Anderson 视角
新型攻击“克隆”和滥用您的唯一在线 ID 通过浏览器指纹识别
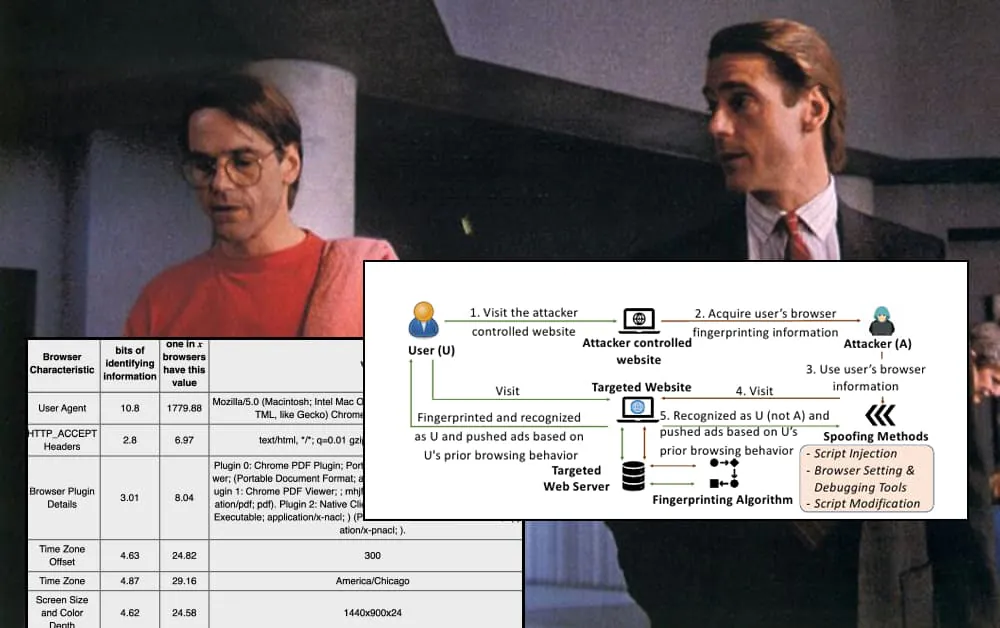
研究人员开发了一种方法,使用浏览器指纹识别技术复制受害者的 Web 浏览器特征,然后“伪装”成受害者。
这种技术具有多个安全含义:攻击者可以进行有害或甚至非法的在线活动,并将这些活动的“记录”归咎于用户;并且可以破坏两因素身份验证防御,因为验证网站认为用户已经成功识别,基于被盗的浏览器指纹配置文件
此外,攻击者的“影子克隆”可以访问更改向该用户配置文件提供的广告类型的网站,这意味着用户将开始接收与其实际浏览活动无关的广告内容。另外,攻击者可以根据其他(不知情的)网站对伪造的浏览器 ID 的响应推断出有关受害者的很多信息。
该 论文 的标题为 浏览器指纹识别:针对最新指纹识别技术的浏览器欺骗 ,由德克萨斯 A&M 大学和佛罗里达大学盖恩斯维尔分校的研究人员撰写。

Gummy Browsers 方法的概述。 来源:https://arxiv.org/pdf/2110.10129.pdf
浏览器指纹识别
所谓“浏览器指纹识别”是指复制受害者的浏览器配置文件,以便攻击者可以“伪装”成受害者。这种方法的名称来源于早期的“Gummy Fingers”攻击,该攻击使用明胶复制受害者的指纹,以绕过指纹识别系统。
作者指出:
“浏览器指纹识别的主要目标是欺骗 Web 服务器,使其认为合法用户正在访问其服务,以便可以了解用户的敏感信息(例如,基于个性化广告的用户兴趣),或规避依赖于浏览器指纹识别的各种安全方案(例如,身份验证和欺诈检测)。”
他们继续指出:
“不幸的是,我们发现了一个重大威胁向量,针对此类链接算法。具体来说,我们发现攻击者可以捕获和伪造受害者的浏览器特征,因此可以‘呈现’自己的浏览器作为受害者的浏览器,当连接到网站时。”
作者认为,他们开发的浏览器指纹识别技术对用户的在线隐私和安全构成了“毁灭性和长期的影响”。
在测试系统对两个指纹识别系统,FPStalker 和电子前沿基金会的 Panopticlick,作者发现他们的系统能够模拟捕获的用户信息几乎所有时间,尽管系统没有考虑到几个属性,包括 TCP/IP 堆栈 指纹识别、硬件传感器 和 DNS 解析器。
作者还指出,受害者将完全不知道攻击,使得很难规避。
方法论
浏览器指纹识别 配置文件是通过多个因素生成的,包括用户的 Web 浏览器配置。讽刺的是,许多旨在保护隐私的防御措施,包括安装广告拦截扩展,实际上可以使浏览器指纹识别更容易被攻击。
浏览器指纹识别不依赖于 cookie 或会话数据,而是提供了一个对用户设置的快照,可以被任何域名访问,如果该域名配置了利用此类信息的功能。
除了恶意行为,指纹识别通常用于定向广告、欺诈检测 和 用户身份验证(一个原因是添加扩展或对浏览器进行其他核心更改可能会导致网站要求重新身份验证,因为浏览器配置文件自上次访问以来已经更改)。
研究人员提出的方法只需要受害者访问一个配置了记录其浏览器指纹识别的网站——一种最近的研究 估计 在前 10 万个网站中占比超过 10%,并且是 Google 的 Federated Learning of Cohorts (FLOC) 的一部分,即搜索巨头提出的替代 cookie 跟踪的方案。它也是广告技术平台的一项核心技术,因此影响的范围远远超过上述研究中确定的 10% 的网站。

可以从用户浏览器中提取的典型方面,无需 cookie。
可以从用户访问中提取的标识符(通过 JavaScript API 和 HTTP 头收集)包括语言设置、操作系统、浏览器版本和扩展、安装的插件、屏幕分辨率、硬件、颜色深度、时区、时间戳、安装的字体、画布特征、用户代理字符串、HTTP 请求头、IP 地址和设备语言设置等。没有这些特征,很多常见的 Web 功能将无法实现。
通过广告网络响应提取信息
作者指出,通过模拟受害者的浏览器配置文件,可以轻松地泄露有关受害者的广告数据,并且可以 有用地利用:
“如果浏览器指纹识别用于个性化和定向广告,托管良性网站的 Web 服务器将向攻击者的浏览器推送与受害者的浏览器相同或类似的广告,因为 Web 服务器认为攻击者的浏览器是受害者的浏览器。根据个性化广告(例如,相关的怀孕产品、药品和品牌),攻击者可以推断出有关受害者的敏感信息(例如,性别、年龄组、健康状况、兴趣、薪水水平等),甚至可以建立受害者的个人行为配置文件。这种个人和私人信息的泄露可能会对用户构成可怕的隐私威胁。”
“浏览器指纹识别会随着时间的推移而改变,但只要用户继续访问攻击网站,就可以保持克隆配置文件的更新。但是,作者认为,即使是一次性克隆,也可以实现令人惊讶的长期有效攻击。”
用户身份验证欺骗
规避两因素身份验证对于网络攻击者来说是一个福音。正如新论文的作者所指出,许多当前的身份验证(2FA)框架使用“识别”的推断浏览器配置文件将帐户与用户关联。如果网站的身份验证系统满意地认为用户正在尝试在之前成功登录的设备上登录,它可能不会要求 2FA,出于用户便利的考虑。
作者观察到,Oracle、InAuth 和 SecureAuth IdP 都实行了一种“检查跳过”形式,基于用户的记录浏览器配置文件。
欺诈检测
各种安全服务使用浏览器指纹识别作为一种工具,以确定用户是否参与欺诈活动的可能性。研究人员指出,Seon 和 IPQualityScore 是两家此类公司。
因此,通过提出的方法,可以不公平地将用户标记为欺诈者,使用“影子配置文件”触发此类系统的阈值,或者使用被盗配置文件作为真正尝试欺诈的“伪装”,将法医分析从攻击者转移到受害者。
三个攻击面
论文提出了三种可能的使用 Gummy Browser 系统攻击受害者的方法:一次性获取,一次性欺骗 涉及获取受害者的浏览器 ID,以支持一次性攻击,例如尝试以用户的身份访问受保护的域名。在这种情况下,ID 的“年龄”无关紧要,因为信息被快速处理且无需后续跟进。
在第二种方法中,一次性获取,频繁欺骗,攻击者试图通过观察 Web 服务器如何响应其配置文件(即,广告服务器根据“熟悉”的用户交付特定内容,假设该用户已经有一个关联的浏览器配置文件)来开发受害者的配置文件。
最后,频繁获取,频繁欺骗 是一种长期策略,旨在通过让受害者重复访问无害的数据泄露网站(可能是新闻网站或博客)来定期更新受害者的浏览器配置文件。这样,攻击者就可以在更长的时间内执行欺诈检测欺骗。
提取和结果
Gummy Browsers 中使用的欺骗方法包括脚本注入、使用浏览器的设置和调试工具以及脚本修改。
可以使用或不使用 JavaScript 来提取这些特征。例如,用户代理头(它可以识别浏览器品牌,例如 Chrome、Firefox 等),可以从 HTTP 头中推导出来,这是功能性 Web 浏览所必需的最基本和不可阻塞的信息之一。
在测试 Gummy Browser 系统对 FPStalker 和 Panopticlick 时,研究人员在三个指纹识别算法中实现了超过 0.95 的平均“所有权”(适用于获取的浏览器配置文件),从而实现了对捕获的 ID 的可行克隆。
论文强调了系统架构师不应仅依赖浏览器配置文件特征作为安全令牌的必要性,并且批评了一些较大的身份验证框架采用了这种做法,特别是当它被用作维持“用户友好性”的方法时,通过绕过或延迟两因素身份验证的使用。
作者得出结论:
“Gummy Browsers 的影响可能对用户的在线安全和隐私产生毁灭性和长期的影响,特别是考虑到浏览器指纹识别开始在现实世界中被广泛采用。在此攻击的光照下,我们的工作提出了一个问题,即浏览器指纹识别是否可以在大规模上安全部署。”












