
AI 101 г
Какво е Gradient Descent?
Какво е градиентно спускане?
Ако сте чели за това как се обучават невронните мрежи, почти със сигурност сте срещали термина „градиентно спускане“ преди. Градиентно спускане е основният метод за оптимизиране на производителността на невронна мрежа, намалявайки процента на загуби/грешки в мрежата. Въпреки това градиентното спускане може да бъде малко трудно за разбиране за начинаещите в машинното обучение и тази статия ще се опита да ви даде прилична интуиция за това как работи градиентното спускане.
Градиентно спускане е алгоритъм за оптимизация. Използва се за подобряване на производителността на невронна мрежа чрез извършване на настройки на параметрите на мрежата, така че разликата между прогнозите на мрежата и действителните/очакваните стойности на мрежата (наричани загуба) да е възможно най-малка. Градиентното спускане взема първоначалните стойности на параметрите и използва операции, базирани на изчисление, за да коригира техните стойности към стойностите, които ще направят мрежата възможно най-точна. Не е нужно да знаете много математика, за да разберете как работи градиентното спускане, но трябва да имате разбиране за градиенти.
Какво представляват градиентите?
Да приемем, че има графика, която представя размера на грешката, която невронната мрежа прави. Долната част на графиката представлява точките с най-ниска грешка, докато горната част на графиката е мястото, където грешката е най-висока. Искаме да се придвижим от горната част на графиката надолу към дъното. Градиентът е просто начин за количествено определяне на връзката между грешката и теглата на невронната мрежа. Връзката между тези две неща може да се изобрази като наклон, като неправилните тегла водят до повече грешки. Стръмността на наклона/градиента показва колко бързо се учи моделът.
По-стръмен наклон означава, че се правят големи намаления на грешките и моделът се учи бързо, докато ако наклонът е нула, моделът е на плато и не се учи. Можем да се движим надолу по склона към по-малка грешка, като изчислим градиент, посока на движение (промяна в параметрите на мрежата) за нашия модел.
Нека изместим леко метафората и си представим поредица от хълмове и долини. Искаме да стигнем до дъното на хълма и да намерим частта от долината, която представлява най-ниската загуба. Когато тръгнем от върха на хълма, можем да правим големи стъпки надолу по хълма и да сме сигурни, че се насочваме към най-ниската точка в долината.
Въпреки това, докато се приближаваме до най-ниската точка в долината, стъпките ни ще трябва да стават по-малки, в противен случай можем да прескочим истинската най-ниска точка. По подобен начин е възможно при коригиране на теглата на мрежата, корекциите действително да я отдалечат от точката на най-ниска загуба и следователно корекциите трябва да стават по-малки с течение на времето. В контекста на спускане по хълм към точка с най-ниска загуба, градиентът е вектор/инструкции, описващи подробно пътя, който трябва да поемем и колко големи трябва да бъдат нашите стъпки.
Сега знаем, че градиентите са инструкции, които ни казват в коя посока да се движим (кои коефициенти трябва да бъдат актуализирани) и колко големи са стъпките, които трябва да предприемем (колко коефициентите трябва да бъдат актуализирани), можем да проучим как се изчислява градиентът.
Изчисляване на градиенти и градиентно спускане
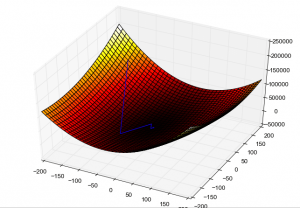
Градиентното спускане започва от място с голяма загуба и чрез множество итерации предприема стъпки в посока на най-ниската загуба, с цел намиране на оптималната конфигурация на теглото. Снимка: Роман Сузи чрез Wikimedia Commons, CCY BY SA 3.0 (https://commons.wikimedia.org/wiki/File:Gradient_descent_method.png)
За да се извърши градиентно спускане, градиентите трябва първо да бъдат изчислени. По ред за изчисляване на градиента, трябва да знаем функцията загуба/цена. Ще използваме функцията на разходите, за да определим производната. В смятането производната просто се отнася до наклона на функция в дадена точка, така че ние просто изчисляваме наклона на хълма въз основа на функцията на загубата. Определяме загубата, като пускаме коефициентите през функцията на загубата. Ако представим функцията на загубата като „f“, тогава можем да заявим, че уравнението за изчисляване на загубата е както следва (просто прекарваме коефициентите през избраната от нас функция на разходите):
Загуба = f(коефициент)
След това изчисляваме производната или определяме наклона. Получаването на производната на загубата ще ни каже коя посока е нагоре или надолу по склона, като ни даде подходящия знак, по който да коригираме нашите коефициенти. Ще представим подходящата посока като „делта“.
делта = производна_функция (загуба)
Вече определихме коя посока е надолу към точката на най-ниската загуба. Това означава, че можем да актуализираме коефициентите в параметрите на невронната мрежа и да се надяваме да намалим загубата. Ще актуализираме коефициентите въз основа на предишните коефициенти минус съответната промяна в стойността, определена от посоката (делта) и аргумент, който контролира големината на промяната (размера на нашата стъпка). Аргументът, който контролира размера на актуализацията, се нарича „скорост на обучение” и ще го представим като „алфа”.
коефициент = коефициент – (алфа * делта)
След това просто повтаряме този процес, докато мрежата се сближи около точката на най-ниска загуба, която трябва да бъде близо до нула.
Много е важно да изберете правилната стойност за скоростта на обучение (алфа). Избраната скорост на обучение не трябва да бъде нито твърде малка, нито твърде голяма. Не забравяйте, че когато се приближаваме до точката на най-ниска загуба, нашите стъпки трябва да стават по-малки или в противен случай ще прескочим истинската точка на най-ниска загуба и ще се окажем от другата страна. Точката на най-малката загуба е малка и ако нашата скорост на промяна е твърде голяма, грешката може в крайна сметка да се увеличи отново. Ако размерите на стъпките са твърде големи, производителността на мрежата ще продължи да се движи около точката на най-ниската загуба, превишавайки я от едната страна и след това от другата. Ако това се случи, мрежата никога няма да достигне до истинската оптимална конфигурация на теглото.
За разлика от това, ако скоростта на обучение е твърде малка, мрежата потенциално може да отнеме изключително дълго време, за да се сближи с оптималните тегла.
Видове градиентно спускане
След като разбираме как работи градиентното спускане като цяло, нека да разгледаме някои от различните видове градиентно спускане.
Пакетно градиентно спускане: Тази форма на градиентно спускане преминава през всички тренировъчни проби преди актуализиране на коефициентите. Този тип градиентно спускане вероятно ще бъде най-ефективната от изчислителна гледна точка форма на градиентно спускане, тъй като теглата се актуализират само след като цялата партида бъде обработена, което означава, че има общо по-малко актуализации. Въпреки това, ако наборът от данни съдържа голям брой примери за обучение, тогава спускането на партиден градиент може да накара обучението да отнеме много време.
Стохастичен градиентен спускане: При стохастичен градиентен спускане се обработва само един пример за обучение за всяка итерация на градиентно спускане и актуализиране на параметри. Това се случва за всеки пример за обучение. Тъй като само един пример за обучение се обработва преди параметрите да бъдат актуализирани, той има тенденция да се сближава по-бързо от Batch Gradient Descent, тъй като актуализациите се правят по-рано. Въпреки това, тъй като процесът трябва да се извърши върху всеки елемент в набора за обучение, завършването му може да отнеме доста дълго време, ако наборът от данни е голям, и затова се използва един от другите типове градиентно спускане, ако се предпочита.
Mini-Batch Gradient Descent: Mini-Batch Gradient Descent работи, като разделя целия набор от данни за обучение на подсекции. Той създава по-малки мини-партиди, които се изпълняват през мрежата, и когато мини-партията е била използвана за изчисляване на грешката, коефициентите се актуализират. Мини-пакетното градиентно спускане намира средата между стохастично градиентно спускане и пакетно градиентно спускане. Моделът се актуализира по-често, отколкото в случая на Batch Gradient Descent, което означава малко по-бързо и по-стабилно сближаване на оптималните параметри на модела. Освен това е по-ефективен в изчислителна гледна точка от стохастичния градиентен спускане














