
AI 101 г
Какво е генерираща състезателна мрежа (GAN)?
Генеративни състезателни мрежи (GAN) са типове архитектури на невронни мрежи способни да генерират нови данни който отговаря на научените модели. GAN могат да се използват за генериране на изображения на човешки лица или други обекти, за извършване на превод от текст към изображение, за преобразуване на един тип изображение в друг и за подобряване на разделителната способност на изображенията (супер разделителна способност) сред други приложения. Тъй като GAN могат да генерират изцяло нови данни, те са начело на много авангардни AI системи, приложения и изследвания. Но как точно работят GAN? Нека проучим как функционират GAN и да разгледаме някои от основните им приложения.
Дефиниране на генеративни модели и GAN
GAN е пример за генеративен модел. Повечето AI модели могат да бъдат разделени в една от двете категории: контролирани и неконтролирани модели. Моделите на контролирано обучение обикновено се използват за разграничаване на различни категории входящи данни, за класифициране. За разлика от това, неконтролираните модели обикновено се използват за обобщаване на разпространението на данни, често обучение гаусово разпределение на данните. Тъй като те научават разпределението на набор от данни, те могат да изтеглят проби от това научено разпределение и да генерират нови данни.
Различните генеративни модели имат различни методи за генериране на данни и изчисляване на вероятностните разпределения. Например, на Наивен модел на Бейс работи чрез изчисляване на вероятностно разпределение за различните входни характеристики и генеративния клас. Когато моделът на Naive Bayes прави прогноза, той изчислява най-вероятния клас, като взема вероятността на различните променливи и ги комбинира заедно. Други генеративни модели без задълбочено обучение включват смесени модели на Гаус и латентно разпределение на Дирихле (LDA). Генеративни модели, базирани на дълбок наклон include Ограничени машини на Болцман (RBM), Вариационни автоенкодери (VAE), и разбира се, GAN.
Generative Adversarial Networks бяха за първи път предложен от Иън Гудфелоу през 2014 г, и те бяха подобрени от Алек Редфорд и други изследователи през 2015 г., което доведе до стандартизирана архитектура за GAN. GAN всъщност са две различни мрежи, обединени заедно. GAN са съставен от две половини: модел на генериране и модел на дискриминация, наричан още генератор и дискриминатор.
Архитектурата на GAN
Генеративните състезателни мрежи са изграден от модел на генератор и модел на дискриминатор, взети заедно. Задачата на модела на генератора е да създава нови примери за данни въз основа на моделите, които моделът е научил от данните за обучение. Задачата на модела на дискриминатора е да анализира изображения (ако приемем, че е обучен върху изображения) и да определи дали изображенията са генерирани/фалшиви или оригинални.

Двата модела са изправени един срещу друг, обучени по теоретичен начин на игрите. Целта на генераторния модел е да произвежда изображения, които заблуждават своя противник – дискриминиращия модел. Междувременно работата на модела на дискриминатора е да преодолее своя противник, модела на генератора, и да улови фалшивите изображения, които генераторът произвежда. Фактът, че моделите са изправени един срещу друг, води до надпревара във въоръжаването, при която и двата модела се подобряват. Дискриминаторът получава обратна връзка за това кои изображения са били оригинални и кои изображения са произведени от генератора, докато генераторът получава информация кои от неговите изображения са били маркирани като неверни от дискриминатора. И двата модела се подобряват по време на обучението, с цел обучение на модел за генериране, който може да генерира фалшиви данни, които по принцип са неразличими от истинските, истински данни.
След като по време на обучението е създадено гаусово разпределение на данни, може да се използва генеративният модел. Моделът на генератора първоначално се захранва с произволен вектор, който той трансформира въз основа на разпределението на Гаус. С други думи, векторът заражда поколението. Когато моделът бъде обучен, векторното пространство ще бъде компресирана версия или представяне на разпределението на Гаус на данните. Компресираната версия на разпространението на данни се нарича латентно пространство или латентни променливи. По-късно моделът GAN може да вземе представянето на латентното пространство и да извлече точки от него, които могат да бъдат дадени на модела на генериране и използвани за генериране на нови данни, които са много подобни на данните за обучение.
Моделът на дискриминатора се захранва с примери от цялата област на обучение, която е съставена както от реални, така и от генерирани примери с данни. Истинските примери се съдържат в набора от данни за обучение, докато фалшивите данни се произвеждат от генеративния модел. Процесът на обучение на модела на дискриминатора е абсолютно същият като основното обучение на модел на двоична класификация.
GAN процес на обучение
Нека да разгледаме цялото обучение процес за задача за генериране на хипотетично изображение.
Като начало GAN се обучава с помощта на истински, реални изображения като част от набора от данни за обучение. Това настройва модела на дискриминатора, за да прави разлика между генерирани изображения и реални изображения. Той също така произвежда разпределението на данни, което генераторът ще използва за създаване на нови данни.
Генераторът приема вектор от произволни числови данни и ги трансформира въз основа на разпределението на Гаус, връщайки изображение. Тези генерирани изображения, заедно с някои оригинални изображения от обучителния набор от данни, се въвеждат в модела на дискриминатора. Дискриминаторът ще направи вероятностна прогноза за естеството на изображенията, които получава, извеждайки стойност между 0 и 1, където 1 обикновено е автентично изображение, а 0 е фалшиво изображение.
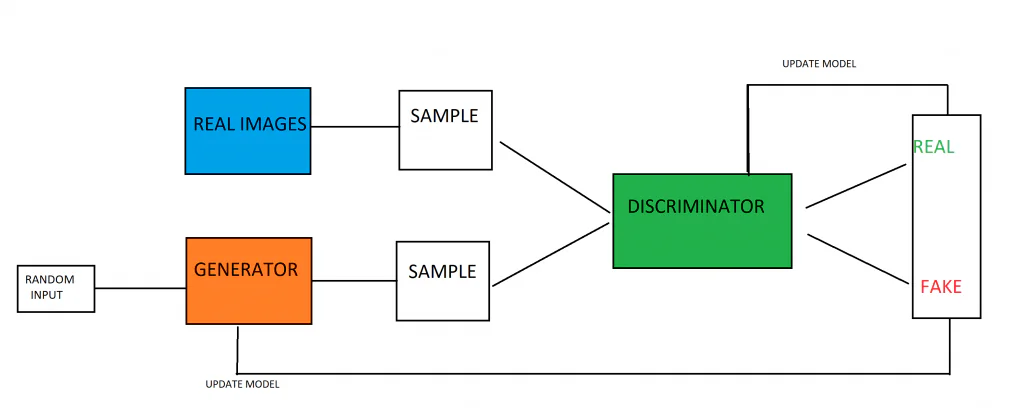
Има двойна верига за обратна връзка, тъй като на земния дискриминатор се подава основната истина на изображенията, докато на генератора се дава обратна връзка за неговата работа от дискриминатора.
Генеративният и дискриминационният модел играят игра с нулева сума един с друг. Игра с нулева сума е тази, при която печалбите на едната страна идват за сметка на другата страна (сумата е, че и двете действия е нула ex). Когато моделът на дискриминатора е в състояние успешно да прави разлика между истински и фалшиви примери, не се правят промени в параметрите на дискриминатора. Въпреки това се правят големи актуализации на параметрите на модела, когато той не успява да направи разлика между истински и фалшиви изображения. Обратното е вярно за генеративния модел, той се наказва (и параметрите му се актуализират), когато не успее да заблуди дискриминиращия модел, но в противен случай параметрите му остават непроменени (или се възнаграждава).
В идеалния случай генераторът е в състояние да подобри работата си до точка, в която дискриминаторът не може да различи между фалшивите и реалните изображения. Това означава, че дискриминаторът винаги ще изобразява вероятности от 50% за реални и фалшиви изображения, което означава, че генерираните изображения трябва да са неразличими от оригиналните изображения. На практика GAN обикновено няма да достигнат тази точка. Въпреки това, генеративният модел не трябва да създава съвършено подобни изображения, за да бъде полезен за многото задачи, за които се използват GAN.
GAN приложения
GAN имат редица различни приложения, повечето от които се въртят около генерирането на изображения и компоненти на изображения. GAN обикновено се използват в задачи, при които необходимите данни за изображения липсват или са ограничени в някакъв капацитет, като метод за генериране на необходимите данни. Нека разгледаме някои от обичайните случаи на употреба на GAN.
Генериране на нови примери за набори от данни
GAN могат да се използват за генериране на нови примери за прости набори от данни за изображения. Ако имате само няколко примера за обучение и се нуждаете от повече от тях, GAN могат да се използват за генериране на нови данни за обучение за класификатор на изображения, генерирайки нови примери за обучение при различни ориентации и ъгли.
Създаване на уникални човешки лица

Жената на тази снимка не съществува. Изображението е генерирано от StyleGAN. Снимка: Owlsmcgee чрез Wikimedia Commons, обществено достояние (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
Когато са достатъчно обучени, GAN могат да се използват за генерира изключително реалистични изображения на човешки лица. Тези генерирани изображения могат да се използват за подпомагане на обучението на системи за разпознаване на лица.
Превод от изображение към изображение
GAN превъзходство в превода на изображения. GAN могат да се използват за оцветяване на черно-бели изображения, превод на скици или чертежи във фотографски изображения или преобразуване на изображения от ден в нощ.
Превод от текст към изображение
Преводът от текст към изображение е възможно чрез използването на GAN. Когато се предостави текст, който описва изображение и това придружаващо изображение, GAN може бъдете обучени да създавате нов образ при предоставяне на описание на желаното изображение.
Редактиране и поправка на изображения
GAN могат да се използват за редактиране на съществуващи снимки. GANs премахнете елементи като дъжд или сняг от изображение, но могат да се използват и за поправете стари, повредени или повредени изображения.
Супер резолюция
Супер резолюцията е процес на заснемане на изображение с ниска разделителна способност и вмъкване на повече пиксели в изображението, подобрявайки разделителната способност на това изображение. GANs могат да бъдат обучени да правят изображение генерирайте версия с по-висока разделителна способност на това изображение.














