
AI 101 г
Какво е дърво на решенията?
Какво е дърво на решенията?
A дърво за решение е полезен алгоритъм за машинно обучение, използван както за задачи за регресия, така и за класификация. Името „дърво на решенията“ идва от факта, че алгоритъмът продължава да разделя набора от данни на по-малки и по-малки части, докато данните бъдат разделени на отделни екземпляри, които след това се класифицират. Ако визуализирате резултатите от алгоритъма, начинът, по който са разделени категориите, би наподобявал дърво и много листа.
Това е бърза дефиниция на дървото на решенията, но нека се потопим дълбоко в това как работят дърветата на решенията. По-доброто разбиране на това как работят дърветата на решенията, както и техните случаи на употреба, ще ви помогне да разберете кога да ги използвате по време на вашите проекти за машинно обучение.
Формат на дърво на решенията
Дървото на решенията е много прилича на блок-схема. За да използвате блок-схема, започвате от началната точка или корена на диаграмата и след това въз основа на начина, по който отговаряте на критериите за филтриране на този начален възел, преминавате към един от следващите възможни възли. Този процес се повтаря, докато се достигне край.
Дърветата на решенията работят по същество по същия начин, като всеки вътрешен възел в дървото е някакъв вид тест/критерий за филтриране. Възлите от външната страна, крайните точки на дървото, са етикетите за въпросната точка от данни и се наричат „листа“. Разклоненията, които водят от вътрешните възли до следващия възел, са характеристики или връзки на характеристики. Правилата, използвани за класифициране на точките от данни, са пътищата, които вървят от корена към листата.
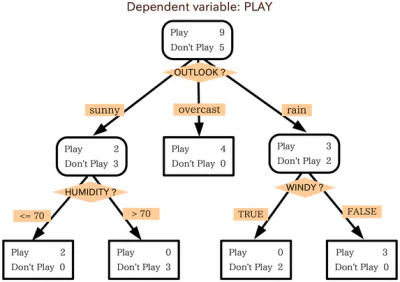
Алгоритми за дървета на решения
Дърветата на решенията работят на базата на алгоритмичен подход, който разделя набора от данни на отделни точки от данни въз основа на различни критерии. Тези разделяния се извършват с различни променливи или различните характеристики на набора от данни. Например, ако целта е да се определи дали куче или котка се описват от входните характеристики, променливите, върху които се разделят данните, може да са неща като „нокти“ и „лаещи“.
И така, какви алгоритми се използват за действително разделяне на данните на клонове и листа? Има различни методи, които могат да се използват за разделяне на дърво, но най-често срещаният метод за разделяне вероятно е техника, наричана „рекурсивно двоично разделяне”. Когато се извършва този метод на разделяне, процесът започва от корена и броят на характеристиките в набора от данни представлява възможния брой възможни разделяния. Използва се функция, за да се определи колко точност ще струва всяко възможно разделяне и разделянето се прави с помощта на критериите, които жертват най-малката точност. Този процес се извършва рекурсивно и подгрупите се формират, като се използва същата обща стратегия.
С цел да се определи цената на разделянето, използва се функция на разходите. За задачи за регресия и задачи за класификация се използва различна функция на разходите. Целта на двете функции на разходите е да се определи кои клонове имат най-сходни стойности на отговор или най-хомогенни клонове. Помислете, че искате тестови данни от определен клас да следват определени пътища и това има интуитивен смисъл.
По отношение на регресионната функция на разходите за рекурсивно двоично разделяне, алгоритъмът, използван за изчисляване на разходите, е както следва:
sum(y – прогноза)^2
Прогнозата за определена група точки от данни е средната стойност на отговорите на данните за обучение за тази група. Всички точки от данни преминават през функцията за разходи, за да се определи цената за всички възможни разделяния и се избира разделянето с най-ниска цена.
По отношение на функцията на разходите за класификация, функцията е следната:
G = сума (pk * (1 – pk))
Това е резултатът на Джини и е измерване на ефективността на разделянето, базирано на това колко екземпляра от различни класове има в групите, произтичащи от разделянето. С други думи, той определя количествено колко смесени са групите след разделянето. Оптимално разделяне е, когато всички групи, произтичащи от разделянето, се състоят само от входове от един клас. Ако е създадено оптимално разделяне, стойността „pk“ ще бъде 0 или 1 и G ще бъде равно на нула. Може да се досетите, че най-лошият случай на разделяне е този, при който има 50-50 представяне на класовете в разделянето, в случай на двоична класификация. В този случай стойността „pk“ ще бъде 0.5 и G също ще бъде 0.5.
Процесът на разделяне се прекратява, когато всички точки от данни са превърнати в листа и класифицирани. Въпреки това, може да искате да спрете растежа на дървото рано. Големите сложни дървета са склонни към прекомерно оборудване, но могат да се използват няколко различни метода за борба с това. Един метод за намаляване на пренастройването е да се посочи минимален брой точки от данни, които ще се използват за създаване на лист. Друг метод за контролиране на пренастройването е ограничаването на дървото до определена максимална дълбочина, която контролира колко дълго може да се простира пътят от корена до листа.
Друг процес, включен в създаването на дървета на решения е резитба. Подрязването може да помогне за увеличаване на производителността на дървото на решенията чрез отстраняване на клонове, съдържащи функции, които имат малка предсказуема сила/малко значение за модела. По този начин сложността на дървото се намалява, става по-малко вероятно да се пренастрои и прогнозната полезност на модела се увеличава.
Когато се извършва резитба, процесът може да започне или от върха на дървото, или от дъното на дървото. Въпреки това, най-лесният метод за подрязване е да започнете с листата и да се опитате да премахнете възела, който съдържа най-често срещания клас в този лист. Ако точността на модела не се влоши, когато това се направи, тогава промяната се запазва. Има и други техники, използвани за извършване на съкращаване, но описаният по-горе метод – съкращаване с намалена грешка – вероятно е най-разпространеният метод за съкращаване на дървото на решенията.
Съображения за използване на дървета за вземане на решения
Решението дървета често са полезни когато трябва да се извърши класификация, но времето за изчисление е основно ограничение. Дърветата на решенията могат да изяснят кои функции в избраните набори от данни имат най-голяма предсказуема сила. Освен това, за разлика от много алгоритми за машинно обучение, където правилата, използвани за класифициране на данните, може да са трудни за тълкуване, дърветата на решенията могат да изобразяват интерпретируеми правила. Дърветата на решенията също така могат да използват както категорични, така и непрекъснати променливи, което означава, че е необходима по-малко предварителна обработка в сравнение с алгоритмите, които могат да обработват само един от тези типове променливи.
Дърветата на решенията обикновено не се представят много добре, когато се използват за определяне на стойностите на непрекъснати атрибути. Друго ограничение на дърветата на решенията е, че когато се прави класификация, ако има малко примери за обучение, но много класове, дървото на решенията обикновено е неточно.










