AI 101
Co je to rozhodovací strom?
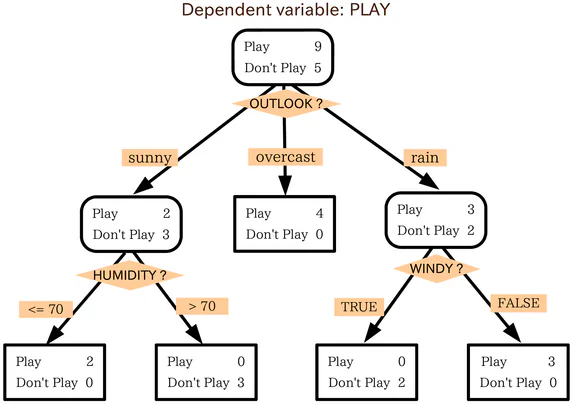
Co je to rozhodovací strom?
Rozhodovací strom je užitečný algoritmus strojového učení používaný pro regresní a klasifikační úkoly. Název „rozhodovací strom“ pochází z faktu, že algoritmus不断 rozděluje dataset na menší a menší části, až jsou data rozdělena na jednotlivé instance, které jsou poté klasifikovány. Pokud byste vizualizovali výsledky algoritmu, způsob, jakým jsou kategorie rozděleny, by připomínal strom a mnoho listů.
To je rychlé definice rozhodovacího stromu, ale pojďme se podívat hlouběji na to, jak rozhodovací stromy fungují. Lepší pochopení toho, jak rozhodovací stromy fungují, stejně jako jejich použití, vám pomůže vědět, kdy je použít ve vašich projektech strojového učení.
Formát rozhodovacího stromu
Rozhodovací strom je podobný flowchartu. Chcete-li použít flowchart, začnete na počátečním bodu, nebo kořenu, chartu a poté, na základě toho, jak odpovědíte na filtrovací kritéria počátečního uzlu, se přesunete do jednoho z dalších možných uzlů. Tento proces se opakuje, až je dosaženo konce.
Rozhodovací stromy fungují téměř stejným způsobem, s každým vnitřním uzlem ve stromu, který je nějakým druhem testu nebo filtrovacího kritéria. Uzly na vnější straně, koncové body stromu, jsou štítky pro datapoint v otázce a jsou nazývány „listy“. Větvě, které vedou z vnitřních uzlů k dalšímu uzlu, jsou funkce nebo konjunkce funkcí. Pravidla používaná pro klasifikaci datapointů jsou cesty, které vedou z kořenu k listům.

Algoritmy pro rozhodovací stromy
Rozhodovací stromy fungují na algoritmickém přístupu, který rozděluje dataset na jednotlivé datové body na základě různých kritérií. Tyto rozdělení jsou provedena s různými proměnnými, nebo různými funkcemi datasetu. Například, pokud je cílem určit, zda je popsán pes nebo kočka pomocí vstupních funkcí, proměnnými, na kterých je data rozdělena, by mohly být věci jako „drápy“ a „štěkání“.
Takže jaké algoritmy se používají k rozdělení dat do větví a listů? Existuje několik metod, které lze použít k rozdělení stromu, ale nejčastější metodou rozdělení je pravděpodobně technika nazývaná „rekurzivní binární rozdělení“. Při provádění této metody rozdělení se proces zahajuje v kořenu a počet funkcí v datasetu představuje možné počet možných rozdělení. Funkce se používá k určení, jak velkou přesnost každé možné rozdělení bude mít, a rozdělení se provede pomocí kritéria, které obětuje nejméně přesnost. Tento proces se opakuje rekurzivně a subskupiny se vytvářejí pomocí stejné obecné strategie.
Aby bylo možné určit náklady na rozdělení, použije se funkce nákladů. Jiná funkce nákladů se používá pro regresní úkoly a klasifikační úkoly. Cílem obou funkcí nákladů je určit, které větve mají nejpodobnější hodnoty odpovědí, nebo nejhomogennější větve. Předpokládejme, že chcete testovací data certain třídy, aby následovaly certain cesty, a toto má intuitivní smysl.
V případě regresní funkce nákladů pro rekurzivní binární rozdělení se používá následující algoritmus:
sum(y – prediction)^2
Predikce pro určitou skupinu datových bodů je průměr odpovědí trénovacích dat pro tuto skupinu. Všechny datové body se provedou funkcí nákladů, aby se určily náklady pro všechna možná rozdělení, a rozdělení s nejnižšími náklady se vybere.
Pokud jde o funkci nákladů pro klasifikaci, funkce je následující:
G = sum(pk * (1 – pk))
To je Gini skóre, a je to měření účinnosti rozdělení, založené na tom, kolik instancí různých tříd je ve skupinách, které vznikly z rozdělení. Jinými slovy, kvantifikuje, jak smíšené jsou skupiny po rozdělení. Optimální rozdělení je, když všechny skupiny, které vznikly z rozdělení, obsahují pouze vstupní data z jedné třídy. Pokud bylo vytvořeno optimální rozdělení, hodnota „pk“ bude buď 0 nebo 1 a G bude rovna 0. Můžete hádat, že nejhorší rozdělení je, když je 50-50 reprezentace tříd v rozdělení, v případě binární klasifikace. V tomto případě by hodnota „pk“ byla 0,5 a G by byla také 0,5.
Proces rozdělení se ukončí, když všechna data budou rozdělena na listy a klasifikována. Nicméně, můžete chtít zastavit růst stromu dříve. Velké komplexní stromy jsou náchylné k přeučení, ale několik různých metod lze použít k boji proti tomu. Jednou z metod, jak snížit přeučení, je specifikovat minimální počet datových bodů, které budou použity k vytvoření listu. Další metodou, jak kontrolovat přeučení, je omezit strom na určitou maximální hloubku, což kontroluje, jak dlouho může cesta vést z kořenu k listu.
Dalším procesem, který je zapojen do vytváření rozhodovacích stromů, je prořezávání. Prořezávání může pomoci zvýšit výkon rozhodovacího stromu tím, že odstraní větve, které obsahují funkce s malou predikční silou/malým významem pro model. Tímto způsobem se složitost stromu snižuje, je méně pravděpodobné, že dojde k přeučení, a predikční užitnost modelu se zvyšuje.
Při provádění prořezávání lze proces zahájit buď na vrcholu stromu, nebo na spodní části stromu. Nicméně, nejjednodušší metodou prořezávání je začít s listy a pokusit se odstranit uzel, který obsahuje nejčastější třídu v listu. Pokud se přesnost modelu nezhorší, když je provedena tato změna, pak se změna uchová. Existují další techniky, které se používají k prořezávání, ale metoda popsána výše – snížení chyby prořezávání – je pravděpodobně nejběžnější metodou prořezávání rozhodovacích stromů.
Požadavky pro použití rozhodovacích stromů
Rozhodovací stromy často užitečné když je třeba provést klasifikaci, ale výpočetní čas je významným omezením. Rozhodovací stromy mohou ukázat, které funkce v zvoleném datasetu mají největší predikční sílu. Kromě toho, na rozdíl od mnoha algoritmů strojového učení, kde pravidla používaná pro klasifikaci dat mohou být obtížně interpretovatelná, rozhodovací stromy mohou poskytovat interpretovatelná pravidla. Rozhodovací stromy jsou také schopny použít jak kategorické, tak kontinuální proměnné, což znamená, že je méně nutné předzpracování, ve srovnání s algoritmy, které mohou zpracovat pouze jeden typ proměnné.
Rozhodovací stromy se obvykle nedají použít k určení hodnot kontinuálních atributů. Další omezení rozhodovacích stromů je, že když se provádí klasifikace, pokud je málo trénovacích příkladů, ale mnoho tříd, rozhodovací strom se thường stává nepřesným.








