思想领袖
3 种方法让大型语言模型中的过时事实保持新鲜
大型语言模型(LLM)如 GPT3、ChatGPT 和 BARD 现在非常流行。每个人都对这些工具对社会的影响以及它们对 AI 未来的意义有自己的看法。Google 因其新模型 BARD 对一个复杂问题的回答稍微错误而受到很多批评。当被问及“有什么关于詹姆斯·韦伯太空望远镜的新发现可以告诉我的 9 岁孩子?”时,聊天机器人提供了三个答案,其中两个是正确的,一个是错误的。错误的答案是,第一张“系外行星”图片是由 JWST 拍摄的,这是不正确的。因此,模型在其知识库中存储了一个不正确的事实。为了使大型语言模型有效,我们需要一种方法来更新这些事实或用新知识增强事实。
让我们首先看看大型语言模型(LLM)内部如何存储事实。大型语言模型不像传统数据库或文件那样存储信息和事实。相反,它们是在大量文本数据上进行训练的,并在这些数据中学习了模式和关系。这使得它们能够生成类似人类的响应来回答问题,但它们没有特定的存储位置来存储其学习的信息。当回答问题时,模型使用其训练来生成一个基于输入的响应。语言模型所具有的信息和知识是其在训练数据中学习的模式的结果,而不是因为它被显式地存储在模型的内存中。大多数现代 LLM 都基于 Transformer 架构,具有用于回答提示中提出的问题的内部事实编码。

因此,如果 LLM 内部内存中的事实是错误或过时的,需要通过提示提供新的信息。提示是发送到 LLM 的文本,包含查询和支持证据,可以是新的或更正的事实。以下是 3 种方法。
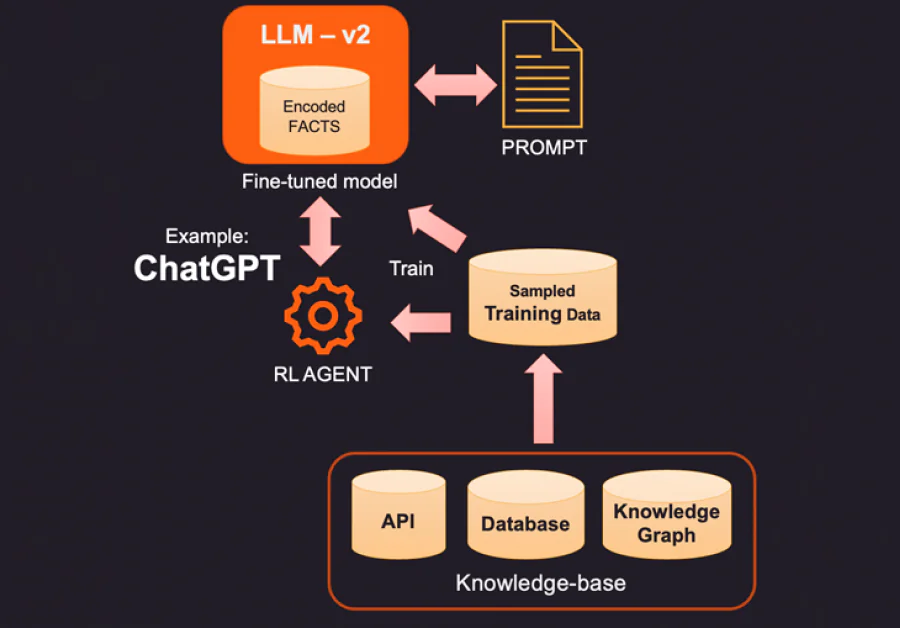
1. 更正 LLM 中编码的事实的一种方法是使用外部知识库提供相关的新事实。这个知识库可能是 API 调用以获取相关信息,或者是 SQL、No-SQL 或向量数据库的查找。更高级的知识可以从存储数据实体和它们之间关系的知识图中提取。根据用户查询的信息,可以检索相关的上下文信息并作为额外的事实提供给 LLM。这些事实也可以格式化为类似训练示例的形式,以提高学习过程。例如,您可以传递一组问题答案对,以便模型学习如何提供答案。

2. 增强 LLM 的一种更具创新性(也更昂贵)的方法是使用训练数据进行微调。因此,instead of 查询知识库以添加特定的事实,我们通过对知识库进行采样来构建训练数据集。使用监督学习技术(如微调),我们可以创建一个在此额外知识上进行训练的新 LLM 版本。这个过程通常很昂贵,并且在 OpenAI 中构建和维护一个微调模型的成本可能为几千美元。当然,成本预计会随着时间的推移而降低。
3. 另一个选项是使用强化学习(RL)等方法来训练一个带有人类反馈的代理,并学习如何回答问题的策略。这种方法在构建小型模型方面非常有效,这些模型可以很好地完成特定任务。例如,OpenAI 发布的 ChatGPT 是在监督学习和人类反馈的强化学习的组合上进行训练的。

总之,这是一个快速发展的领域,每个主要公司都希望参与并展示其差异化。我们很快就会在大多数领域(如零售、医疗保健和银行)看到主要的 LLM 工具,这些工具可以以类似人类的方式响应,理解语言的细微差别。这些集成企业数据的 LLM 驱动工具可以简化访问并使正确的数据在正确的时间提供给正确的人。












