
AI 101 г
Какво е намаляване на размерността?
Какво е намаляване на размерността?
Намаляване на размерността е процес, използван за намаляване на размерността на набор от данни, като се вземат много функции и се представят като по-малко характеристики. Например намаляването на размерността може да се използва за намаляване на набор от данни от двадесет характеристики до само няколко характеристики. Намаляването на размерите обикновено се използва в учене без надзор задачи за автоматично създаване на класове от много функции. За да разберете по-добре защо и как се използва намаляването на размерността, ще разгледаме проблемите, свързани с данните с висока размерност и най-популярните методи за намаляване на размерността.
Повече размери водят до прекомерно оборудване
Размерността се отнася до броя характеристики/колони в набор от данни.
Често се приема, че при машинното обучение повече функции са по-добри, тъй като създава по-точен модел. Въпреки това, повече функции не означават непременно по-добър модел.
Характеристиките на даден набор от данни могат да варират значително по отношение на това колко са полезни за модела, като много характеристики са от малко значение. Освен това, колкото повече функции съдържа наборът от данни, толкова повече проби са необходими, за да се гарантира, че различните комбинации от характеристики са добре представени в данните. Следователно броят на пробите се увеличава пропорционално на броя на характеристиките. Повече мостри и повече функции означават, че моделът трябва да бъде по-сложен и тъй като моделите стават по-сложни, те стават по-чувствителни към пренастройване. Моделът научава моделите в данните за обучението твърде добре и не успява да обобщи до извадкови данни.
Намаляването на размерността на набор от данни има няколко предимства. Както споменахме, по-простите модели са по-малко склонни към пренастройване, тъй като моделът трябва да прави по-малко предположения относно това как функциите са свързани една с друга. В допълнение, по-малкото измерения означават, че е необходима по-малко изчислителна мощност за обучение на алгоритмите. По същия начин е необходимо по-малко място за съхранение за набор от данни, който има по-малка размерност. Намаляването на размерността на набор от данни може също да ви позволи да използвате алгоритми, които не са подходящи за набори от данни с много функции.
Общи методи за намаляване на размерността
Намаляването на размерността може да бъде чрез избор на характеристики или инженеринг на характеристики. Изборът на характеристики е мястото, където инженерът идентифицира най-подходящите характеристики на набора от данни, докато инженеринг на функции е процес на създаване на нови характеристики чрез комбиниране или трансформиране на други характеристики.
Изборът на функции и инженерингът могат да се извършват програмно или ръчно. Когато ръчно избирате и проектирате функции, визуализирането на данните за откриване на корелации между функции и класове е типично. Извършването на намаляване на размерността по този начин може да отнеме доста време и следователно някои от най-често срещаните начини за намаляване на размерността включват използването на налични алгоритми в библиотеки като Scikit-learn за Python. Тези общи алгоритми за намаляване на размерността включват: Анализ на основните компоненти (PCA), Декомпозиция на сингулярна стойност (SVD) и Линеен дискриминантен анализ (LDA).
Алгоритмите, използвани за намаляване на размерността за задачи за неконтролирано обучение, обикновено са PCA и SVD, докато тези, използвани за намаляване на размерността на контролирано обучение, обикновено са LDA и PCA. В случай на модели за контролирано обучение, новогенерираните функции просто се подават в класификатора за машинно обучение. Обърнете внимание, че описаните тук употреби са само общи случаи на употреба, а не единствените условия, при които могат да се използват тези техники. Алгоритмите за намаляване на размерността, описани по-горе, са просто статистически методи и се използват извън моделите за машинно обучение.
Анализ на главния компонент

Снимка: Матрица с идентифицирани основни компоненти
Анализ на основни компоненти (PCA) е статистически метод, който анализира характеристиките/характеристиките на набор от данни и обобщава характеристиките, които са най-влиятелни. Характеристиките на набора от данни се комбинират заедно в представяния, които поддържат повечето от характеристиките на данните, но са разпръснати в по-малко измерения. Можете да мислите за това като за „смачкане“ на данните от представяне с по-високо измерение до такова само с няколко измерения.
Като пример за ситуация, в която PCA може да бъде полезна, помислете за различните начини, по които човек може да опише виното. Въпреки че е възможно да се опише вино, като се използват много специфични характеристики като нива на CO2, нива на аерация и т.н., такива специфични характеристики може да са относително безполезни, когато се опитвате да идентифицирате конкретен тип вино. Вместо това би било по-разумно да се идентифицира типът въз основа на по-общи характеристики като вкус, цвят и възраст. PCA може да се използва за комбиниране на по-специфични функции и създаване на функции, които са по-общи, полезни и е по-малко вероятно да причинят прекомерно оборудване.
PCA се извършва чрез определяне на това как входните характеристики варират от средната стойност една спрямо друга, като се определя дали съществуват някакви връзки между характеристиките. За да се направи това, се създава ковариантна матрица, която установява матрица, съставена от ковариациите по отношение на възможните двойки характеристики на набора от данни. Това се използва за определяне на корелациите между променливите, като отрицателната ковариация показва обратна корелация, а положителната корелация показва положителна корелация.
Основните (най-влиятелните) компоненти на набора от данни се създават чрез създаване на линейни комбинации от първоначалните променливи, което се прави с помощта на концепции за линейна алгебра, наречени собствени стойности и собствени вектори. Комбинациите са създадени така, че основните компоненти да не са свързани помежду си. По-голямата част от информацията, съдържаща се в първоначалните променливи, е компресирана в първите няколко основни компонента, което означава, че са създадени нови функции (основните компоненти), които съдържат информацията от оригиналния набор от данни в по-малко пространствено пространство.
Разлагане на единичната стойност
Снимка: от Cmglee – собствена работа, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
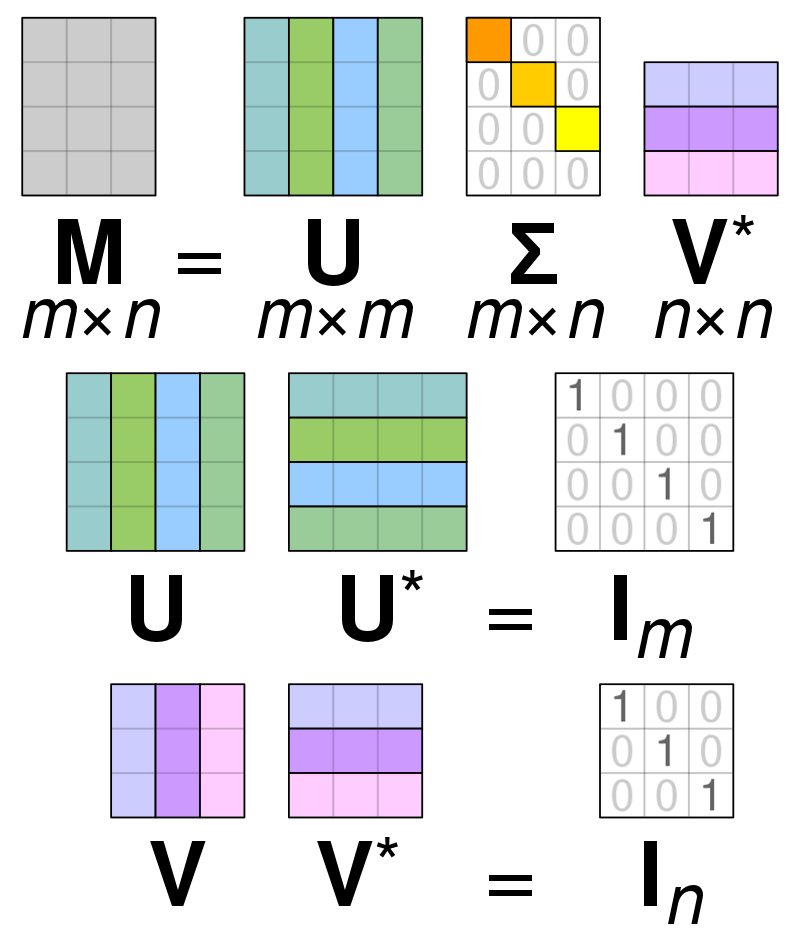
Разлагане на единична стойност (SVD) is използвани за опростяване на стойностите в рамките на матрица, намалявайки матрицата до нейните съставни части и правейки изчисленията с тази матрица по-лесни. SVD може да се използва както за матрици с реална стойност, така и за сложни матрици, но за целите на това обяснение ще разгледаме как да разложим матрица с реални стойности.
Да приемем, че имаме матрица, съставена от данни с реална стойност и нашата цел е да намалим броя на колоните/характеристиките в матрицата, подобно на целта на PCA. Подобно на PCA, SVD ще компресира размерността на матрицата, като същевременно запазва възможно най-голяма част от променливостта на матрицата. Ако искаме да работим с матрица A, можем да представим матрица A като три други матрици, наречени U, D и V. Матрица A се състои от оригиналните x * y елементи, докато матрицата U се състои от елементи X * X (тя е ортогонална матрица). Матрица V е различна ортогонална матрица, съдържаща y * y елемента. Матрицата D съдържа елементите x * y и е диагонална матрица.
За да разложим стойностите за матрица A, трябва да преобразуваме стойностите на оригиналната сингулярна матрица в диагоналните стойности, открити в рамките на нова матрица. При работа с ортогонални матрици техните свойства не се променят, ако се умножат по други числа. Следователно можем да апроксимираме матрица А, като се възползваме от това свойство. Когато умножим ортогоналните матрици заедно с транспониране на матрица V, резултатът е еквивалентна матрица на нашата оригинална A.
Когато матрица a се разлага на матрици U, D и V, те съдържат данните, намиращи се в матрица A. Най-левите колони на матриците обаче ще съдържат по-голямата част от данните. Можем да вземем само тези първи няколко колони и да имаме представяне на Матрица A, която има много по-малко измерения и повечето от данните в A.
Линеен дискриминантен анализ

Вляво: Матрица преди LDA, Вдясно: Оста след LDA, вече разделима
Линеен дискриминантен анализ (LDA) е процес, който взема данни от многомерна графика и препроектира го върху линейна графика. Можете да си представите това, като си представите двуизмерна графика, пълна с точки от данни, принадлежащи към два различни класа. Да приемем, че точките са разпръснати наоколо, така че да не може да се начертае линия, която да разделя добре двата различни класа. За да се справим с тази ситуация, точките, намерени в 2D графиката, могат да бъдат намалени до 1D графика (линия). Тази линия ще има всички точки от данни, разпределени по нея и се надяваме, че може да бъде разделена на две секции, които представляват възможно най-доброто разделяне на данните.
При провеждането на LDA има две основни цели. Първата цел е минимизиране на дисперсията за класовете, докато втората цел е максимизиране на разстоянието между средните стойности на двата класа. Тези цели се постигат чрез създаване на нова ос, която ще съществува в 2D графиката. Новосъздадената ос действа за разделяне на двата класа въз основа на описаните по-рано цели. След като оста е създадена, точките, намерени в 2D графиката, се поставят по протежение на оста.
Има три стъпки, необходими за преместване на оригиналните точки на нова позиция по новата ос. В първата стъпка разстоянието между средните стойности на отделните класове (вариацията между класовете) се използва за изчисляване на разделимостта на класовете. Във втората стъпка се изчислява дисперсията в рамките на различните класове, като се определя разстоянието между извадката и средната стойност за въпросния клас. В последната стъпка се създава пространство с по-ниско измерение, което максимизира вариацията между класовете.
Техниката LDA постига най-добри резултати, когато средствата за целевите класове са далеч едно от друго. LDA не може ефективно да раздели класовете с линейна ос, ако средствата за разпределенията се припокриват.










