
AI 101 г
Какво представляват CNN (конволюционни невронни мрежи)?
Може би сте се чудили как Facebook или Instagram могат автоматично да разпознават лица в изображение или как Google ви позволява да търсите подобни снимки в мрежата само като качите своя собствена снимка. Тези функции са примери за компютърно зрение и се захранват от конволюционни невронни мрежи (CNN). Но какво точно представляват конволюционните невронни мрежи? Нека се потопим дълбоко в архитектурата на CNN и да разберем как работят.
Какво представляват невронните мрежи?
Преди да започнем да говорим за конволюционни невронни мрежи, нека отделим малко време, за да дефинираме редовната невронна мрежа. има друга статия по темата за наличните невронни мрежи, така че няма да навлизаме твърде дълбоко в тях тук. Въпреки това, за да ги дефинираме накратко, те са изчислителни модели, вдъхновени от човешкия мозък. Невронната мрежа работи, като приема данни и манипулира данните чрез коригиране на „тегла“, които са предположения за това как входните характеристики са свързани помежду си и с класа на обекта. Тъй като мрежата се обучава, стойностите на теглата се коригират и се надяваме, че ще се сближат с тегла, които улавят точно връзките между характеристиките.
Това е начинът, по който работи невронната мрежа с подаване напред и CNN се състоят от две половини: невронна мрежа с подаване напред и група от конволюционни слоеве.
Какво представляват конволюционните невронни мрежи (CNN)?
Какви са „конволюциите“, които се случват в конволюционна невронна мрежа? Конволюцията е математическа операция, която създава набор от тегла, като по същество създава представяне на части от изображението. Този набор от тежести се нарича ядро или филтър. Създаденият филтър е по-малък от цялото входно изображение, покривайки само подсекция от изображението. Стойностите във филтъра се умножават със стойностите в изображението. След това филтърът се премества, за да формира представяне на нова част от изображението, и процесът се повтаря, докато се покрие цялото изображение.
Друг начин да мислите за това е да си представите тухлена стена, като тухлите представляват пикселите във входното изображение. „Прозорец“ се плъзга напред-назад по стената, което е филтърът. Тухлите, които се виждат през прозореца, са пикселите, чиято стойност е умножена по стойностите във филтъра. Поради тази причина този метод за създаване на тежести с филтър често се нарича техниката на „плъзгащи се прозорци“.
Резултатът от филтрите, които се преместват около цялото входно изображение, е двуизмерен масив, представящ цялото изображение. Този масив се нарича a „карта на функциите“.
Защо навивките са от съществено значение
Каква е целта на създаването на навивки? Навивките са необходими, защото невронната мрежа трябва да може да интерпретира пикселите в изображението като числови стойности. Функцията на конволюционните слоеве е да преобразуват изображението в числени стойности, които невронната мрежа може да интерпретира и след това да извлече съответните модели от тях. Работата на филтрите в конволюционната мрежа е да създадат двуизмерен масив от стойности, които могат да бъдат предадени в по-късните слоеве на невронна мрежа, тези, които ще научат моделите в изображението.
Филтри и канали
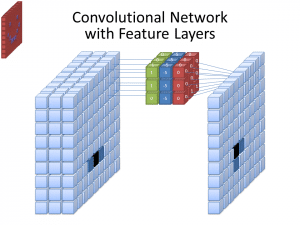
Снимка: cecebur чрез Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN не използват само един филтър, за да научат модели от входните изображения. Използват се множество филтри, тъй като различните масиви, създадени от различните филтри, водят до по-сложно, богато представяне на входното изображение. Общите номера на филтрите за CNN са 32, 64, 128 и 512. Колкото повече филтри има, толкова повече възможности има CNN да изследва входните данни и да се учи от тях.
CNN анализира разликите в стойностите на пикселите, за да определи границите на обектите. В изображение в сива скала CNN ще разгледа само разликите в черно и бяло, светло към тъмно. Когато изображенията са цветни, CNN не само взема предвид тъмното и светлото, но трябва да вземе под внимание и трите различни цветови канала – червено, зелено и синьо. В този случай филтрите притежават 3 канала, както и самото изображение. Броят на каналите, които има един филтър, се нарича неговата дълбочина, а броят на каналите във филтъра трябва да съвпада с броя на каналите в изображението.
Конволюционна невронна мрежа (CNN) архитектура
Нека да разгледаме пълната архитектура на конволюционна невронна мрежа. Конволюционен слой се намира в началото на всяка конволюционна мрежа, тъй като е необходимо да се трансформират данните за изображението в числови масиви. Конволюционните слоеве обаче могат също да идват след други конволюционни слоеве, което означава, че тези слоеве могат да бъдат подредени един върху друг. Наличието на множество конволюционни слоеве означава, че изходите от един слой могат да претърпят допълнителни конволюции и да бъдат групирани заедно в подходящи модели. На практика това означава, че докато данните за изображението преминават през конволюционните слоеве, мрежата започва да „разпознава“ по-сложни характеристики на изображението.
Ранните слоеве на ConvNet са отговорни за извличането на характеристиките на ниско ниво, като например пикселите, които изграждат прости линии. По-късните слоеве на ConvNet ще съединят тези линии във форми. Този процес на преминаване от анализ на повърхностно ниво към анализ на дълбоко ниво продължава, докато ConvNet започне да разпознава сложни форми като животни, човешки лица и автомобили.
След като данните преминат през всички конволюционни слоеве, те преминават към плътно свързаната част на CNN. Плътно свързаните слоеве са това, което изглежда традиционната невронна мрежа с подаване напред, поредица от възли, подредени в слоеве, които са свързани един с друг. Данните преминават през тези плътно свързани слоеве, които научават моделите, извлечени от конволюционните слоеве, и по този начин мрежата става способна да разпознава обекти.










