
AI 101 г
Какво е линейна регресия?
Какво е линейна регресия?
Линейната регресия е алгоритъм, използван за прогнозиране или визуализиране на a връзка между две различни характеристики/променливи. В задачите за линейна регресия има два вида променливи, които се изследват: зависима променлива и независима променлива. Независимата променлива е променливата, която стои сама по себе си и не се влияе от другата променлива. Тъй като независимата променлива се коригира, нивата на зависимата променлива ще варират. Зависимата променлива е променливата, която се изследва, и това е, за което регресионният модел решава/се опитва да предскаже. В задачите за линейна регресия всяко наблюдение/пример се състои както от стойността на зависимата променлива, така и от стойността на независимата променлива.
Това беше кратко обяснение на линейната регресия, но нека се уверим, че достигаме до по-добро разбиране на линейната регресия, като разгледаме пример за нея и изследваме формулата, която използва.
Разбиране на линейната регресия
Да приемем, че имаме набор от данни, покриващ размерите на твърдите дискове и цената на тези твърди дискове.
Да предположим, че наборът от данни, който имаме, се състои от две различни характеристики: количество памет и цена. Колкото повече памет купуваме за компютър, толкова повече се увеличава цената на покупката. Ако начертаем отделните точки от данни върху точкова диаграма, може да получим графика, която изглежда по следния начин:

Точното съотношение памет/цена може да варира между производителите и моделите на твърдия диск, но като цяло тенденцията на данните е тази, която започва в долния ляв ъгъл (където твърдите дискове са едновременно по-евтини и имат по-малък капацитет) и се движи към горе вдясно (където дисковете са по-скъпи и имат по-голям капацитет).
Ако имахме количеството памет по оста X и разходите по оста Y, линия, улавяща връзката между променливите X и Y, ще започне в долния ляв ъгъл и ще продължи в горния десен ъгъл.
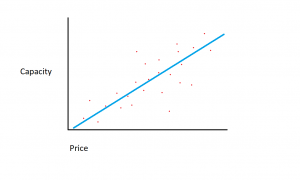
Функцията на регресионния модел е да определи линейна функция между променливите X и Y, която най-добре описва връзката между двете променливи. При линейната регресия се приема, че Y може да се изчисли от някаква комбинация от входните променливи. Връзката между входните променливи (X) и целевите променливи (Y) може да бъде представена чрез начертаване на линия през точките в графиката. Линията представлява функцията, която най-добре описва връзката между X и Y (например всеки път, когато X се увеличи с 3, Y се увеличи с 2). Целта е да се намери оптимална „регресионна линия“ или линията/функцията, която най-добре отговаря на данните.
Линиите обикновено се представят от уравнението: Y = m*X + b. X се отнася до зависимата променлива, докато Y е независимата променлива. Междувременно m е наклонът на линията, както е дефиниран от „възхода“ над „пробега“. Практиците в машинното обучение представят известното уравнение на наклонената линия малко по-различно, като вместо това използват това уравнение:
y(x) = w0 + w1 * x
В горното уравнение y е целевата променлива, докато “w” е параметрите на модела, а входът е “x”. Така че уравнението се чете като: „Функцията, която дава Y, в зависимост от X, е равна на параметрите на модела, умножени по характеристиките“. Параметрите на модела се коригират по време на обучение, за да се получи най-подходящата регресионна линия.
Множествена линейна регресия

Снимка: Cbaf чрез Wikimedia Commons, обществено достояние (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Процесът, описан по-горе, се прилага за проста линейна регресия или регресия върху набори от данни, където има само една характеристика/независима променлива. Въпреки това, регресия може да се направи и с множество функции. В случай че "множествена линейна регресия”, уравнението се разширява с броя на променливите, намерени в набора от данни. С други думи, докато уравнението за редовна линейна регресия е y(x) = w0 + w1 * x, уравнението за множествена линейна регресия ще бъде y(x) = w0 + w1x1 плюс теглата и входните данни за различните характеристики. Ако представим общия брой тегла и характеристики като w(n)x(n), тогава можем да представим формулата така:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
След установяване на формулата за линейна регресия, моделът за машинно обучение ще използва различни стойности за теглата, като чертае различни линии на напасване. Не забравяйте, че целта е да се намери линията, която най-добре отговаря на данните, за да се определи коя от възможните комбинации на тегло (и следователно коя възможна линия) отговаря най-добре на данните и обяснява връзката между променливите.
Функция на разходите се използва за измерване на това колко близки са предполагаемите стойности на Y до действителните стойности на Y, когато им е дадена конкретна стойност на теглото. Функцията на разходите за линейна регресия е средната квадратна грешка, която просто взема средната (квадратна) грешка между прогнозираната стойност и истинската стойност за всички различни точки от данни в набора от данни. Функцията на разходите се използва за изчисляване на разходи, които улавят разликата между прогнозираната целева стойност и истинската целева стойност. Ако линията на напасване е далеч от точките с данни, цената ще бъде по-висока, докато цената ще става по-малка, колкото повече линията се доближава до улавяне на истинските връзки между променливите. След това теглата на модела се коригират, докато се намери конфигурацията на теглото, която създава най-малката грешка.










