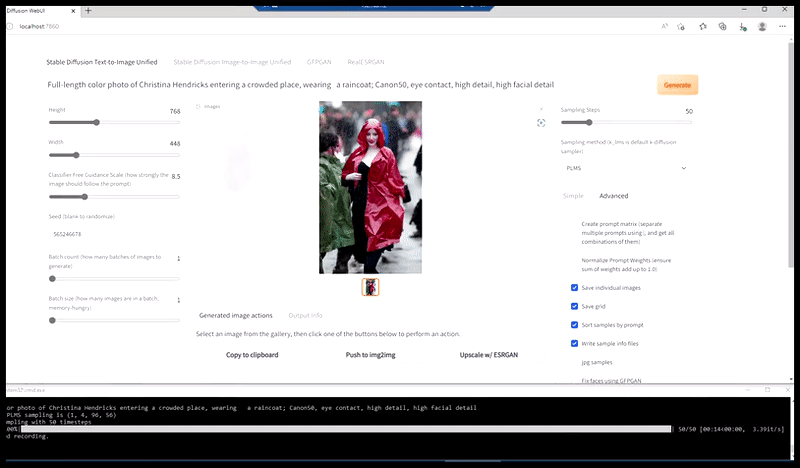
Erzeugung eines plausiblen Pressebildes mit dem Prompt ‘Vollständiges Farbfoto von Christina Hendricks, die einen überfüllten Ort betritt, einen Regenmantel tragend; Canon50, Augenkontakt, hohe Details, hohe Gesichtsdetails’.
Für Prominente mit langen und anhaltenden Karrieren wird Stable Diffusion normalerweise ein Bild der Person in einem jüngeren (d. h. älteren) Alter erzeugen, und es wird notwendig sein, Prompt-Ergänzungen wie ‘jung’ oder ‘im Jahr [JAHR]’ hinzuzufügen, um jüngere Bilder zu erzeugen.

Mit einer prominenten, viel fotografierten und konsistenten Karriere, die fast 40 Jahre umfasst, ist die Schauspielerin Jennifer Connelly eine von wenigen Prominenten in LAION, die es Stable Diffusion ermöglichen, ein Spektrum von Alterszuständen darzustellen. Quelle: prepack Stable Diffusion, lokal, v1.4-Checkpoint; altersbezogene Prompts.
Dies liegt hauptsächlich an der Verbreitung der digitalen (statt teuren, emulsionsbasierten) Pressefotografie ab Mitte der 2000er Jahre und dem späteren Anstieg der Bildausgabe aufgrund erhöhter Breitbandgeschwindigkeiten.
Das gerenderte Bild wird an Img2Img in Stable Diffusion weitergeleitet, wo ein ‘Fokus-Bereich’ ausgewählt wird, und ein neues, maximales Render nur für diesen Bereich erstellt wird, wodurch Stable Diffusion alle verfügbaren Ressourcen auf die Neuerstellung des Gesichts konzentrieren kann.
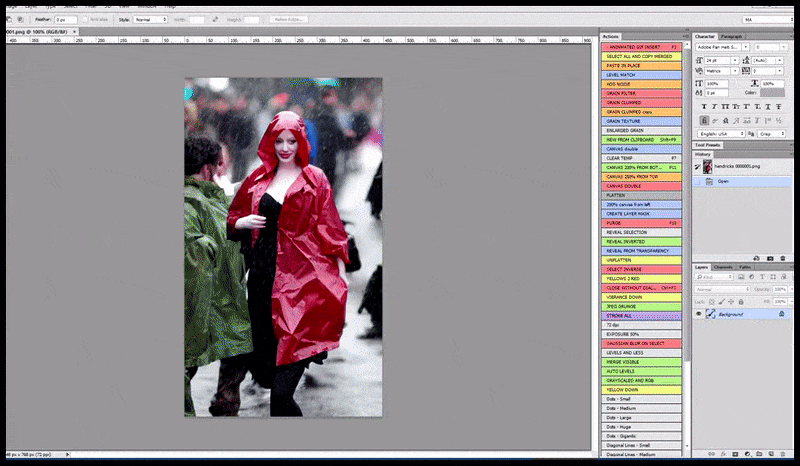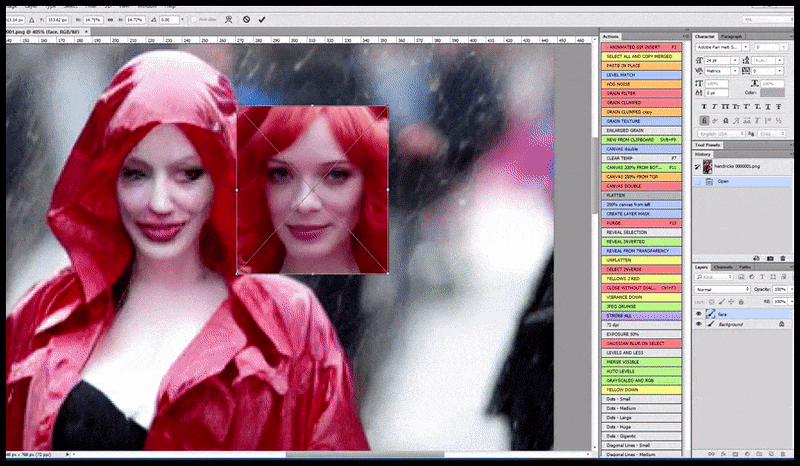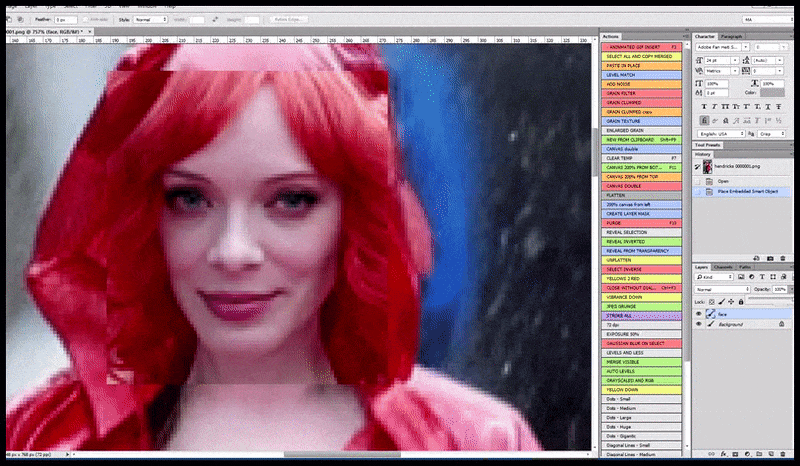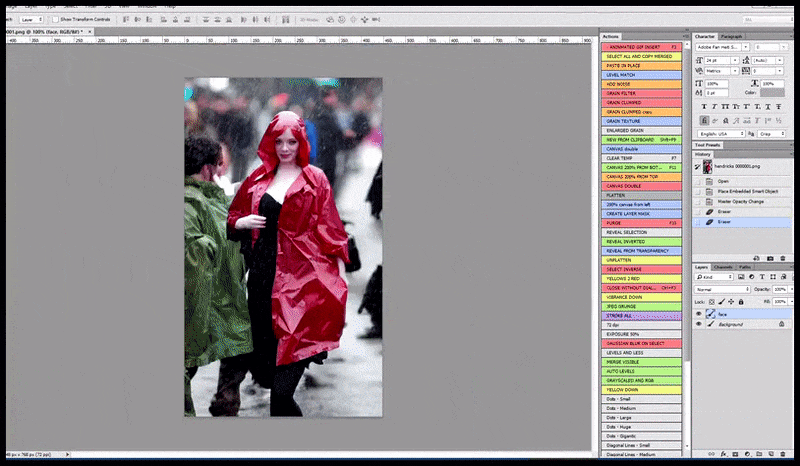
Zusammensetzung des ‘hochaufmerksamen’ Gesichts in das ursprüngliche Render. Neben Gesichtern wird dieser Prozess nur mit Entitäten funktionieren, die ein potenziell bekanntes, kohärentes und integrales Aussehen haben, wie z. B. ein Teil des ursprünglichen Fotos, das ein deutliches Objekt wie eine Uhr oder ein Auto hat. Das Aufskalieren eines Teils eines – z. B. einer Wand – wird zu einer sehr seltsam aussehenden zusammengesetzten Wand führen, da die Tile-Render keinen weiteren Kontext für dieses ‘Puzzleteil’ hatten, als sie gerendert wurden.
Einige Prominente in der Datenbank kommen ‘voreingefroren’ in der Zeit, entweder weil sie früh starben (wie Marilyn Monroe) oder nur vorübergehend in die Mainstream-Prominenz gelangten und eine hohe Anzahl von Bildern in einem begrenzten Zeitraum produzierten. Die Abfrage von Stable Diffusion bietet möglicherweise eine Art ‘aktuellen’ Beliebtheitsindex für moderne und ältere Stars. Für einige ältere und aktuelle Prominente gibt es nicht genug Bilder in den Quelldaten, um eine sehr gute Ähnlichkeit zu erhalten, während die anhaltende Popularität bestimmter lang verstorbener oder anderweitig verblasster Stars sicherstellt, dass ihre vernünftige Ähnlichkeit aus dem System abgerufen werden kann.

Stable-Diffusion-Renderings zeigen schnell, welche berühmten Gesichter gut in den Trainingsdaten vertreten sind. Trotz ihrer enormen Popularität als ältere Teenagerin zum Zeitpunkt des Schreibens war Millie Bobby Brown jünger und weniger bekannt, als die LAION-Quelldaten aus dem Web gesammelt wurden, was es derzeit problematisch macht, eine hochwertige Ähnlichkeit mit Stable Diffusion zu erhalten.
Wo die Daten verfügbar sind, könnten tile-basierte Auflösungs-Lösungen in Stable Diffusion weiter gehen, als nur auf das Gesicht zu zielen: Sie könnten möglicherweise sogar genauere und detailliertere Gesichter ermöglichen, indem sie die Gesichtszüge aufbrechen und die gesamten lokalen GPU-Ressourcen auf einzelne Merkmale konzentrieren, bevor sie sie wieder zusammenfügen – ein Prozess, der derzeit wieder manuell ist.

Dies ist nicht auf Gesichter beschränkt, aber es ist auf Teile von Objekten beschränkt, die mindestens so vorhersehbar in dem breiteren Kontext des Host-Objekts platziert sind und die zu hohen Einbettungen konform sind, die man vernünftigerweise in einem hyperskaligen Datensatz erwarten kann.
Die eigentliche Grenze ist die Menge an verfügbaren Referenzdaten im Datensatz, da letztendlich tief iterierte Details völlig ‘halluziniert’ (d. h. fiktiv) und weniger authentisch werden.
Solche hochstufigen granularen Vergrößerungen funktionieren im Fall von Jennifer Connelly, weil sie in LAION-Ästhetik (dem primären Sub-Set von LAION 5B, das Stable Diffusion verwendet) und im Allgemeinen in LAION gut vertreten ist; in vielen anderen Fällen würde die Genauigkeit aufgrund mangelnder Daten leiden, was entweder eine Feinabstimmung (zusätzliche Schulung, siehe ‘Anpassung’ unten) oder eine Textual-Inversion (siehe unten) erfordern würde.
Kacheln sind eine leistungsstarke und relativ billige Möglichkeit, Stable Diffusion in die Lage zu versetzen, hochauflösende Ausgaben zu produzieren, aber algorithmisches Kachel-Upscaling dieser Art, wenn es einem höheren, umfassenderen Aufmerksamkeitsmechanismus fehlt, kann möglicherweise den erhofften Standards über einen Bereich von Inhaltstypen nicht entsprechen.
2: Probleme mit menschlichen Extremitäten ansprechen
Stable Diffusion hält seinem Namen nicht stand, wenn es um die Komplexität menschlicher Extremitäten geht. Hände können sich willkürlich vermehren, Finger können zusammenfließen, ein drittes Bein kann ungewollt erscheinen und bestehende Gliedmaßen können spurlos verschwinden. In seiner Verteidigung teilt Stable Diffusion das Problem mit seinen Stablemates und sicherlich mit DALL-E 2.

Unbearbeitete Ergebnisse von DALL-E 2 und Stable Diffusion (1.4) Ende August 2022, beide zeigen Probleme mit Gliedmaßen. Prompt ist ‘Eine Frau umarmt einen Mann’
Stable-Diffusion-Fans, die hoffen, dass das kommende 1.5-Checkpoint (eine intensiver trainierte Version des Modells mit verbesserten Parametern) das Gliedmaßen-Chaos lösen würde, werden wahrscheinlich enttäuscht sein. Das neue Modell, das in etwa zwei Wochen veröffentlicht wird, wird derzeit am kommerziellen stability.ai-Portal DreamStudio premieriert, das 1.5 standardmäßig verwendet und wo Benutzer die neue Ausgabe mit Rendern von ihren lokalen oder anderen 1.4-Systemen vergleichen können:

Quelle: Lokal 1.4 prepack und https://beta.dreamstudio.ai/

Quelle: Lokal 1.4 prepack und https://beta.dreamstudio.ai/

Quelle: Lokal 1.4 prepack und https://beta.dreamstudio.ai/
Wie oft der Fall ist, könnte die Datenqualität der primäre beitragende Grund sein.
Die offenen Datenbanken, die Bildsynthesesysteme wie Stable Diffusion und DALL-E 2 antreiben, können viele Labels für einzelne Menschen und zwischenmenschliche Aktionen bereitstellen. Diese Labels werden mit ihren zugehörigen Bildern oder Bildsegmenten trainiert.

Stable-Diffusion-Benutzer können die in das Modell trainierten Konzepte durch Abfrage des LAION-Ästhetik-Datensatzes erkunden, eines Sub-sets des größeren LAION-5B-Datensatzes, der das System antreibt. Die Bilder sind nicht alphabetisch nach ihren Labels geordnet, sondern nach ihrem ‘Ästhetik-Score’. Quelle: https://rom1504.github.io/clip-retrieval/
Eine gute Hierarchie von individuellen Labels und Klassen, die zur Darstellung eines menschlichen Arms beitragen, wäre etwas wie Körper>Arm>Hand>Finger>[Unter-Digits + Daumen]>[Fingerglieder]>Fingernägel.

Granulare semantische Segmentierung der Teile einer Hand. Selbst diese ungewöhnlich detaillierte Dekonstruktion lässt jeden ‘Finger’ als einzige Entität, ohne die drei Abschnitte eines Fingers und die zwei Abschnitte eines Daumens zu berücksichtigen. Quelle: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
In Wirklichkeit sind die Quelldaten wahrscheinlich nicht so konsistent annotiert über den gesamten Datensatz, und unsupervised Labeling-Algorithmen werden wahrscheinlich auf der höheren Ebene von – zum Beispiel – ‘Hand’ stoppen und die internen Pixel (die technisch gesehen Finger-Informationen enthalten) als ungelabelte Masse von Pixeln belassen, aus denen Funktionen willkürlich abgeleitet werden und die möglicherweise später als störendes Element in Rendern manifestieren.

Wie es sein sollte (obere rechte, wenn nicht obere Kante), und wie es tendenziell ist (untere rechte), aufgrund begrenzter Ressourcen für die Markierung oder der architektonischen Ausbeutung solcher Markierungen, wenn sie im Datensatz vorhanden sind.
Somit wird, wenn ein latentes Diffusionsmodell es schafft, einen Arm zu rendern, es fast sicherlich zumindest versuchen, eine Hand am Ende dieses Arms zu rendern, weil Arm>Hand die minimale erforderliche Hierarchie ist, ziemlich weit oben in dem, was die Architektur über ‘menschliche Anatomie’ weiß.
Danach können ‘Finger’ die kleinste Gruppierung sein, obwohl es 14 weitere Finger-/Daumen-Teile gibt, die bei der Darstellung menschlicher Hände berücksichtigt werden müssen.
Wenn diese Theorie gilt, gibt es keine echte Abhilfe, aufgrund des branchenweiten Mangels an Budget für manuelle Markierung und des Mangels an ausreichend effektiven Algorithmen, die die Markierung automatisieren und gleichzeitig niedrige Fehlerraten produzieren könnten. In der Tat könnte das Modell derzeit auf die menschliche anatomische Konsistenz angewiesen sein, um die Mängel des Datensatzes, auf dem es trainiert wurde, zu überbrücken.
Ein möglicher Grund, warum es nicht darauf angewiesen sein kann, wurde kürzlich im Stable-Diffusion-Discord vorgeschlagen, ist, dass das Modell verwirrt werden könnte, wie viele Finger eine (realistische) menschliche Hand haben sollte, weil die LAION-abgeleitete Datenbank, die es antreibt, Cartoon-Charaktere enthält, die möglicherweise weniger Finger haben (was selbst eine Arbeitsersparnis ist).

Zwei der potenziellen Täter im ‘fehlenden Finger’-Syndrom in Stable Diffusion und ähnlichen Modellen. Unten, Beispiele für Cartoon-Handen aus dem LAION-Ästhetik-Datensatz, der Stable Diffusion antreibt. Quelle: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Wenn dies zutrifft, gibt es nur eine offensichtliche Lösung: das Modell neu zu trainieren, wobei nicht-realitätsbezogenes menschliches Material ausgeschlossen wird, um sicherzustellen, dass echte Fälle von Auslassungen (d. h. Amputierte) als Ausnahmen gekennzeichnet sind. Allein aus dem Blickwinkel der Datenkuratie wäre dies eine ziemliche Herausforderung, insbesondere für ressourcenarme Community-Bemühungen.
Die zweite Herangehensweise wäre, Filter anzuwenden, die solche Inhalte (d. h. ‘Hand mit drei/fünf Fingern’) vom Manifestieren zur Laufzeit ausschließen, ähnlich wie OpenAI gefiltert hat GPT-3 und DALL-E 2, um ihre Ausgabe zu regulieren, ohne die Quellmodelle neu trainieren zu müssen.

Für Stable Diffusion kann die semantische Unterscheidung zwischen Ziffern und sogar Gliedmaßen grotesk verwischt werden, was an die 1980er ‘Body-Horror’-Strang von Horrorfilmen von Regisseuren wie David Cronenberg erinnert. Quelle: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Es könnte jedoch argumentiert werden, dass es zwei verbleibende Wege nach vorne gibt: mehr Daten auf das Problem zu werfen und die Anwendung von Drittanbieter-interpretativen Systemen, die eingreifen können, wenn physikalische Fehler der beschriebenen Art dem Endbenutzer präsentiert werden (zumindest würde dies OpenAI eine Methode geben, um Rückerstattungen für ‘Body-Horror’-Rendern anzubieten, wenn das Unternehmen motiviert wäre, dies zu tun).
3: Anpassung
Eine der aufregendsten Möglichkeiten für die Zukunft von Stable Diffusion ist die Aussicht, dass Benutzer oder Organisationen überarbeitete Systeme entwickeln; Modifikationen, die es ermöglichen, Inhalte außerhalb der vorgebildeten LAION-Sphäre in das System zu integrieren – idealerweise ohne die unkontrollierbaren Kosten des erneuten Trainings des gesamten Modells oder das Risiko, das mit dem Training in einer großen Anzahl neuer Bilder an einem etablierten, ausgereiften und leistungsfähigen Modell verbunden ist.
Durch Analogie: Wenn zwei weniger begabte Schüler einer Klasse von 30 Schülern beitreten, werden sie entweder assimiliert und aufholen oder als Außenseiter scheitern; in beiden Fällen wird die Durchschnittsleistung der Klasse wahrscheinlich nicht beeinträchtigt. Wenn jedoch 15 weniger begabte Schüler beitreten, wird die Notenkurve für die gesamte Klasse wahrscheinlich leiden.
Ebenso kann die synergistische und ziemlich empfindliche Netzwerkbeziehung, die während eines anhaltenden und teuren Modelltrainings aufgebaut wird, durch exzessive neue Daten kompromittiert, in einigen Fällen effektiv zerstört werden, was die Ausgabqualität des Modells insgesamt senkt.
Der Fall für die Durchführung dieser Maßnahme ist in erster Linie dort, wo Ihr Interesse darin besteht, das konzeptionelle Verständnis des Modells von Beziehungen und Dingen vollständig zu übernehmen und es für die exklusive Produktion von Inhalten zu nutzen, die dem zusätzlichen Material ähnlich sind, das Sie hinzugefügt haben.
Somit wird das Training von 500.000 Simpsons-Frames in einen bestehenden Stable-Diffusion-Checkpoint wahrscheinlich letztendlich zu einem besseren Simpsons-Simulator führen, als es das ursprüngliche Build hätte bieten können, vorausgesetzt, dass genügend breite semantische Beziehungen den Prozess überstehen (d. h. Homer Simpson isst einen Hotdog, was Material über Hotdogs erfordern könnte, das nicht in Ihrem zusätzlichen Material vorhanden war, aber bereits im Checkpoint existierte) und vorausgesetzt, dass Sie nicht plötzlich von Simpsons-Inhalten zu fabulous landscape by Greg Rutkowski wechseln möchten – weil Ihr post-trainiertes Modell seine Aufmerksamkeit massiv abgelenkt hat und nicht mehr so gut darin ist, diese Art von Dingen zu tun, wie es es früher war.
Ein bemerkenswertes Beispiel dafür ist waifu-diffusion, das erfolgreich 56.000 Anime-Bilder in einen abgeschlossenen und trainierten Stable-Diffusion-Checkpoint post-trainiert hat. Es ist jedoch ein schwieriges Vorhaben für einen Hobbyisten, da das Modell ein atemberaubendes Minimum von 30 GB VRAM erfordert, weit über dem, was wahrscheinlich auf der Verbraucherebene in den kommenden 40XX-Veröffentlichungen von NVIDIA verfügbar sein wird.

Das Training von benutzerdefinierten Inhalten in Stable Diffusion via waifu-diffusion: Das Modell benötigte zwei Wochen Post-Training, um diese Ebene der Illustration zu erreichen. Die sechs Bilder auf der linken Seite zeigen den Fortschritt des Modells, während es trainiert wurde, in der Erstellung von subjekt-coherenter Ausgabe auf der Grundlage der neuen Trainingsdaten. Quelle: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Eine große Anstrengung könnte auf solche ‘Forks’ von Stable-Diffusion-Checkpoints verwendet werden, nur um von technischer Schulden behindert zu werden. Entwickler im offiziellen Discord haben bereits angegeben, dass spätere Checkpoint-Veröffentlichungen nicht unbedingt rückwärtskompatibel sein werden, selbst mit Prompt-Logik, die mit einer früheren Version funktioniert hat, da ihr Hauptinteresse darin besteht, das beste Modell zu erhalten, anstatt Legacy-Anwendungen und -Prozesse zu unterstützen.
Daher hat eine Firma oder Person, die sich entscheidet, einen Checkpoint in ein kommerzielles Produkt zu forkern, effektiv keinen Weg zurück; ihre Version des Modells ist zu diesem Zeitpunkt ein ‘Hard-Fork’, und kann nicht mehr von den Vorteilen späterer Veröffentlichungen von stability.ai profitieren – was ein ziemlicher Engagement ist.
Die aktuelle und größere Hoffnung für die Anpassung von Stable Diffusion ist Textual-Inversion, bei der der Benutzer ein paar CLIP-ausgerichtete Bilder trainiert.

Eine Zusammenarbeit zwischen der Universität Tel Aviv und NVIDIA, ermöglicht die textuelle Inversion die Einbindung von diskreten und neuen Entitäten, ohne die Fähigkeiten des Quellmodells zu zerstören. Quelle: https://textual-inversion.github.io/
Die primäre offensichtliche Einschränkung der textuellen Inversion ist, dass eine sehr geringe Anzahl von Bildern empfohlen wird – so wenig wie fünf. Dies produziert effektiv eine begrenzte Entität, die möglicherweise eher für Style-Transfer-Aufgaben als für die Einbindung von photorealistischen Objekten nützlich ist.
Trotzdem finden derzeit Experimente in den verschiedenen Stable-Diffusion-Discords statt, die eine viel höhere Anzahl von Trainingsbildern verwenden, und es bleibt abzuwarten, wie produktiv die Methode sich erweisen wird. Wiederum erfordert die Technik eine große Menge VRAM, Zeit und Geduld.
Aufgrund dieser begrenzenden Faktoren müssen wir möglicherweise eine Weile warten, um einige der anspruchsvolleren textuellen Inversions-Experimente von Stable-Diffusion-Enthusiasten zu sehen – und um zu sehen, ob dieser Ansatz Sie ‘in das Bild’ setzen kann, auf eine Weise, die besser aussieht als ein Photoshop-Cut-and-Paste, während die atemberaubende Funktionalität der offiziellen Checkpoints erhalten bleibt.
Erstveröffentlicht am 6. September 2022.












