Andersons Blickwinkel
HunyuanCustom bringt Single-Image-Video-Deepfakes mit Audio und Lip-Sync
Dieser Artikel diskutiert eine neue Version eines multimodalen Hunyuan-Video-Modells namens “HunyuanCustom”. Die Breite der Abdeckung des neuen Papiers, kombiniert mit mehreren Problemen in vielen der bereitgestellten Beispielvideos auf der Projektseite*, beschränkt uns auf eine allgemeinere Abdeckung als üblich und auf eine begrenzte Wiedergabe der riesigen Menge an Videomaterial, das dieser Veröffentlichung beigefügt ist (da viele der Videos erhebliche Nachbearbeitung und Verarbeitung erfordern, um die Lesbarkeit des Layouts zu verbessern).
Bitte beachten Sie zusätzlich, dass das Papier das API-basierte generative System Kling als “Keling” bezeichnet. Für Klarheit bezeichne ich es hier als “Kling”.
Tencent ist dabei, eine neue Version seines Hunyuan-Video-Modells zu veröffentlichen, mit dem Titel HunyuanCustom. Die neue Veröffentlichung ist offensichtlich in der Lage, Hunyuan-LoRA-Modelle überflüssig zu machen, indem sie dem Benutzer ermöglicht, “Deepfake”-Stil-Video-Anpassungen durch ein einziges Bild zu erstellen:
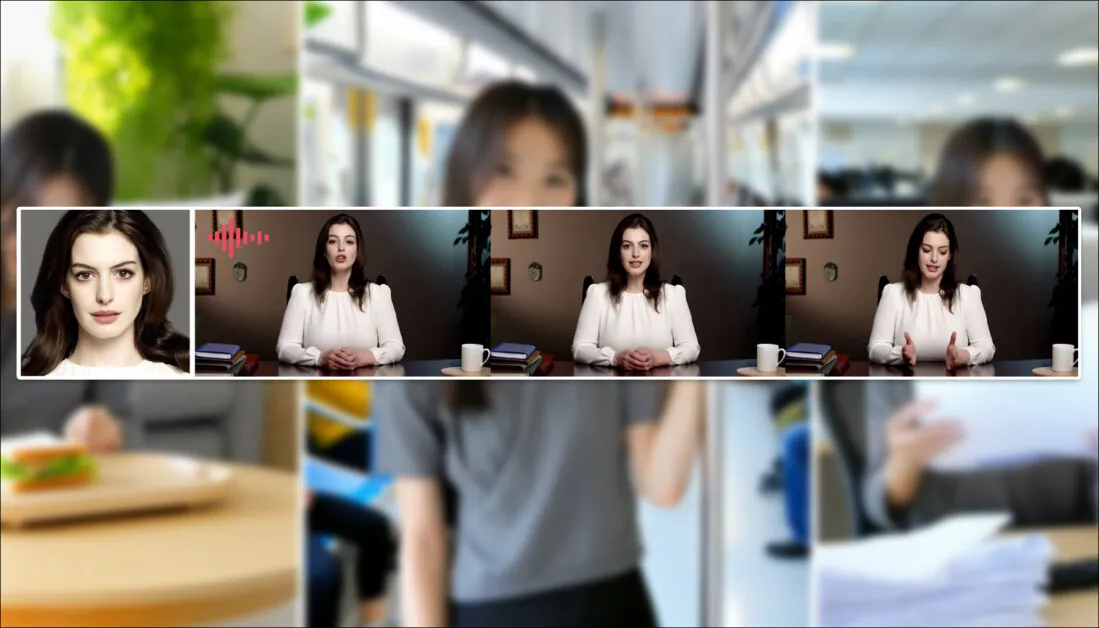
Bitte klicken Sie, um abzuspielen. Prompt: “Ein Mann hört Musik und kocht Schnecken-Nudeln in der Küche”. Die neue Methode im Vergleich zu Close-Source- und Open-Source-Methoden, einschließlich Kling, das ein bedeutender Gegner in diesem Bereich ist. Quelle: https://hunyuancustom.github.io/ (Hinweis: CPU-/Speicher-intensiv!
In der linken Spalte des obigen Videos sehen wir das einzige Quellbild, das HunyuanCustom zur Verfügung gestellt wurde, gefolgt von der Interpretation des Systems der Prompt in der zweiten Spalte. Die restlichen Spalten zeigen die Ergebnisse aus verschiedenen proprietären und FOSS-Systemen: Kling; Vidu; Pika; Hailuo; und das Wan-basierte SkyReels-A2.
In dem folgenden Video sehen wir Renders von drei Szenarien, die für diese Veröffentlichung wesentlich sind: jeweils Person + Objekt; Einzelcharakter-Emulation; und virtuelles Anprobieren (Person + Kleidung):
Bitte klicken Sie, um abzuspielen.Drei Beispiele, die aus dem Material auf der unterstützenden Seite für Hunyuan-Video bearbeitet wurden.
Wir können einige Dinge aus diesen Beispielen erkennen, die hauptsächlich mit dem System zusammenhängen, das auf einem einzelnen Quellbild basiert, anstatt auf mehreren Bildern desselben Subjekts.
In dem ersten Clip sieht der Mann im Wesentlichen direkt in die Kamera. Er senkt seinen Kopf nach unten und zur Seite um nicht mehr als 20-25 Grad Rotation, aber bei einer Neigung, die diese übersteigt, müsste das System wirklich anfangen, zu erraten, wie er im Profil aussieht. Dies ist schwierig, wahrscheinlich unmöglich, aus einem einzigen Frontalbild zu beurteilen.
In dem zweiten Beispiel sehen wir, dass das kleine Mädchen lächelt im gerenderten Video, wie es auch im einzigen statischen Quellbild der Fall ist. Wiederum müsste HunyuanCustom mit diesem einzigen Bild als Referenz eine relativ unbegründete Vermutung über das Aussehen seines “Ruhegesichts” anstellen. Darüber hinaus weicht sein Gesicht nicht mehr als im vorherigen Beispiel (“Mann, der Chips isst”) von der Kameraposition ab.
In dem letzten Beispiel sehen wir, dass, da das Quellmaterial – die Frau und die Kleidung, die sie angezogen hat – keine vollständigen Bilder sind, der Render die Szene beschnitten hat, um sie anzupassen – was tatsächlich eine ziemlich gute Lösung für ein Datenproblem ist!
Der Punkt ist, dass, obwohl das neue System mehrere Bilder (wie Person + Chips oder Person + Kleidung) verarbeiten kann, es offensichtlich nicht ermöglicht, mehrere Winkel oder alternative Ansichten einer einzelnen Person zu berücksichtigen, so dass diverse Ausdrucksformen oder ungewöhnliche Winkel berücksichtigt werden könnten. In diesem Sinne könnte das System möglicherweise Schwierigkeiten haben, die wachsende Ökonomie der LoRA-Modelle zu ersetzen, die um HunyuanVideo herum entstanden sind, seit es im vergangenen Dezember veröffentlicht wurde, da diese HunyuanVideo helfen können, konsistente Charaktere aus jedem Winkel und mit jedem im Trainingsdatensatz dargestellten Gesichtsausdruck zu erzeugen (20-60 Bilder sind typisch).
Verdrahtet für Sound
Für Audio nutzt HunyuanCustom das LatentSync-System (das für Hobbyisten bekanntermaßen schwer zu installieren und zu verwenden ist) für die Erzeugung von Lipbewegungen, die mit Audio und Text übereinstimmen, die der Benutzer bereitstellt:
Bitte klicken Sie, um abzuspielen. Enthält Audio.Verschiedene Beispiele für Lip-Sync aus der HunyuanCustom-Ergänzungsseite, die zusammen bearbeitet wurden.
Zum Zeitpunkt des Schreibens gibt es keine englischsprachigen Beispiele, aber diese scheinen ziemlich gut zu sein – umso mehr, wenn die Methode, sie zu erstellen, leicht installierbar und zugänglich ist.
Bearbeitung von bestehenden Videos
Das neue System bietet anscheinend sehr beeindruckende Ergebnisse für Video-zu-Video-(V2V, oder Vid2Vid)-Bearbeitung, bei der ein Segment eines bestehenden (echten) Videos maskiert und durch ein Subjekt ersetzt wird, das in einem einzigen Referenzbild gegeben ist. Hier ist ein Beispiel von der Ergänzungsseite:
Bitte klicken Sie, um abzuspielen.Nur das zentrale Objekt wird gezielt, aber auch das, was um es herum bleibt, wird durch einen HunyuanCustom-Vid2Vid-Durchlauf geändert.
Wie wir sehen können und wie es in einem Vid2Vid-Szenario üblich ist, wird das gesamte Video durch den Prozess in gewissem Umfang geändert, obwohl es am stärksten im Zielbereich geändert wird, d. h. dem Plüschspielzeug. Es ist anzunehmen, dass Pipelines entwickelt werden könnten, um solche Transformationen unter einem Garbage-Matte-Ansatz zu erstellen, der den größten Teil des Videoinhalts identisch mit dem Original lässt. Dies ist das, was Adobe Firefly unter der Haube tut und ziemlich gut macht – aber es ist ein untersuchter Prozess in der FOSS-Generierungs-Szene.
Wie bereits erwähnt, tun die meisten der alternativen Beispiele, die bereitgestellt werden, einen besseren Job bei der gezielten Integration dieser Inhalte, wie wir in der folgenden Zusammenstellung sehen können:
Bitte klicken Sie, um abzuspielen.Vielfältige Beispiele für injizierte Inhalte unter Verwendung von Vid2Vid in HunyuanCustom, die eine bemerkenswerte Rücksichtnahme auf das nicht gezielte Material zeigen.
Ein neuer Anfang?
Diese Initiative ist eine Entwicklung des Hunyuan-Video-Projekts und kein harter Wechsel von dieser Entwicklungslinie weg. Die Verbesserungen des Projekts werden als diskrete architektonische Einfügungen eingeführt und nicht als umfassende strukturelle Änderungen, mit dem Ziel, dem Modell die Fähigkeit zu geben, die Identität über Frames hinweg beizubehalten, ohne auf subjektspezifische Feinabstimmung angewiesen zu sein, wie bei LoRA- oder textuellen Inversionsansätzen.
Zu klären, HunyuanCustom ist nicht von Grund auf trainiert, sondern eine Feinabstimmung des Hunyuan-Video-Grundmodells von Dezember 2024.
Diejenigen, die Hunyuan-Video-LoRAs entwickelt haben, könnten sich fragen, ob diese noch mit dieser neuen Version funktionieren oder ob sie das LoRA-Rad noch einmal erfinden müssen, wenn sie mehr Anpassungsfähigkeiten als die, die in dieser neuen Veröffentlichung integriert sind, wünschen.
Im Allgemeinen ändert eine stark feinabgestimmte Veröffentlichung eines Hyperscale-Modells die Modellgewichte so sehr, dass LoRAs, die für das frühere Modell erstellt wurden, nicht ordnungsgemäß oder überhaupt nicht mit dem neu verfeinerten Modell funktionieren.
Manchmal jedoch kann die Popularität einer Feinabstimmung ihre Ursprünge in Frage stellen: Ein Beispiel für eine Feinabstimmung, die zu einem effektiven Fork wird, mit einer eigenen Ökonomie und Anhängern, ist die Pony-Diffusion-Feinabstimmung von Stable Diffusion XL (SDXL). Pony hat derzeit 592.000+ Downloads auf dem stets wechselnden CivitAI-Domain, mit einer riesigen Anzahl von LoRAs, die Pony (und nicht SDXL) als Basis-Modell verwendet haben und die Pony bei der Inferenzzeit erfordern.
Veröffentlichung
Die Projektseite für das neue Papier (das den Titel HunyuanCustom: Eine multimodale Architektur für benutzerdefinierte Videoerzeugung trägt) enthält Links zu einer GitHub-Seite, die, als ich schreibe, gerade funktionsfähig geworden ist und Code und notwendige Gewichte für die lokale Implementierung enthält, zusammen mit einem vorgeschlagenen Zeitplan (wo das einzige wichtige Thema, das noch zu kommen ist, die ComfyUI-Integration ist).
Zum Zeitpunkt des Schreibens ist die Hugging-Face-Präsenz des Projekts noch ein 404er. Es gibt jedoch eine API-basierte Version, bei der man offensichtlich das System demonstrieren kann, solange man einen WeChat-Scan-Code bereitstellen kann.
Ich habe selten eine so umfangreiche und ausführliche Verwendung einer solchen Vielzahl von Projekten in einer Montage gesehen, wie es in HunyuanCustom der Fall ist – und vermutlich würden einige der Lizenzen ohnehin eine vollständige Veröffentlichung erfordern.
Zwei Modelle werden auf der GitHub-Seite angekündigt: Ein 720px1280px-Modell, das 8 GB GPU-Speicher erfordert, und ein 512px896px-Modell, das 60 GB GPU-Speicher erfordert.
Das Repository besagt: ‘Das minimale erforderliche GPU-Speicher ist 24 GB für 720px1280px129f, aber sehr langsam… Wir empfehlen die Verwendung einer GPU mit 80 GB Speicher für eine bessere Generierungsqualität’ – und wiederholt, dass das System bisher nur auf Linux getestet wurde.
Das frühere Hunyuan-Video-Modell wurde seit seiner offiziellen Veröffentlichung quantisiert auf Größen, bei denen es auf weniger als 24 GB VRAM ausgeführt werden kann, und es ist vernünftig anzunehmen, dass das neue Modell auf ähnliche Weise in consumerfreundlichere Formen von der Community adaptiert wird und dass es schnell für den Einsatz auf Windows-Systemen adaptiert wird.
Aufgrund von Zeitbeschränkungen und der überwältigenden Menge an Informationen, die diese Veröffentlichung begleiten, können wir nur einen breiteren, anstatt einen detaillierten Blick auf diese Veröffentlichung werfen. Dennoch lassen wir den Motor von HunyuanCustom ein wenig an.
Blick auf das Papier
Die Datenpipeline für HunyuanCustom, die offensichtlich den GDPR-Rahmenwerk einhält, umfasst sowohl synthetisierte als auch Open-Source-Video-Datensätze, einschließlich OpenHumanVid, mit acht Kernkategorien, die vertreten sind: Menschen, Tiere, Pflanzen, Landschaften, Fahrzeuge, Objekte, Architektur und Anime.

Aus dem Veröffentlichungspapier, eine Übersicht über die verschiedenen Beitragspakete in der HunyuanCustom-Datenkonstruktionspipeline. Quelle: https://arxiv.org/pdf/2505.04512
Die anfängliche Filterung beginnt mit PySceneDetect, das Videos in einzelne Clips segmentiert. TextBPN-Plus-Plus wird dann verwendet, um Videos zu entfernen, die übermäßigen On-Screen-Text, Untertitel, Wasserzeichen oder Logos enthalten.
Um Inkonsistenzen in Auflösung und Dauer zu behandeln, werden Clips standardisiert auf fünf Sekunden Länge und auf 512 oder 720 Pixel auf der kurzen Seite vergrößert. Die ästhetische Filterung wird mit Koala-36M durchgeführt, mit einem benutzerdefinierten Schwellenwert von 0,06, der auf das benutzerdefinierte Datenset der Forscher des Papiers angewendet wird.
Der Prozess der Subjekterkennung kombiniert das Qwen7B-Large-Language-Modell (LLM), das YOLO11X-Objekterkennungsframework und die beliebte InsightFace-Architektur, um menschliche Identitäten zu erkennen und zu validieren.
Für nicht-menschliche Subjekte werden QwenVL und Grounded SAM 2 verwendet, um relevante Begrenzungsboxen zu extrahieren, die verworfen werden, wenn sie zu klein sind.

Beispiele für semantische Segmentierung mit Grounded SAM 2, die im Hunyuan-Control-Projekt verwendet werden. Quelle: https://github.com/IDEA-Research/Grounded-SAM-2
Die Multi-Subjekterkennung verwendet Florence2 für die Begrenzungsboxen-Annotierung und Grounded SAM 2 für die Segmentierung, gefolgt von Clustering und zeitlicher Segmentierung der Trainingsframes.
Die verarbeiteten Clips werden weiter durch Annotierung verbessert, unter Verwendung eines proprietären strukturierten Beschriftungssystems, das von dem Hunyuan-Team entwickelt wurde und das schichtweise Metadaten wie Beschreibungen und Kamerabewegungshinweise liefert.
Masken-Verstärkungsstrategien, einschließlich der Umwandlung in Begrenzungsboxen, wurden während des Trainings angewendet, um Überanpassung zu reduzieren und sicherzustellen, dass das Modell sich an verschiedene Objektformen anpasst.
Audio-Daten wurden mit dem erwähnten LatentSync synchronisiert und Clips verworfen, wenn die Synchronisationswerte unter einem Mindestschwellenwert lagen.
Das blinden Bildqualitätsbewertungsframework HyperIQA wurde verwendet, um Videos auszuschließen, die unter 40 (auf der HyperIQA-eigenen Skala) punkteten. Gültige Audio-Tracks wurden dann mit Whisper verarbeitet, um Merkmale für nachgelagerte Aufgaben zu extrahieren.
Die Autoren integrieren das LLaVA-Sprachassistentenmodell während der Annotierungsphase und betonen die zentrale Position, die dieses Framework in HunyuanCustom einnimmt. LLaVA wird verwendet, um Bildbeschriftungen zu generieren und die visuelle Inhalte mit Text-Prompts zu verbinden, um die Konstruktion eines kohärenten Trainings-Signals über Modalitäten hinweg zu unterstützen:

Das HunyuanCustom-Framework unterstützt identitätskonsistente Videoerzeugung, die auf Text-, Bild-, Audio- und Video-Eingaben bedingt ist.
Durch die Nutzung der visuell-sprachlichen Ausrichtungsfähigkeiten von LLaVA gewinnt die Pipeline eine zusätzliche Schicht semantischer Konsistenz zwischen visuellen Elementen und ihren textlichen Beschreibungen – insbesondere wertvoll in Multi-Subjekt- oder komplexen Szenarien.
Benutzerdefiniertes Video
Um Videoerzeugung auf der Grundlage eines Referenzbilds und eines Prompts zu ermöglichen, wurden die beiden Module, die sich um LLaVA drehen, erstellt, indem zunächst die Eingabe-Struktur von Hunyuan-Video so angepasst wurde, dass es ein Bild zusammen mit Text akzeptieren konnte.
Dies erforderte die Formatierung des Prompts auf eine Weise, die das Bild direkt einbettet oder es mit einer kurzen Identitätsbeschreibung markiert. Ein Trenntoken wurde verwendet, um zu verhindern, dass die Bild-Einbettung den Prompt-Inhalt überwältigt.
Da der visuelle Encoder von LLaVA dazu neigt, feinkörnige räumliche Details während der Ausrichtung von Bild- und Text-Merkmalen zu komprimieren oder zu verwerfen (insbesondere wenn ein einzelnes Referenzbild in eine allgemeine semantische Einbettung übersetzt wird), wurde ein Identitäts-Verbesserungsmodul integriert. Da fast alle Video-Latent-Diffusionsmodelle Schwierigkeiten haben, die Identität ohne LoRA aufrechtzuerhalten, selbst in einem fünfsekündigen Clip, kann die Leistung dieses Moduls in der Community-Testung von Bedeutung sein.
Auf jeden Fall wird das Referenzbild dann vergrößert und mit dem kausalen 3D-VAE aus dem ursprünglichen Hunyuan-Video-Modell codiert, und sein Latent wird in das Video-Latent über die zeitliche Achse eingefügt, wobei ein räumlicher Offset angewendet wird, um zu verhindern, dass das Bild direkt in der Ausgabe reproduziert wird, während es dennoch die Erzeugung leitet.
Das Modell wurde mit Flow-Matching trainiert, wobei Rauschproben aus einer logit-normalen Verteilung gezogen wurden – und das Netzwerk wurde trainiert, das korrekte Video aus diesen rauschigen Latents zu rekonstruieren. LLaVA und der Video-Generator wurden beide gemeinsam feinabgestimmt, um sicherzustellen, dass das Bild und der Prompt die Ausgabe flüssiger leiten und die Subjekts-Identität konsistent halten.
Für Multi-Subjekt-Prompts wurden jedes Bild-Text-Paar separat eingebettet und einer eindeutigen zeitlichen Position zugewiesen, um Identitäten zu unterscheiden und die Erzeugung von Szenen mit mehreren interagierenden Subjekten zu unterstützen.
Klang und Vision
HunyuanCustom bedingt Audio/Sprachenerzeugung unter Verwendung von Benutzereingabe-Audio und einem Text-Prompt, um es Charakteren zu ermöglichen, in Szenen zu sprechen, die die beschriebene Umgebung widerspiegeln.
Um dies zu unterstützen, führt ein Identitäts-entkoppeltes AudioNet-Modul Audio-Merkmale ein, ohne die Identitätssignale zu stören, die aus dem Referenzbild und dem Prompt eingebettet sind. Diese Merkmale werden mit der komprimierten Video-Zeitachse ausgerichtet, in framebasierte Segmente unterteilt und mit einem räumlichen Cross-Attention-Mechanismus injiziert, der jeden Frame isoliert hält und die Subjektkonsistenz bewahrt und zeitliche Interferenzen vermeidet.
Ein zweites zeitliches Injektionsmodul bietet eine feinere Kontrolle über Timing und Bewegung, arbeitet in Verbindung mit AudioNet und kartiert Audio-Merkmale auf bestimmte Bereiche der Latent-Sequenz und verwendet ein Multi-Layer-Perceptron (MLP), um sie in Token-weise Bewegungs-Offsets umzuwandeln. Dies ermöglicht es, dass Gesten und Gesichtsbewegungen dem Rhythmus und der Betonung der gesprochenen Eingabe mit größerer Präzision folgen.
HunyuanCustom ermöglicht es, Subjekte in bestehenden Videos direkt zu bearbeiten, sie durch Menschen oder Objekte in einer Szene zu ersetzen oder einzufügen, ohne dass das gesamte Clip von Grund auf neu aufgebaut werden muss. Dies macht es nützlich für Aufgaben, die das gezielte Ändern von Erscheinungsbild oder Bewegung beinhalten.
Bitte klicken Sie, um abzuspielen.Ein weiteres Beispiel von der Ergänzungsseite.
Um eine effiziente Subjektersatz in bestehenden Videos zu ermöglichen, vermeidet das neue System den ressourcenintensiven Ansatz von aktuellen Methoden wie dem derzeit populären VACE oder solchen, die ganze Video-Sequenzen zusammenfügen, und bevorzugt stattdessen die Komprimierung eines Referenz-Videos unter Verwendung des vorgefertigten kausalen 3D-VAE – Ausrichten mit der Generierungs-Pipeline internen Video-Latents und dann Addition der beiden. Dies hält den Prozess relativ leicht, während es gleichzeitig ermöglicht, dass externe Video-Inhalte die Ausgabe leiten.
Ein kleines neuronales Netzwerk behandelt die Ausrichtung zwischen dem sauberen Eingabe-Video und den rauschigen Latents, die bei der Generierung verwendet werden. Das System testet zwei Methoden, um diese Informationen einzuführen: Mischen der beiden Merkmals-Sätze, bevor sie erneut komprimiert werden; und Hinzufügen der Merkmale Frame für Frame. Die zweite Methode funktioniert besser, wie die Autoren feststellten, und vermeidet Qualitätsverlust, während die Rechenlast unverändert bleibt.
Daten und Tests
In den Tests wurden die folgenden Metriken verwendet: Die Identitätskonsistenz-Modul in ArcFace, die Gesichts-Embeddings aus dem Referenzbild und jedem Frame des generierten Videos extrahiert und dann den Durchschnitt der Kosinus-Ähnlichkeit zwischen ihnen berechnet; Subjekts-Ähnlichkeit, über die YOLO11X-Segmente an Dino 2 gesendet werden, um einen Vergleich zu ermöglichen; CLIP-B, Text-Video-Ausrichtung, die die Ähnlichkeit zwischen dem Prompt und dem generierten Video misst; CLIP-B erneut, um die Ähnlichkeit zwischen jedem Frame und sowohl seinen benachbarten Frames als auch dem ersten Frame zu berechnen, sowie zeitliche Konsistenz; und Dynamischer Grad, wie in VBench definiert.
Wie bereits erwähnt, waren die Baseline-Geschlossene-Quelle-Konkurrenten Hailuo; Vidu 2.0; Kling (1.6); und Pika. Die konkurrierenden FOSS-Frameworks waren VACE und SkyReels-A2.

Modellleistungsbewertung, die HunyuanCustom mit führenden Video-Anpassungsmethoden über ID-Konsistenz (Face-Sim), Subjekts-Ähnlichkeit (DINO-Sim), Text-Video-Ausrichtung (CLIP-B-T), zeitliche Konsistenz (Temp-Consis) und Bewegungsintensität (DD) vergleicht. Optimal und suboptimal Ergebnisse sind in fett und unterstrichen dargestellt.
Von diesen Ergebnissen aus sagen die Autoren:
‘Unser [HunyuanCustom] erreicht die beste ID-Konsistenz und Subjekts-Konsistenz. Es erreicht auch vergleichbare Ergebnisse in Prompt-Folge und zeitlicher Konsistenz. [Hailuo] hat den besten Clip-Score, da es Text-Anweisungen gut befolgen kann, mit nur ID-Konsistenz, auf Kosten der Konsistenz nicht-menschlicher Subjekte (die schlechteste DINO-Sim). In Bezug auf Dynamischen Grad erzielen [Vidu] und [VACE] schlechte Ergebnisse, was möglicherweise auf die geringe Größe des Modells zurückzuführen ist.’
Obwohl die Projekt-Website mit Vergleichsvideos gesättigt ist (deren Layout es eher schwierig macht, die Fähigkeiten von HunyuanCustom mit denen früherer Konkurrenten zu vergleichen), muss festgestellt werden, dass sehr wenige Projekte im Video-Synthese-Bereich den Mut haben, sich in Tests gegen Kling zu stellen, den kommerziellen Video-Diffusions-API, der immer an oder nahe der Spitze der Ranglisten ist; Tencent scheint in diesem Bereich Fortschritte gegen diesen etablierten Spieler gemacht zu haben.
* Das Problem ist, dass einige der Videos so breit, kurz und hochauflösend sind, dass sie in Standard-Video-Playern wie VLC oder Windows Media Player nicht abgespielt werden können und schwarze Bildschirme anzeigen.
Erstveröffentlicht am Donnerstag, den 8. Mai 2025












