Künstliche Intelligenz
Direkte Präferenzoptimierung: Ein umfassender Leitfaden

Die Anpassung großer Sprachmodelle (LLMs) an menschliche Werte und Vorlieben ist eine Herausforderung. Traditionelle Methoden wie Reinforcement Learning aus menschlichem Feedback (RLHF) haben den Weg geebnet, indem sie menschliche Eingaben integrieren, um die Modellergebnisse zu verfeinern. RLHF kann jedoch komplex und ressourcenintensiv sein und erfordert erhebliche Rechenleistung und Datenverarbeitung. Direkte Präferenzoptimierung (DPO) erweist sich als neuartiger und optimierter Ansatz und bietet eine effiziente Alternative zu diesen traditionellen Methoden. Durch die Vereinfachung des Optimierungsprozesses reduziert DPO nicht nur den Rechenaufwand, sondern verbessert auch die Fähigkeit des Modells, sich schnell an menschliche Präferenzen anzupassen.
In diesem Leitfaden tauchen wir tief in das Thema DPO ein und untersuchen seine Grundlagen, Implementierung und praktischen Anwendungen.
Die Notwendigkeit einer Präferenzangleichung
Um DPO zu verstehen, ist es entscheidend zu verstehen, warum die Ausrichtung von LLMs an menschlichen Präferenzen so wichtig ist. Trotz ihrer beeindruckenden Fähigkeiten können LLMs, die mit riesigen Datensätzen trainiert wurden, manchmal Ergebnisse produzieren, die inkonsistent, verzerrt oder nicht mit menschlichen Werten übereinstimmen. Diese Fehlausrichtung kann sich auf verschiedene Weise manifestieren:
- Generieren von unsicheren oder schädlichen Inhalten
- Bereitstellung ungenauer oder irreführender Informationen
- Aufzeigen von Verzerrungen in den Trainingsdaten
Um diese Probleme anzugehen, haben Forscher Techniken entwickelt, um LLMs mithilfe menschlicher Rückmeldungen zu optimieren. Der bekannteste dieser Ansätze ist RLHF.
RLHF verstehen: Der Vorläufer von DPO
Reinforcement Learning from Human Feedback (RLHF) ist die bewährte Methode, um LLMs an menschliche Präferenzen anzupassen. Lassen Sie uns den RLHF-Prozess genauer betrachten, um seine Komplexität zu verstehen:
a) Überwachte Feinabstimmung (SFT): Der Prozess beginnt mit der Feinabstimmung eines vorab trainierten LLM anhand eines Datensatzes mit qualitativ hochwertigen Antworten. Dieser Schritt hilft dem Modell, relevantere und kohärentere Ergebnisse für die Zielaufgabe zu generieren.
b) Belohnungsmodellierung: Ein separates Belohnungsmodell wird trainiert, um menschliche Präferenzen vorherzusagen. Dies beinhaltet:
- Generieren von Antwortpaaren für vorgegebene Eingabeaufforderungen
- Menschen bewerten lassen, welche Antwort sie bevorzugen
- Trainieren eines Modells zur Vorhersage dieser Präferenzen
c) Verstärkung lernen: Das fein abgestimmte LLM wird dann mithilfe von Verstärkungslernen weiter optimiert. Das Belohnungsmodell liefert Feedback und leitet das LLM an, Antworten zu generieren, die den menschlichen Vorlieben entsprechen.
Hier ist ein vereinfachter Python-Pseudocode zur Veranschaulichung des RLHF-Prozesses:
Obwohl RLHF wirksam ist, weist es mehrere Nachteile auf:
- Es erfordert das Training und die Pflege mehrerer Modelle (SFT, Belohnungsmodell und RL-optimiertes Modell).
- Der RL-Prozess kann instabil und empfindlich gegenüber Hyperparametern sein
- Es ist rechenintensiv und erfordert viele Vorwärts- und Rückwärtsdurchläufe durch die Modelle
Diese Einschränkungen führten zur Suche nach einfacheren und effizienteren Alternativen und damit zur Entwicklung von DPO.
Direkte Präferenzoptimierung: Kernkonzepte

Direkte Präferenzoptimierung https://arxiv.org/abs/2305.18290
Diese Abbildung stellt zwei unterschiedliche Ansätze zur Anpassung von LLM-Ergebnissen an menschliche Präferenzen gegenüber: Reinforcement Learning from Human Feedback (RLHF) und Direct Preference Optimization (DPO). RLHF nutzt ein Belohnungsmodell, um die Strategie des Sprachmodells durch iterative Feedbackschleifen zu steuern, während DPO die Modellergebnisse anhand von Präferenzdaten direkt optimiert, um die vom Menschen bevorzugten Antworten abzugleichen. Dieser Vergleich hebt die Stärken und potenziellen Anwendungsmöglichkeiten der beiden Methoden hervor und gibt Aufschluss darüber, wie zukünftige LLMs trainiert werden könnten, um sie besser an menschliche Erwartungen anzupassen.
Schlüsselideen hinter DPO:
a) Implizite Belohnungsmodellierung: DPO macht ein separates Belohnungsmodell überflüssig, indem das Sprachmodell selbst als implizite Belohnungsfunktion behandelt wird.
b) Richtlinienbasierte Formulierung: Anstatt eine Belohnungsfunktion zu optimieren, optimiert DPO direkt die Richtlinie (Sprachmodell), um die Wahrscheinlichkeit bevorzugter Antworten zu maximieren.
c) Geschlossene Lösung: DPO nutzt mathematische Erkenntnisse, die eine geschlossene Lösung für die optimale Richtlinie ermöglichen und so die Notwendigkeit iterativer RL-Updates vermeiden.
DPO-Implementierung: Eine praktische Code-Anleitung
Das folgende Bild zeigt einen Codeausschnitt zur Implementierung der DPO-Verlustfunktion mit PyTorch. Diese Funktion spielt eine entscheidende Rolle bei der Verfeinerung der Priorisierung von Ausgaben durch Sprachmodelle basierend auf menschlichen Präferenzen. Hier ist eine Aufschlüsselung der wichtigsten Komponenten:
- Funktionssignatur: Der
dpo_lossFunktion berücksichtigt mehrere Parameter, einschließlich der Wahrscheinlichkeiten im Richtlinienprotokoll (pi_logps), Referenzmodell-Log-Wahrscheinlichkeiten (ref_logps) und Indizes, die bevorzugte und nicht bevorzugte Abschlüsse darstellen (yw_idxs,yl_idxs). ZusätzlichbetaDer Parameter steuert die Stärke der KL-Strafe. - Extraktion der Log-Wahrscheinlichkeit: Der Code extrahiert die Log-Wahrscheinlichkeiten für bevorzugte und nicht bevorzugte Abschlüsse sowohl aus dem Richtlinien- als auch aus dem Referenzmodell.
- Log-Ratio-Berechnung: Die Differenz zwischen den Log-Wahrscheinlichkeiten für bevorzugte und nicht bevorzugte Abschlüsse wird sowohl für das Richtlinien- als auch das Referenzmodell berechnet. Dieses Verhältnis ist entscheidend für die Bestimmung der Richtung und des Ausmaßes der Optimierung.
- Verlust- und Belohnungsberechnung: Der Verlust berechnet sich aus
logsigmoidFunktion, während die Belohnungen durch Skalierung der Differenz zwischen den Wahrscheinlichkeiten von Richtlinien- und Referenzprotokollen bestimmt werden.beta.

DPO-Verlustfunktion mit PyTorch
Lassen Sie uns in die Mathematik hinter DPO eintauchen, um zu verstehen, wie diese Ziele erreicht werden.
Die Mathematik des DPO
DPO ist eine clevere Neuformulierung des Präferenzlernproblems. Hier ist eine schrittweise Aufschlüsselung:
a) Ausgangspunkt: KL-beschränkte Belohnungsmaximierung
Das ursprüngliche RLHF-Ziel kann wie folgt ausgedrückt werden:
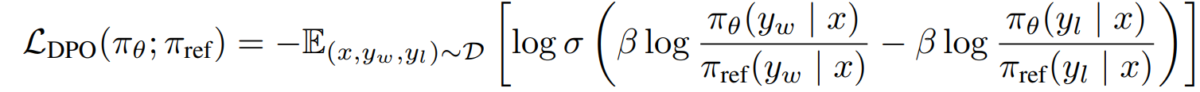
- πθ ist die Richtlinie (Sprachmodell), die wir optimieren
- r(x,y) ist die Belohnungsfunktion
- πref ist eine Referenzrichtlinie (normalerweise das ursprüngliche SFT-Modell)
- β steuert die Stärke der KL-Divergenzbeschränkung
b) Optimale Versicherungspolice: Es lässt sich zeigen, dass die optimale Strategie zur Erreichung dieses Ziels folgende Form hat:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Wobei Z(x) eine Normalisierungskonstante ist.
c) Dualität von Belohnungspolitik: Die wichtigste Erkenntnis von DPO besteht darin, die Belohnungsfunktion in Bezug auf die optimale Richtlinie auszudrücken:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Präferenzmodell Unter der Annahme, dass die Präferenzen dem Bradley-Terry-Modell folgen, können wir die Wahrscheinlichkeit, y1 gegenüber y2 zu bevorzugen, wie folgt ausdrücken:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Wobei σ die logistische Funktion ist.
e) DPO-Ziel Indem wir unsere Belohnungspolitik-Dualität in das Präferenzmodell einsetzen, gelangen wir zum DPO-Ziel:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Dieses Ziel kann mithilfe von Standardtechniken des Gradientenabstiegs optimiert werden, ohne dass RL-Algorithmen erforderlich sind.
Implementierung des DPO
Nachdem wir nun die Theorie hinter DPO verstanden haben, schauen wir uns an, wie es in der Praxis umgesetzt wird. Wir verwenden Python und PyTorch für dieses Beispiel:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Herausforderungen und zukünftige Richtungen
Obwohl DPO gegenüber herkömmlichen RLHF-Ansätzen erhebliche Vorteile bietet, gibt es noch immer Herausforderungen und Bereiche, in denen weitere Forschung erforderlich ist:
a) Skalierbarkeit auf größere Modelle:
Da Sprachmodelle immer größer werden, bleibt die effiziente Anwendung von DPO auf Modelle mit Hunderten von Milliarden Parametern eine ungelöste Herausforderung. Forscher erforschen Techniken wie:
- Effiziente Feinabstimmungsmethoden (z. B. LoRA, Präfix-Tuning)
- Verteilte Trainingsoptimierungen
- Gradienten-Checkpointing und Training mit gemischter Präzision
Beispiel für die Verwendung von LoRA mit DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Multi-Task- und Few-Shot-Adaption:
Die Entwicklung von DPO-Techniken, die sich effizient an neue Aufgaben oder Domänen mit begrenzten Präferenzdaten anpassen lassen, ist ein aktives Forschungsgebiet. Zu den untersuchten Ansätzen gehören:
- Meta-Learning-Frameworks für schnelle Anpassung
- Eingabeaufforderungsbasierte Feinabstimmung für DPO
- Transferlernen von allgemeinen Präferenzmodellen auf spezifische Domänen
c) Umgang mit mehrdeutigen oder widersprüchlichen Präferenzen:
Reale Präferenzdaten enthalten oft Unklarheiten oder Konflikte. Die Verbesserung der Robustheit von DPO gegenüber solchen Daten ist entscheidend. Mögliche Lösungen sind:
- Probabilistische Präferenzmodellierung
- Aktives Lernen zur Beseitigung von Unklarheiten
- Aggregation von Präferenzen mehrerer Agenten
Beispiel für probabilistische Präferenzmodellierung:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Kombination von DPO mit anderen Ausrichtungstechniken:
Die Integration von DPO in andere Ausrichtungsansätze könnte zu robusteren und leistungsfähigeren Systemen führen:
- Verfassungsmäßige KI-Prinzipien zur Erfüllung expliziter Zwänge
- Debatte und rekursive Belohnungsmodellierung zur Ermittlung komplexer Präferenzen
- Inverses Verstärkungslernen zur Ableitung zugrunde liegender Belohnungsfunktionen
Beispiel für die Kombination von DPO und verfassungsmäßiger KI:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Praktische Überlegungen und Best Practices
Beachten Sie bei der Implementierung von DPO für reale Anwendungen die folgenden Tipps:
a) Datenqualität: Die Qualität Ihrer Präferenzdaten ist entscheidend. Stellen Sie sicher, dass Ihr Datensatz:
- Deckt ein breites Spektrum an Eingaben und gewünschten Verhaltensweisen ab
- Verfügt über konsistente und zuverlässige Präferenzanmerkungen
- Gleicht unterschiedliche Präferenzen aus (z. B. Sachlichkeit, Sicherheit, Stil)
b) Hyperparameter-Tuning: Obwohl DPO weniger Hyperparameter als RLHF hat, ist die Feinabstimmung dennoch wichtig:
- β (Beta): Steuert den Kompromiss zwischen Präferenzerfüllung und Abweichung vom Referenzmodell. Beginnen Sie mit Werten um 0.1 bis 0.5.
- Lernrate: Verwenden Sie eine niedrigere Lernrate als die Standard-Feinabstimmung, typischerweise im Bereich von 1e-6 bis 1e-5.
- Batchgröße: Größere Batchgrößen (32 bis 128) eignen sich oft gut für das Lernen von Präferenzen.
c) Iterative Verfeinerung: DPO kann iterativ angewendet werden:
- Trainieren eines ersten Modells mit DPO
- Generieren Sie neue Antworten mithilfe des trainierten Modells
- Sammeln Sie neue Präferenzdaten zu diesen Antworten
- Erneutes Trainieren mithilfe des erweiterten Datensatzes

Leistung der direkten Präferenzoptimierung
Diese Abbildung zeigt die Leistung von LLMs wie GPT-4 im Vergleich zu menschlichen Urteilen bei verschiedenen Trainingstechniken, darunter Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT) und Proximal Policy Optimization (PPO). Die Tabelle zeigt, dass die Ergebnisse von GPT-4 zunehmend an menschlichen Präferenzen ausgerichtet sind, insbesondere bei Zusammenfassungsaufgaben. Der Grad der Übereinstimmung zwischen GPT-4 und menschlichen Prüfern zeigt die Fähigkeit des Modells, Inhalte zu generieren, die bei menschlichen Prüfern fast genauso gut ankommen wie von Menschen erstellte Inhalte.
Fallstudien und Anwendungen
Um die Wirksamkeit von DPO zu veranschaulichen, schauen wir uns einige reale Anwendungen und einige seiner Varianten an:
- Iterativer Datenschutzbeauftragter: Diese von Snorkel (2023) entwickelte Variante kombiniert Ablehnungsstichproben mit DPO und ermöglicht so einen verfeinerten Auswahlprozess für Trainingsdaten. Durch die Iteration über mehrere Runden der Präferenzstichproben kann das Modell besser verallgemeinern und eine Überanpassung an verrauschte oder verzerrte Präferenzen vermeiden.
- Börsengang (Iterative Präferenzoptimierung): IPO wurde von Azar et al. (2023) eingeführt und fügt einen Regularisierungsterm hinzu, um Überanpassung zu verhindern, was ein häufiges Problem bei der präferenzbasierten Optimierung ist. Diese Erweiterung ermöglicht es Modellen, ein Gleichgewicht zwischen der Einhaltung von Präferenzen und der Wahrung von Generalisierungsfähigkeiten aufrechtzuerhalten.
- KTO (Optimierung des Wissenstransfers): KTO, eine neuere Variante von Ethayarajh et al. (2023), verzichtet gänzlich auf binäre Präferenzen. Stattdessen konzentriert es sich auf die Übertragung von Wissen von einem Referenzmodell auf das Politikmodell und optimiert so eine reibungslosere und konsistentere Ausrichtung an menschlichen Werten.
- Multimodaler DPO für domänenübergreifendes Lernen von Xu et al. (2024): Ein Ansatz, bei dem DPO auf verschiedene Modalitäten (Text, Bild und Audio) angewendet wird und seine Vielseitigkeit bei der Anpassung von Modellen an menschliche Vorlieben über verschiedene Datentypen hinweg demonstriert. Diese Forschung unterstreicht das Potenzial von DPO bei der Erstellung umfassenderer KI-Systeme, die komplexe, multimodale Aufgaben bewältigen können.












