AI 101
Co je učení s posilováním?
Co je učení s posilováním?
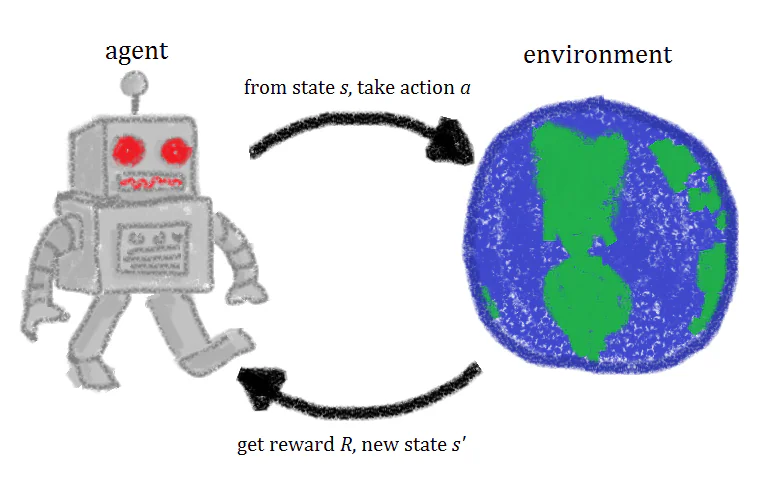
Jednoduše řečeno, učení s posilováním je technika strojového učení, která zahrnuje výuku umělých inteligencí prostřednictvím opakování akcí a spojených odměn. Agent učení s posilováním experimentuje v prostředí, provádí akce a je odměněn, když jsou provedeny správné akce. Časem se agent učí provádět akce, které maximalizují jeho odměnu. To je rychlé definice učení s posilováním, ale bližší pohled na koncepty za učením s posilováním vám pomůže získat lepší, intuitivnější pochopení.
Termín “učení s posilováním” je odvozen z konceptu posilování v psychologii. Z tohoto důvodu se podívejme na psychologický koncept posilování. V psychologickém smyslu se termín posilování vztahuje na něco, co zvyšuje pravděpodobnost, že určitá odpověď/akce nastane. Tento koncept posilování je centrální ideou teorie operantního kondicionování, kterou původně navrhl psycholog B.F. Skinner. V tomto kontextu je posilování cokoliv, co způsobí, že se frekvence určitého chování zvýší. Pokud přemýšlíme o možném posilování pro lidi, mohou to být věci jako chvála, zvýšení mzdy v práci, bonbony a zábavné činnosti.
V tradičním, psychologickém smyslu existují dva typy posilování. Existuje pozitivní posilování a negativní posilování. Pozitivní posilování je přidání něčeho, aby se zvýšila frekvence chování, jako je dání odměny psu, když se chová dobře. Negativní posilování zahrnuje odstranění stimulu, aby se vyvolala akce, jako je vypnutí hlasitých hluků, aby se vyvedl plašivé kočky.
Pozitivní a negativní posilování
Pozitivní posilování zvyšuje frekvenci chování, zatímco negativní posilování snižuje frekvenci. Obecně je pozitivní posilování nejčastěji používaným typem posilování v učení s posilováním, protože pomáhá modelům maximalizovat výkon při daném úkolu. Kromě toho vede pozitivní posilování model k provádění udržitelných změn, změn, které se mohou stát trvalými vzorci a přetrvávat po dlouhou dobu.
Naopak, zatímco negativní posilování také činí chování více pravděpodobným, používá se pro udržení minimálního standardu výkonu, spíše než dosažení maximálního výkonu modelu. Negativní posilování v učení s posilováním může pomoci zajistit, aby model byl držený pryč od nežádoucích akcí, ale nemůže opravdu donutit model k prozkoumání žádoucích akcí.
Školení agenta učení s posilováním
Když je agent učení s posilováním školen, existují čtyři různé ingredience nebo stavy použité ve školení: počáteční stavy (Stav 0), nový stav (Stav 1), akce a odměny.
Představte si, že školení agenta učení s posilováním, aby hrál platformovou videohru, kde cílem AI je dostat se na konec úrovně pohybem doprava přes obrazovku. Počáteční stav hry je vytažen z prostředí, což znamená, že první snímek hry je analyzován a dán modelu. Na základě této informace musí model rozhodnout o akci.
Během počátečních fází školení jsou tyto akce náhodné, ale jak je model posilován, stanou se některé akce více častými. Po provedení akce je prostředí hry aktualizováno a vytvořen je nový stav nebo snímek. Pokud akce provedená agentem vyprodukovala žádoucí výsledek, řekněme v tomto případě, že agent je stále naživu a nebyl zasažen nepřítelem, je agentovi udělena nějaká odměna a stává se více pravděpodobným, že bude provádět stejnou akci v budoucnu.
Tento základní systém je neustále opakován, opět a opět, a každý pokus se agent snaží naučit trochu více a maximalizovat svou odměnu.
Epizodické vs kontinuální úkoly
Úkoly učení s posilováním lze obvykle zařadit do jedné ze dvou různých kategorií: epizodické úkoly a kontinuální úkoly.
Epizodické úkoly provedou školení/smyčku a vylepší své výkony, dokud nejsou splněna某 kritéria a školení je ukončeno. Ve hře to může být dosažení konce úrovně nebo pád do pasti, jako jsou špičky. Naopak kontinuální úkoly nemají ukončovací kritéria, vlastně pokračují ve školení donekonečna, dokud inženýr zvolí ukončit školení.
Monte Carlo vs Temporal Difference
Existují dva hlavní způsoby, jak naučit, nebo školení, agenta učení s posilováním. V přístupu Monte Carlo jsou odměny doručeny agentovi (jeho skóre je aktualizováno) pouze na konci školení epizody. Jinými slovy, pouze když je ukončovací podmínka zasažena, model se naučí, jak dobře si vedl. Může pak použít tyto informace k aktualizaci a když je spuštěna další školení kola, bude reagovat v souladu s novými informacemi.
Temporální-difference metoda se liší od metody Monte Carlo v tom, že odhad hodnoty, nebo odhad skóre, je aktualizován během školení epizody. Jakmile model postupuje do dalšího časového kroku, jsou hodnoty aktualizovány.
Prozkoumání vs využívání
Školení agenta učení s posilováním je rovnovážný akt, který zahrnuje rovnováhu dvou různých metrik: prozkoumání a využívání.
Prozkoumání je akt sběru více informací o okolním prostředí, zatímco využívání je použití již známých informací o prostředí, aby se získaly odměny. Pokud agent pouze prozkoumá a nikdy nevyužije prostředí, žádoucí akce nikdy nebudou provedeny. Naopak, pokud agent pouze využije a nikdy neprozkoumá, agent se naučí provádět pouze jednu akci a nebude objevovat jiné možné strategie, jak získat odměny. Proto je vyvážení prozkoumání a využívání kritické, když se vytváří agent učení s posilováním.
Případy použití učení s posilováním
Učení s posilováním lze použít v široké škále rolí a je nejlépe vhodné pro aplikace, kde úkoly vyžadují automatizaci.
Automatizace úkolů, které mají být provedeny průmyslovými roboty, je jednou z oblastí, kde učení s posilováním prokazuje svou užitečnost. Učení s posilováním lze také použít pro problémy, jako je textové dolování, vytváření modelů, které jsou schopny shrnout dlouhé texty. Výzkumníci také experimentují s použitím učení s posilováním ve zdravotnictví, s agenty učení s posilováním, které zpracovávají úkoly, jako je optimalizace léčebných politik. Učení s posilováním lze také použít k přizpůsobení vzdělávacího materiálu studentům.
Shrnutí učení s posilováním
Učení s posilováním je mocným způsobem konstrukce umělých inteligencí, který může vést k působivým a někdy překvapivým výsledkům. Školení agenta prostřednictvím učení s posilováním může být komplexní a obtížné, protože vyžaduje mnoho školení iterací a jemnou rovnováhu prozkoumání/využívání. Nicméně, pokud je úspěšné, agent vytvořený s učením s posilováním může provádět komplexní úkoly v široké škále různých prostředí.








