Штучний інтелект
Як Стабільна Дифузія Може Розвинутися в Основний Консумерський Продукт

Іронічно, Стабільна Дифузія, новий каркас синтезу зображень штучного інтелекту, який захопив світ, насправді не є стабільним і не дуже “дифузним” – принаймні, поки що.
Повний діапазон можливостей системи розкиданий по різноманітному набору постійно мутуючих пропозицій від невеликої групи розробників, які лихоманіють останні відомості та теорії в різних коло-квіумах на Discord – і більшість процедур установки пакетів, які вони створюють або змінюють, дуже далекі від “підключи і грай”.
Натомість вони часто вимагають встановлення через командний рядок або BAT-драйвер за допомогою GIT, Conda, Python, Miniconda та інших передових каркасів розробки – програмні пакети так рідкісні серед загальної маси споживачів, що їхнє встановлення часто позначається антивірусними та анти-шпигунськими програмами як ознака компрометованої системи.
[підпис до малюнку id=”attachment_183833″ align=”alignnone” width=”908″]
Потоки повідомлень у спільнотах SFW і NSFW Стабільної Дифузії переповнені порадами та хитрощами, пов’язаними з хакінгом скриптів Python та стандартних інсталяцій, щоб активувати покращену функціональність або вирішити часті помилки залежностей та інші проблеми.
Це залишає середнього споживача, який цікавиться створенням чудових зображень з текстових підказок, майже безпорадним перед зростаючою кількістю монетизованих веб-інтерфейсів API, більшість з яких пропонує мінімальну кількість безкоштовних генерацій зображень перед покупкою токенів.
Крім того, майже всі ці веб-пропозиції відмовляються виводити контент NSFW (багато з яких можуть стосуватися не-порнографічних предметів загального інтересу, таких як “війна”), який відрізняє Стабільну Дифузію від цензурованих послуг DALL-E 2 від OpenAI.
‘Photoshop для Стабільної Дифузії’
Зачаровані фантастичними, сміливими або іншопланетними зображеннями, які населяють хештег #stablediffusion у Twitter щодня, те, чого очікує ширший світ, – це ‘Photoshop для Стабільної Дифузії’ – це перехрестно-платформена програма, яка включає в себе найкращу та найпотужнішу функціональність архітектури Stability.ai, а також різні винахідливі інновації спільноти розробників SD, без жодних плаваючих вікна командного рядка, незрозумілих та постійно мутуючих процедур інсталяції та оновлення, або відсутніх функцій.
Те, що у нас зараз є в більшості здатних інсталяцій, – це різноманітна веб-сторінка, що межує з відокремленим вікном командного рядка, а її URL – це порт localhost:
[підпис до малюнку id=”attachment_183834″ align=”alignnone” width=”908″]
Без сумніву, більш потокова програма вже прийде. Вже є кілька патронних інтегральних програм, які можна завантажити, таких як GRisk та NMKD (див. зображення нижче) – але жодна з них поки не інтегрує повний діапазон функцій, який можуть пропонувати деякі більш просунуті та менш доступні реалізації Стабільної Дифузії.
[підпис до малюнку id=”attachment_183835″ align=”alignnone” width=”997″]
Давайте розглянемо, яким може бути більш поліпшена та інтегральна реалізація цієї надзвичайної відкритої чудової речі – і які виклики вона може зустріти.
Юридичні Аспекти для Повністю Фінансованої Комерційної Програми Стабільної Дифузії
Фактор NSFW
Вихідний код Стабільної Дифузії було випущено під дуже перmissive ліцензією, яка не забороняє комерційні реімплементації та похідні роботи, які будуються на основі вихідного коду.
Крім згаданих патронних побудов Стабільної Дифузії, а також численних плагінів додатків, які розробляються для Figma, Krita, Photoshop, GIMP та Blender (серед інших), немає практичної причини, чому добре фінансована компанія з розробки програмного забезпечення не могла б розробити набагато більш складну та здатну програму Стабільної Дифузії. З ринкової точки зору, є кожна підстава вірити, що кілька таких ініціатив вже добре просунуті.
Тут такі зусилля одразу ж зустрічають дилему щодо того, чи дозволить програма виробляти рідну фільтр NSFW Стабільної Дифузії (фрагмент коду), щоб його можна було вимкнути.
‘Поховання’ Перемикача NSFW
Хоча відкрита ліцензія Stability.ai на Стабільну Дифузію включає широко інтерпретований список застосунків, для яких вона не може бути використана (можливо, включаючи порнографічний контент та дипфейки), єдиний спосіб, яким виробник міг би ефективно заборонити таке використання, полягає у тому, щоб скомпілювати фільтр NSFW в непрозорий виконавчий файл замість параметра в файлі Python, або ж примусити порівняння контрольної суми файлу Python або DLL, який містить директиву NSFW, так що рендеринг не може відбутися, якщо користувачі змінюють цю налаштування.
Це залишило б програму “кастрованою” майже так само, як і DALL-E 2 зараз, зменшуючи її комерційну привабливість. Також, неминуче, декомпільовані “докторовані” версії цих компонентів (або оригінальних елементів часу виконання Python, або скомпільованих файлів DLL, як зараз використовується в лінії інструментів Topaz AI) ймовірно з’являться в спільноті торрентів/хакінгу, просто замінивши перешкоджуючі елементи та анулюючи будь-які вимоги контрольної суми.
У кінцевому підсумку виробник може просто повторити попередження Stability.ai про неправильне використання, яке характеризує перший запуск багатьох поточних розподілів Стабільної Дифузії.
Однак маленькі відкриті розробники зараз використовують такі випадкові застереження, мають мало чого втрачати у порівнянні з компанією програмного забезпечення, яка вклала значну кількість часу та грошей у те, щоб зробити Стабільну Дифузію повноцінною та доступною – що запрошує глибше розгляд.
Відповідальність за Дипфейки
Як ми недавно відзначили, база даних LAION-естетики, частина 4,2 мільярдів зображень, на яких були навчені поточні моделі Стабільної Дифузії, містить велику кількість зображень знаменитостей, що дозволяє користувачам ефективно створювати дипфейки, включаючи дипфейки знаменитостей.
[підпис до малюнку id=”attachment_183836″ align=”alignnone” width=”1200″]
Це окрема і більш суперечлива проблема, ніж генерація (зазвичай) легального “абстрактного” порно, яке не зображує “реальних” людей (хоча такі зображення виводяться з多численних реальних фотографій у навчальному матеріалі).
Оскільки все більша кількість держав і країн розробляють або прийняли закони проти дипфейкового порно, здатність Стабільної Дифузії створювати дипфейки знаменитостей могла б означати, що комерційна програма, яка не зовсім цензурується (тобто може створювати порнографічний матеріал), все ж могла б потребувати деякої здатності фільтрувати виявлені обличчя знаменитостей.
Один із методів міг би полягати у наданні вбудованого “чорного списку” термінів, які не будуть прийняті в користувацькій підказці, пов’язаних з іменами знаменитостей та вигаданими персонажами, з якими вони можуть бути пов’язані. Присутньо такі налаштування мали б бути встановлені в більшої кількості мов, ніж просто англійська, оскільки вихідні дані містять інші мови. Інший підхід міг би полягати у включенні систем розпізнавання знаменитостей, таких як ті, що розроблені Clarifai.
Можливо, буде необхідно для виробників програмного забезпечення включити такі методи, можливо, спочатку вимкнені, що могло б допомогти у запобіганні повноцінній самостійній програмі Стабільної Дифузії генерації облич знаменитостей, поки не буде прийнято нове законодавство, яке могло б зробити таку функціональність незаконною.
Знову ж таки, однак, така функціональність могла б бути декомпільована та зворотною інженерією зацікавленими сторонами; однак виробник програмного забезпечення міг би заявити, що це є ефективно несанкціонованою вандалізмом – поки така зворотна інженерія не робиться надмірно легкою.
Функції, які можуть бути включені
Основна функціональність будь-якої розподіленої Стабільної Дифузії мала б бути очікувана будь-якої добре фінансованої комерційної програми. Це включають можливість використовувати текстові підказки для генерації відповідних зображень (текст-у-зображення); можливість використовувати ескізи або інші зображення як орієнтири для нових згенерованих зображень (зображення-у-зображення); засоби для регулювання того, наскільки “фантазійна” система повинна бути; спосіб обміну часу рендерингу за якістю; та інші “основи”, такі як необов’язковий автоматичний архів зображень/підказок, і звичайний необов’язковий апскейлінг через RealESRGAN, і щонайменше базове “виправлення обличчя” з GFPGAN або CodeFormer.
Це досить “ванільна інсталяція”. Давайте розглянемо деякі більш просунуті функції, які зараз розробляються або розширюються, які могли б бути включені у повноцінну “традиційну” програму Стабільної Дифузії.
Стохастичне Зупинення
Дажи якщо ви перевикористовуєте насіння з попередньої успішної генерації, це дуже важко змусити Стабільну Дифузію точно повторити перетворення, якщо будь-яка частина підказки або вихідного зображення (або обидва) змінені для наступної генерації.
Це проблема, якщо ви хочете використовувати EbSynth, щоб накласти перетворення Стабільної Дифузії на реальне відео тимчасово-співвідносним способом – хоча техніка може бути дуже ефективною для простих знімків голови та плечей:
[підпис до малюнку id=”attachment_183837″ align=”alignnone” width=”389″] Обмежений рух може зробити EbSynth ефективним засобом для перетворення перетворень Стабільної Дифузії у реалістичне відео. Джерело: https://streamable.com/u0pgzd[/підпис до малюнку]
Обмежений рух може зробити EbSynth ефективним засобом для перетворення перетворень Стабільної Дифузії у реалістичне відео. Джерело: https://streamable.com/u0pgzd[/підпис до малюнку]
EbSynth працює шляхом екстраполяції невеликої кількості “змінених” ключових кадрів у відео, яке було відтворено у серію файлів зображень (і яке можна пізніше зібрати назад у відео).
[підпис до малюнку id=”attachment_183838″ align=”alignnone” width=”1118″]
У прикладі нижче, який містить майже жодного руху від справжньої блондинки-інструкторки з йоги зліва, Стабільна Дифузія все ж має труднощі з підтриманням постійного обличчя, оскільки три зображення, які перетворюються як “кадри”, не зовсім ідентичні, хоча вони всі мають相同не числове насіння.
[підпис до малюнку id=”attachment_183839″ align=”alignnone” width=”601″]
Хоча відео нижче дуже винахідливе, де пальці користувача перетворилися на (відповідно) ходячу пару штанів та качку, несумісність штанів типіфікує проблему, яку має Стабільна Дифузія з підтриманням сумісності між різними кадрами, навіть коли вихідні кадри схожі один на одного, а насіння постійне.
[підпис до малюнку id=”attachment_183840″ align=”alignnone” width=”520″] Пальці людини перетворюються на ходячу людину та качку, за допомогою Стабільної Дифузії та EbSynth. Джерело: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/[/підпис до малюнку]
Пальці людини перетворюються на ходячу людину та качку, за допомогою Стабільної Дифузії та EbSynth. Джерело: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/[/підпис до малюнку]
Користувач, який створив це відео відкоментував, що перетворення качки, яке можна вважати більш ефективним, якщо не так стрімким і оригінальним, потребувало лише одного перетвореного кадру, тоді як для створення ходячих штанів потрібно було відтворити 50 зображень Стабільної Дифузії, які демонструють більшу тимчасову несумісність. Користувач також відзначив, що для досягнення сумісності для кожного з 50 кадрів потрібно було п’ять спроб.
Отже, було б великою перевагою для повноцінної програми Стабільної Дифузії надати функціональність, яка зберігає характеристики максимально можливого ступеня між кадрами.
Одна з можливостей полягає у тому, щоб дозволити користувачеві “заморозити” стохастичне кодування для перетворення на кожному кадрі, що зараз можна зробити лише шляхом зміни вихідного коду вручну. Як приклад нижче показує, це допомагає тимчасовій сумісності, хоча воно, безумовно, не вирішує її:
[підпис до малюнку id=”attachment_183843″ align=”alignnone” width=”500″] Один користувач перетворив кадри веб-камери себе на різних знаменитих людей, не тільки зберігаючи насіння (що може зробити будь-яка реалізація Стабільної Дифузії), але й тим, що стохастичне кодування було ідентичним у кожному перетворенні. Це було зроблено шляхом зміни коду, але могло б легко стати користувацьким перемикачем. Чітко, однак, воно не вирішує всі тимчасові проблеми. Джерело: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/[/підпис до малюнку]
Один користувач перетворив кадри веб-камери себе на різних знаменитих людей, не тільки зберігаючи насіння (що може зробити будь-яка реалізація Стабільної Дифузії), але й тим, що стохастичне кодування було ідентичним у кожному перетворенні. Це було зроблено шляхом зміни коду, але могло б легко стати користувацьким перемикачем. Чітко, однак, воно не вирішує всі тимчасові проблеми. Джерело: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/[/підпис до малюнку]
Хмарний Текстовий Переворот
Кращим рішенням для отримання тимчасово сумісних персонажів та об’єктів є “запікання” їх у Текстовий Переворот – файл розміром 5 КБ, який можна натренувати за кілька годин на основі лише п’яти анотованих зображень, який потім можна викликати спеціальною ‘*’ підказкою, дозволяючи, наприклад, постійний вигляд нових персонажів для включення в розповідь.
[підпис до малюнку id=”attachment_183844″ align=”alignnone” width=”1200″]
Текстові Перевороти – це додаткові файли до великої та повністю натренованої моделі, яку використовує Стабільна Дифузія, і фактично “причеплені” до процесу виклику/підказки, так що вони можуть брати участь у сценах, виведених моделлю, і користуватися величезною базою знань моделі про об’єкти, стилі, середовища та взаємодії.
Однак, хоча Текстовий Переворот не займає багато часу, він вимагає великої кількості відеопам’яті; згідно з різними поточними інструкціями, це дефінічно між 12, 20 та навіть 40 ГБ.
Оскільки більшість випадкових користувачів навряд чи мають такий обсяг GPU під рукою, хмарні послуги вже з’являються, які будуть виконувати цю операцію, включаючи версію Hugging Face. Хоча існують реалізації Google Colab, які можуть створювати текстові перевороти для Стабільної Дифузії, необхідні вимоги до відеопам’яті та часу можуть зробити це складним для користувачів безкоштовного рівня Colab.
Для потенційної повноцінної та добре інвестованої програми Стабільної Дифузії (встановленої) було б очевидною стратегією монетизації передача цього важкого завдання на сервери компанії у хмарі (припускаючи, що низька або безкоштовна програма Стабільної Дифузії пронизана такою несвободною функціональністю, що здається ймовірним у багатьох можливих застосунках, які виникнуть з цієї технології протягом наступних 6-9 місяців).
Крім того, досить складний процес анотації та форматування наданих зображень та тексту міг би виграти від автоматизації у інтегрованому середовищі. Потенційний “адиктивний фактор” створення унікальних елементів, які можуть досліджувати та взаємодіяти з величезними світами Стабільної Дифузії, здається потенційно компульсивним, як для загальних ентузіастів, так і для молодих користувачів.
Універсальне Вагове Підказування
Є багато поточних реалізацій, які дозволяють користувачеві призначити більшу вагу розділу довгої текстової підказки, але інструментарій сильно відрізняється між ними, і часто є незручним або незрозумілим.
Дуже популярний форк Стабільної Дифузії від AUTOMATIC1111, наприклад, може знижувати або підвищувати значення слова підказки, охоплюючи його в одинарні або подвійні дужки (для зниження ваги) або квадратні дужки для додаткової ваги.
[підпис до малюнку id=”attachment_183845″ align=”alignnone” width=”989″]
Інші ітерації Стабільної Дифузії використовують знаки оклику для наголосу, тоді як найбільш універсальні дозволяють користувачам призначати ваги кожному слову підказки через GUI.
Система також мала б дозволяти від’ємні ваги підказок – не тільки для фанатів жахів, але тому, що можуть бути менше тривожних та більш освітніх загадок у латентному просторі Стабільної Дифузії, ніж наша обмежена мова може викликати.
Розфарбовування
Незабаром після відкриття джерельного коду Стабільної Дифузії OpenAI спробував – в основному марно – відновити частину свого DALL-E 2 блиску, оголосивши про “розфарбовування”, яке дозволяє користувачеві розширити зображення за його межі з семантичною логікою та візуальною узгодженість.
Природно, це вже було реалізовано у різних формах для Стабільної Дифузії, а також у Krita, і mělo б бути включено у повноцінну, фотошопоподібну версію Стабільної Дифузії.
[підпис до малюнку id=”attachment_183846″ align=”alignnone” width=”708″]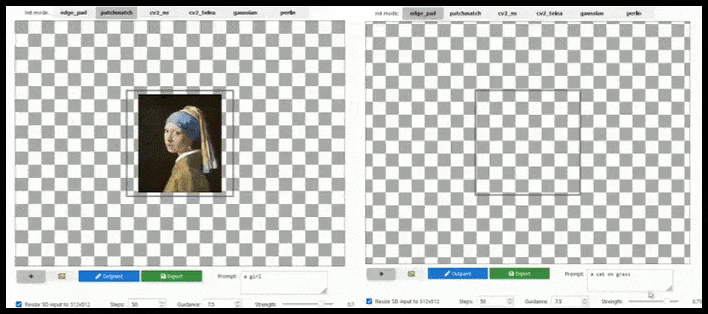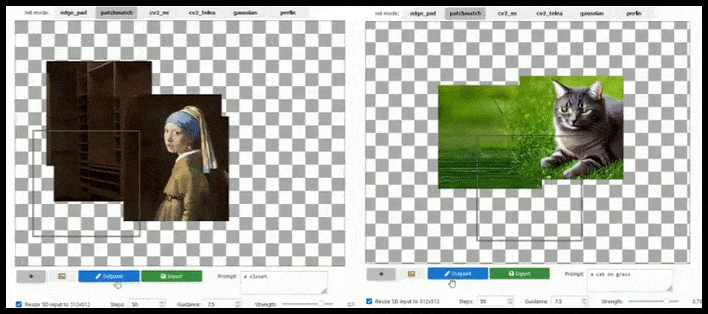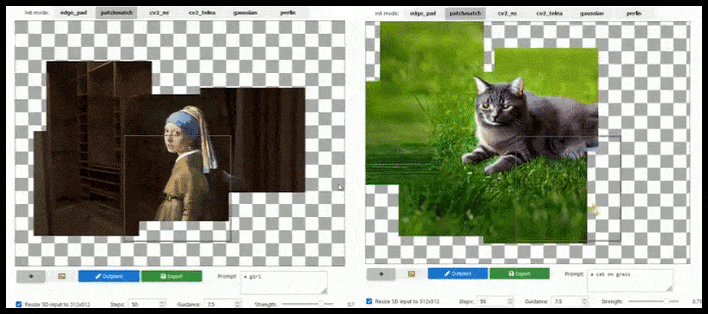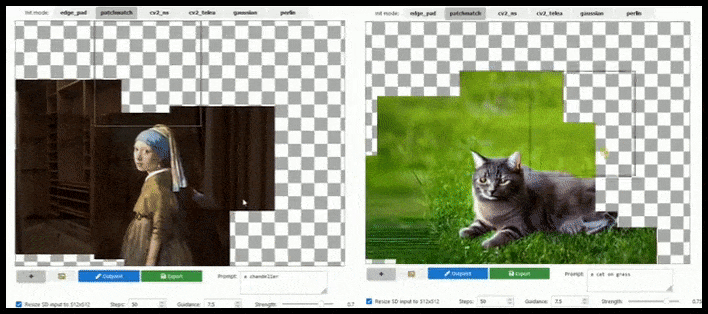 Тайлове розширення може розширити стандартний рендер 512×512 майже нескінченно, поки підказки, існуюче зображення та семантична логіка дозволяють це. Джерело: https://github.com/lkwq007/stablediffusion-infinity[/підпис до малюнку]
Тайлове розширення може розширити стандартний рендер 512×512 майже нескінченно, поки підказки, існуюче зображення та семантична логіка дозволяють це. Джерело: https://github.com/lkwq007/stablediffusion-infinity[/підпис до малюнку]
Оскільки Стабільна Дифузія навчена на зображеннях 512x512px (і з ряду інших причин), вона часто відрубує голови (або інші важливі частини тіла) людей, навіть якщо підказка чітко вказувала на “акцент на голові” тощо.
[підпис до малюнку id=”attachment_183847″ align=”alignnone” width=”1200″]
Будь-яка реалізація розфарбовування такого типу, як показано на анімованому зображенні вище (яке засновано виключно на бібліотеках Unix, але повинно бути здатне бути відтвореним у Windows), також мала б бути інструментом для одноклікового/підказкового лікування цієї проблеми.
Наразі багато користувачів розширюють полотно “обезголовлених” зображень вгору, приблизно заповнюють область голови та використовують img2img, щоб завершити пошкоджену генерацію.
Ефективне Маскування, яке Розуміє Контекст
Маскування може бути дуже невдалим у Стабільній Дифузії, залежно від форку або версії, яка використовується. Часто, де тільки можливо створити суцільну маску, вказана область закінчується наповненою контентом, який не бере до уваги весь контекст зображення.
У одному випадку я замаскував райдужні оболонки обличчя зображення та надав підказку ‘сині очі’ як масковане наповнення – тільки щоб побачити, що я, здавалося, дивлюся через два вирізані людські очі на віддалений зображення потустороннього вовка. Гадаю, я щасливий, що це не був Френк Сінатра.
Семантичне редагування також можливо шляхом визначення шуму, який створив зображення спочатку, що дозволяє користувачеві звернутися до конкретних структурних елементів у рендерінгу без втручання в решту зображення:
[підпис до малюнку id=”attachment_183848″ align=”alignnone” width=”1200″]
Цей метод заснований на зразку K-Diffusion.
Семантичні Фільтри для Фізіологічних Помилок
Як ми вже згадували, Стабільна Дифузія може часто додавати або віднімати кінцівки, головним чином через проблеми з даними та недоліки в анотаціях, які супроводжують зображення, на яких вона була навчена.
[підпис до малюнку id=”attachment_183851″ align=”alignnone” width=”1100″]
Було б корисно, якщо повноцінна програма Стабільної Дифузії містила б якийсь анатомічний розпізнавальний механізм, який використовував би семантичну сегментацію для розрахунку того, чи містить вхідне зображення серйозні анатомічні дефекти (як на зображенні вище), і відкидав би його на користь нового рендерингу, перш ніж представити його користувачеві.

Очевидно, ви можете захотіти згенерувати богиню Калі, або Доктора Октопуса, або навіть врятувати неушкоджену частину зображення з кінцівкою, постраждалою на зображенні. Отже, цю функцію слід зробити опціональним перемикачем.
Якщо користувачі могли б терпіти аспект телеметрії, такі промахи могли б бути передані анонімно в колективних зусиллях федеративного навчання, яке могло б допомогти майбутнім моделям покращити їхнє розуміння анатомічної логіки.
Автоматичне Покращення Обличчя на основі LAION
Як я відзначив у своєму попередньому розгляді трьох речей, які Стабільна Дифузія могла б звернути увагу у майбутньому, вона не повинна покладатися виключно на GFPGAN для спроби “покращити” згенеровані обличчя у першій інстанції.
Покращення GFPGAN дуже загальні, часто підірвають ідентичність зображеного індивіда та діють лише на обличчі, яке було згенеровано так само, як і будь-яка інша частина зображення, тобто не отримало жодної додаткової обробки чи уваги.
Отже, професійна програма для Стабільної Дифузії повинна бути здатна розпізнати обличчя (із стандартною та відносно легкою бібліотекою, такою як YOLO), застосувати повну вагу доступної потужності GPU до перезгенерування його, і або об’єднати поліпшене обличчя з оригінальним рендерингом у повному контексті, або зберегти його окремо для ручної рекомпозиції. Наразі це досить ручна операція.
[підпис до малюнку id=”attachment_183853″ align=”alignnone” width=”798″]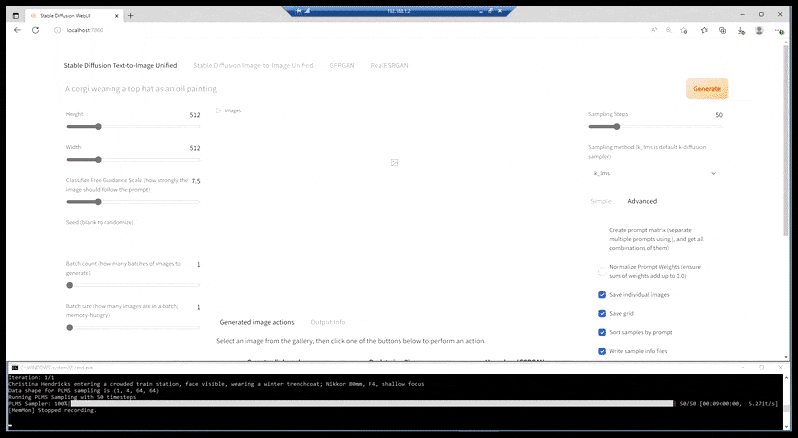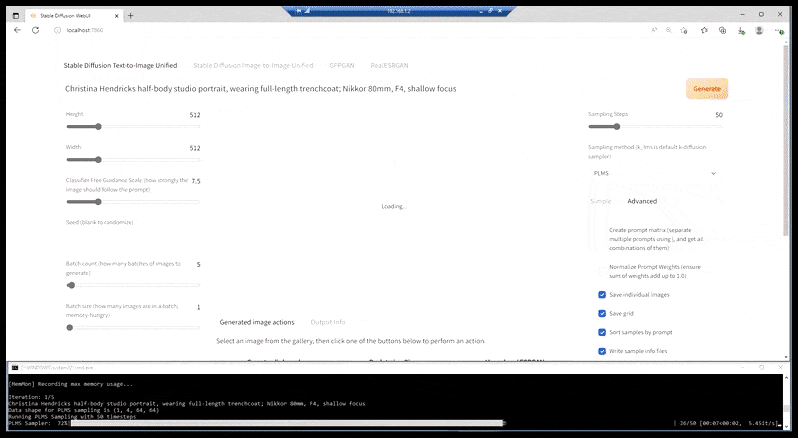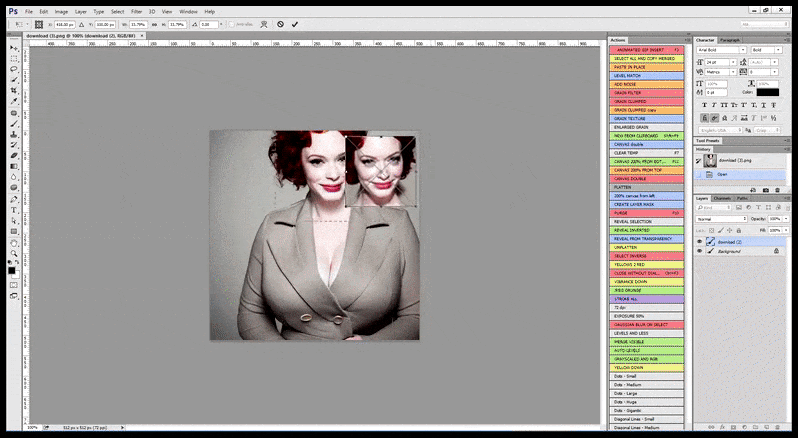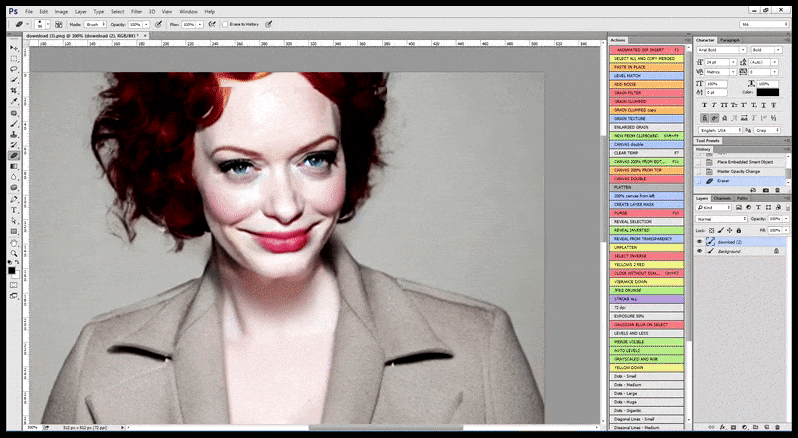 У випадках, коли Стабільна Дифузія була навчена на достатній кількості зображень знаменитості, можна сконцентрувати всю потужність GPU на наступному рендерингу лише обличчя згенерованого зображення, яке зазвичай є помітним покращенням – і, на відміну від GFPGAN, це черпає з інформації з даних LAION, а не просто коригує згенеровані пікселі.[/підпис до малюнку]
У випадках, коли Стабільна Дифузія була навчена на достатній кількості зображень знаменитості, можна сконцентрувати всю потужність GPU на наступному рендерингу лише обличчя згенерованого зображення, яке зазвичай є помітним покращенням – і, на відміну від GFPGAN, це черпає з інформації з даних LAION, а не просто коригує згенеровані пікселі.[/підпис до малюнку]
Пошук у LAION у Програмі
Відтоді, як користувачі почали усвідомлювати, що пошук у базі даних LAION для концепцій, людей та тем може стати допоміжним засобом для кращого використання Стабільної Дифузії, було створено кілька онлайн-експлорерів LAION, включаючи haveibeentrained.com.
[підпис до малюнку id=”attachment_183854″ align=”alignnone” width=”871″]
Хоча такі веб-бази даних часто розкривають деякі теги, які супроводжують зображення, процес генералізації, який відбувається під час навчання моделі, означає, що малоймовірно, що будь-яке окреме зображення могло б бути викликано, використовуючи його тег як підказку.
Крім того, видалення ‘стоп-слів’ та практика стемінгу та лематизації у обробці природної мови означає, що багато фраз, показаних тут, були розбиті або вилучені до навчання у Стабільній Дифузії.
Тим не менш, те, як естетичні групування зв’язуються в цих інтерфейсах, може навчити кінцевого користувача багато чого про логіку (або, можливо, “особистість”) Стабільної Дифузії, і стати допоміжним засобом для кращої генерації зображень.
Висновок
Є багато інших функцій, які я хотів би побачити у повноцінній настільній реалізації Стабільної Дифузії, таких як вбудований аналіз зображень на основі CLIP, який зворотньо перетворює стандартний процес Стабільної Дифузії та дозволяє користувачеві викликати фрази та слова, які система природно асоціює з вихідним зображенням, або рендерингом.
Крім того, справжнє тайлове масштабування було б ласкавим додаванням, оскільки ESRGAN майже так же тупий інструмент, як і GFPGAN. На щастя, плани інтегрувати реалізацію txt2imghd GOBIG швидко роблять це реальністю по всьому розподілу, і це здається очевидним вибором для настільної ітерації.
Деякі інші популярні прохання з спільнот Discord цікавлять мене менше, такі як інтегровані словники підказок та застосовні списки художників та стилів, хоча вбудований блокнот або настраїваний лексикон фраз здається логічним додаванням.
Аналогічно, поточні обмеження людської анімації у Стабільній Дифузії, хоча й отримали поштовх від CogVideo та інших проектів, залишаються надзвичайно насічними та залежать від досліджень у верхній частині темпоральних попередніх умов, пов’язаних з справжнім рухом людини.
Наразі відео Стабільної Дифузії строго психоделічне, хоча воно може мати яскраве майбутнє у дипфейковому ляльководі через EbSynth та інші відносно нові текст-у-відео ініціативи (і варто відзначити відсутність синтезованих чи “змінених” людей у останньому промо-відео Runway).
Інша цінна функціональність була б прозорим проходом Photoshop, який уже давно встановлений у редакторі текстур Cinema4D, серед інших подібних реалізацій. З цим можна легко перекидувати зображення між програмами та використовувати кожну програму для виконання перетворень, у яких вона excels.
Нарешті, і, можливо, найважливіше, повноцінна програма Стабільної Дифузії повинна бути здатна не тільки легко перемикатися між контрольними точками (тобто версіями основної моделі, яка живить систему), але також оновлювати саморобні Текстові Перевороти, які працювали з попередніми офіційними випусками моделі, але можуть бути зламані пізнішими версіями моделі (як розробники офіційного Discord вказали, що це могло бути випадком).












