
AI 101 г
Какво е матрица на объркване?
Един от най-мощните аналитични инструменти в машинното обучение и науката за данни в матрицата на объркването. Матрицата на объркването е в състояние да даде на изследователите подробна информация за това как се е представил класификаторът за машинно обучение по отношение на целевите класове в набора от данни. Матрицата на объркването ще демонстрира примери за показване, които са правилно класифицирани срещу неправилно класифицирани примери. Нека да разгледаме по-задълбочено как е структурирана матрицата на объркването и как може да бъде интерпретирана.
Какво е матрица на объркването?
Нека започнем, като дадем проста дефиниция на матрица на объркване. Матрицата на объркването е инструмент за прогнозен анализ. По-конкретно, това е таблица, която показва и сравнява действителните стойности с прогнозираните стойности на модела. В контекста на машинното обучение матрицата на объркването се използва като метрика за анализиране на това как класификаторът за машинно обучение работи върху набор от данни. Матрицата на объркването генерира визуализация на показатели като прецизност, точност, специфичност и припомняне.
Причината, поради която матрицата на объркване е особено полезна, е, че за разлика от други типове показатели за класификация, като например проста точност, матрицата на объркване генерира по-пълна картина за това как се представя даден модел. Само използването на метрика като точност може да доведе до ситуация, в която моделът напълно и последователно погрешно идентифицира един клас, но това остава незабелязано, тъй като средното представяне е добро. Междувременно матрицата на объркването дава сравнение на различни стойности като фалшиви отрицания, истински отрицателни резултати, фалшиви положителни резултати и истински положителни резултати.
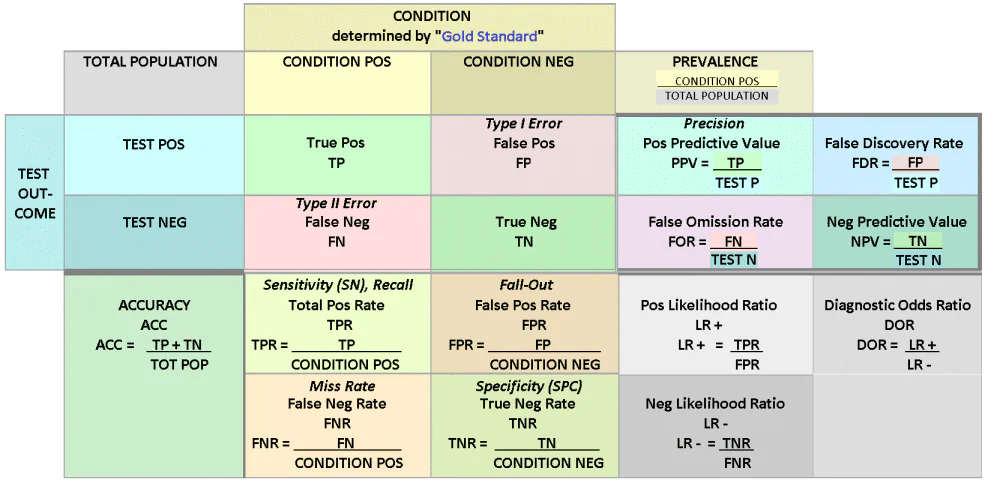
Нека дефинираме различните показатели, които представлява матрицата на объркване.
Спомнете си в матрицата на объркването
Припомнянето е броят на истински положителни примери, разделен на броя на фалшиво-отрицателните примери и общия брой положителни примери. С други думи, припомнянето е представително за дела на истинските положителни примери, които моделът на машинно обучение е класифицирал. Припомнянето е дадено като процент положителни примери, които моделът успя да класифицира от всички положителни примери, съдържащи се в набора от данни. Тази стойност може също да се нарича „честота на попадение“, а свързаната стойност е „чувствителност“, който описва вероятността от припомняне или степента на истински положителни прогнози.
Прецизност в Матрицата на объркването
Подобно на припомнянето, прецизността е стойност, която проследява представянето на модела по отношение на класификацията на положителен пример. За разлика от припомнянето обаче, прецизността се отнася до това колко от примерите, обозначени от модела като положителни, са наистина положителни. За да се изчисли това, броят на истинските положителни примери се разделя на броя на фалшиво-положителните примери плюс истинските положителни.
За да се направи разлика между извикване и прецизност по-ясно, прецизността има за цел да разбере процента на всички примери, обозначени като положителни, които са наистина положителни, докато припомнянето проследява процента на всички истински положителни примери, които моделът може да разпознае.
специфичност в Матрицата на объркването
Докато припомнянето и прецизността са стойности, които проследяват положителните примери и истинския положителен процент, специфичност определя количествено истинския отрицателен процент или броя на примерите, дефинирани от модела като отрицателни, които са наистина отрицателни. Това се изчислява, като се вземе броят на примерите, класифицирани като отрицателни, и се раздели на броя на фалшиво положителните примери, комбинирани с истинските отрицателни примери.
Осмисляне на матрицата на объркването

Снимка: Jackverr чрез Wikimedia Commons, (https://commons.wikimedia.org/wiki/File:ConfusionMatrix.png), CC BY SA 3.0
Пример за матрица на объркване
След като дефинираме необходимите термини като прецизност, припомняне, чувствителност и специфичност, можем да проучим как тези различни стойности са представени в рамките на матрица на объркване. Генерира се матрица на объркване в случаи на класификация, приложима, когато има два или повече класа. Генерираната матрица на объркване може да бъде толкова висока и широка, колкото е необходимо, като съдържа произволен брой класове, но за целите на простотата ще разгледаме матрица на объркване 2 x 2 за задача за двоична класификация.
Като пример, приемете, че се използва класификатор, за да се определи дали даден пациент има заболяване или не. Характеристиките ще бъдат въведени в класификатора, а класификаторът ще върне една от двете различни класификации – или пациентът няма заболяването, или има.
Нека започнем с лявата страна на матрицата. Лявата страна на матрицата на объркването представлява прогнозите, които класификаторът е направил за отделните класове. Задачата за двоична класификация ще има два реда тук. По отношение на горната част на матрицата, тя проследява истинските стойности, действителните етикети на класове, на екземплярите на данни.
Тълкуването на матрица на объркване може да се направи чрез изследване къде се пресичат редовете и колоните. Проверете прогнозите на модела спрямо истинските етикети на модела. В този случай стойностите True Positives, броят на правилните положителни прогнози, се намират в горния ляв ъгъл. Фалшивите положителни резултати се намират в горния десен ъгъл, където примерите всъщност са отрицателни, но класификаторът ги маркира като положителни.
Долният ляв ъгъл на мрежата показва случаи, които класификаторът е маркирал като отрицателни, но са били наистина положителни. И накрая, долният десен ъгъл на матрицата за объркване е мястото, където се намират истинските отрицателни стойности или където са истинските неверни примери.
Когато наборът от данни съдържа повече от два класа, матрицата нараства с толкова класове. Например, ако има три класа, матрицата ще бъде матрица 3 x 3. Независимо от размера на матрицата на объркването, методът за тяхното тълкуване е абсолютно същият. Лявата страна съдържа прогнозираните стойности и действителните етикети на класа, разположени отгоре. Случаите, които класификаторът е предвидил правилно, се движат диагонално от горния ляв до долния десен ъгъл. Като погледнете матрицата, можете да различите четирите прогнозни показателя, обсъдени по-горе.
Например, можете да изчислите припомнянето, като вземете истинските положителни и фалшивите отрицателни резултати, съберете ги заедно и ги разделите на броя на истинските положителни примери. Междувременно прецизността може да се изчисли чрез комбиниране на фалшивите положителни резултати с истинските положителни резултати, след което стойността се раздели на общия брой истински положителни резултати.
Докато човек може да отдели време за ръчно изчисляване на показатели като прецизност, запомняне и специфичност, тези показатели са толкова често използвани, че повечето библиотеки за машинно обучение имат методи за показването им. Например Scikit-learn за Python има функция, генерираща матрица за объркване.










