Штучний інтелект
Перша річниця ChatGPT: формування майбутнього взаємодії з штучним інтелектом

Розглянувши перший рік існування ChatGPT, стало ясно, що цей інструмент суттєво змінив сцену штучного інтелекту. Запущений у кінці 2022 року, ChatGPT виділився своєю дружньою, розмовною стилістикою, яка зробила взаємодію з штучним інтелектом схожою на розмову з людиною, а не з машиною. Цій новий підхід швидко привернув увагу громадськості. Уже через п’ять днів після випуску ChatGPT привернув мільйон користувачів. На початку 2023 року ця кількість зросла до близько 100 мільйонів місячних користувачів, а до жовтня платформа мала близько 1,7 мільярда відвідувань у світі. Ці цифри свідчать про його популярність і корисність.
За минулий рік користувачі знайшли різні творчі способи використання ChatGPT, від простих завдань, таких як написання електронних листів і оновлення резюме, до створення успішних бізнесів. Але це не тільки про те, як люди його використовують; сама технологія також розвинулась і покращилась. Спочатку ChatGPT був безкоштовною службою, яка пропонувала детальні текстові відповіді. Тепер є ChatGPT Plus, який включає ChatGPT-4. Ця оновлена версія була навчена на більшій кількості даних, дає менше неправильних відповідей і краще розуміє складні інструкції.
Одна з найбільших оновлень полягає в тому, що ChatGPT тепер може взаємодіяти різними способами – він може слухати, говорити і навіть обробляти зображення. Це означає, що ви можете розмовляти з ним через його мобільний додаток і показувати йому картинки, щоб отримувати відповіді. Ці зміни відкрили нові можливості для штучного інтелекту і змінили те, як люди сприймають і думають про роль штучного інтелекту в нашому житті.
Від початку як технічної демонстрації до свого поточного статусу великого гравця в технологічному світі, шлях ChatGPT досить вражаючий. Спочатку він був розглянутий як спосіб тестування і покращення технологій шляхом отримання відгуку від громадськості. Але він швидко став важливою частиною сцени штучного інтелекту. Цей успіх показує, наскільки ефективним є тонке налаштування великих мовних моделей (LLM) з використанням як наглядового навчання, так і відгуку від людей. В результаті ChatGPT може обробляти широкий спектр запитів і завдань.
Гонка за розробку найбільш здатних і універсальних систем штучного інтелекту призвела до поширення як відкритих, так і пропріетарних моделей, подібних до ChatGPT. Для розуміння їх загальних можливостей потрібно комплексне тестування по широкому спектру завдань. Ця секція досліджує ці тести, проливаючи світло на те, як різні моделі, включаючи ChatGPT, порівняються одна з одною.
Оцінка LLM: Бенчмарки
- MT-Bench: Цей бенчмарк тестиє багаторазові розмови і виконання інструкцій у восьми доменах: написанні, рольових іграх, витягуванні інформації, розумінні, математиці, програмуванні, наукових знаннях і гуманітарних науках. Потужніші LLM, такі як GPT-4, використовуються як оцінювачі.
- AlpacaEval: На основі набору оцінювання AlpacaFarm, цей автоматичний оцінювач LLM оцінює моделі порівняно з відповідями від просунутих LLM, таких як GPT-4 і Claude, розрахуючи рівень перемоги кандидатських моделей.
- Відкритий лідерборд LLM: Використовуючи Language Model Evaluation Harness, цей лідерборд оцінює LLM на семи ключових бенчмарках, включаючи завдання з розумінням і загальних знань, в умовах нульового і декількох зразків.
- BIG-bench: Цей колаборативний бенчмарк охоплює понад 200 нових мовних завдань, охоплюючи різноманітний спектр тем і мов. Він спрямований на дослідження можливостей LLM і передбачення їх майбутніх можливостей.
- ChatEval: Фреймворк багаторазової дискусії, який дозволяє командам автономно обговорювати і оцінювати якість відповідей від різних моделей на відкриті питання і традиційні завдання генерації природної мови.
Порівняльна продуктивність
У термінах загальних бенчмарків відкриті LLM показали помітний прогрес. Llama-2-70B, наприклад, досягла вражаючих результатів, особливо після тонкого налаштування з інструкційними даними. Її варіант, Llama-2-chat-70B, виділився в AlpacaEval з рівнем перемоги 92,66%, перевершивши GPT-3.5-turbo. Однак GPT-4 залишається лідером з рівнем перемоги 95,28%.
Zephyr-7B, менша модель, продемонструвала можливості, порівнянні з більшіми 70B LLM, особливо в AlpacaEval і MT-Bench. Тоді як WizardLM-70B, тонко налаштована з різноманітними інструкційними даними, набула最高 рівень серед відкритих LLM на MT-Bench. Однак вона все ще відстає від GPT-3.5-turbo і GPT-4.
Цікавим вступом стала GodziLLa2-70B, яка досягла конкурентного результату на Відкритому лідерборді LLM, демонструючи потенціал експериментальних моделей, що поєднують різноманітні набори даних. Подібним чином, Yi-34B, розроблена з нуля, виділилася результатами, порівнянними з GPT-3.5-turbo, і лише трохи відстала від GPT-4.
UltraLlama, з її тонким налаштуванням на різноманітних і високоякісних даних, дорівнялась до GPT-3.5-turbo в запропонованих бенчмарках і навіть перевершувала її в областях світових і професійних знань.
Масштабування: Зростання гігантських LLM
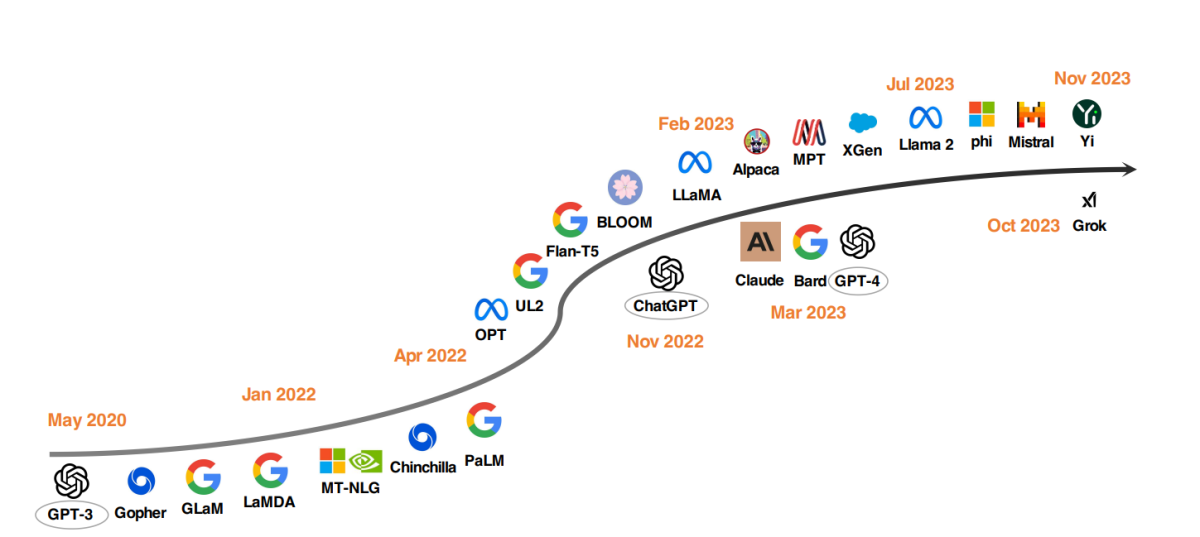
Найкращі моделі LLM з 2020 року
Помітною тенденцією у розвитку LLM став масштабування параметрів моделей. Моделі, такі як Gopher, GLaM, LaMDA, MT-NLG і PaLM, розширили межі, створивши моделі з до 540 мільярдів параметрів. Ці моделі продемонстрували виняткові можливості, але їх закрита природа обмежила їхнє ширше застосування. Це обмеження сприяло інтересу до розробки відкритих LLM, тенденції, яка набирає імпульсу.
Паралельно з масштабуванням розмірів моделей дослідники досліджували альтернативні стратегії. Замість простого збільшення моделей вони зосередились на покращенні попереднього навчання менших моделей. Прикладами цього є Chinchilla і UL2, які продемонстрували, що більше не завжди краще; розумніші стратегії можуть привести до ефективних результатів. Крім того, велика увага приділяється інструкційному налаштуванню мовних моделей, з проектами, такими як FLAN, T0 і Flan-T5, які зробили значний внесок у цю область.
Каталізатор ChatGPT
Введення OpenAI у ChatGPT позначило переломний момент у дослідженнях NLP. Для конкуренції з OpenAI компанії, такі як Google і Anthropic, запустили свої власні моделі, Bard і Claude, відповідно. Хоча ці моделі показують порівняльну продуктивність з ChatGPT у багатьох завданнях, вони все ще відстають від останньої моделі OpenAI, GPT-4. Успіх цих моделей в першу чергу пояснюється technikою навчання з підкріпленням від людського відгуку (RLHF), технікою, яка отримує збільшену увагу для подальшого покращення.
Чутки і спекуляції навколо Q* (Q-Star) OpenAI
Нещодавні повідомлення свідчать, що дослідники в OpenAI можуть досягти суттєвого прогресу в штучному інтелекті з розробкою нової моделі, названої Q* (пронUNCED Q зірка). Нібито, Q* має здатність виконувати завдання рівня початкової школи з математики, досягнення, яке сприяло дискусіям серед експертів про її потенціал як етапу на шляху до штучного загального інтелекту (AGI). Хоча OpenAI не прокоментувала ці повідомлення, чутки про можливості Q* викликали значний інтерес і спекуляції в соціальних мережах і серед ентузіастів штучного інтелекту.
Розробка Q* є суттєвою, оскільки існуючі мовні моделі, такі як ChatGPT і GPT-4, хоча й здатні до деяких математичних завдань, не особливо добре справляються з ними надійно. Виклик полягає в тому, щоб штучні моделі не тільки розпізнавали закономірності, як вони роблять зараз через глибоке навчання і трансформери, але й розуміли абстрактні концепції. Математика, будучи бенчмарком для розуміння, вимагає від штучної моделі планування і виконання декількох кроків, демонструючи глибоке розуміння абстрактних концепцій. Ця здатність буде суттєвим стрибком у можливостях штучного інтелекту, потенційно розширюючи його застосування за межі математики до інших складних завдань.
Однак експерти застерігають проти надмірного гіпування цього розвитку. Хоча система штучного інтелекту, яка надійно розв’язує математичні завдання, буде вражаючим досягненням, це не обов’язково означає появу суперінтелектуального штучного інтелекту або AGI. Поточні дослідження штучного інтелекту, включаючи зусилля OpenAI, зосередились на елементарних завданнях, з різним ступенем успіху в більш складних завданнях.
Потенційні застосування таких досягнень, як Q*, є величезними, від персоналізованого навчання до допомоги в наукових дослідженнях і інженерії. Однак також важливо керувати очікуваннями і визнавати обмеження і питання безпеки, пов’язані з такими досягненнями. Обставини щодо ризиків штучного інтелекту, фундаментальної проблеми OpenAI, залишаються актуальними, особливо коли системи штучного інтелекту починають взаємодіяти більше з реальним світом.
Рух відкритих LLM
Для підтримки відкритих досліджень LLM Meta випустила серію моделей Llama, сприявши хвилі нових розробок на основі Llama. Це включає моделі, тонко налаштовані з інструкційними даними, такими як Alpaca, Vicuna, Lima і WizardLM. Дослідження також розгалужуються на підвищення можливостей агентів, логічного розуміння і моделювання довгих контекстів у рамках Llama.
Крім того, існує зростаюча тенденція до розробки потужних LLM з нуля, з проектами, такими як MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok і Yi. Ці зусилля відображають зобов’язання демократизувати можливості закритих LLM, роблячи просунуті інструменти штучного інтелекту більш доступними і ефективними.
Вплив ChatGPT і відкритих моделей на охорону здоров’я
Ми розглядаємо майбутнє, де LLM допоможуть у клінічному обліку, заповненні форм для відшкодування, і підтримці лікарів у діагностиці і плануванні лікування. Це привернуло увагу як технологічних гігантів, так і закладів охорони здоров’я.
Обговорення Microsoft з Epic, провідним постачальником програмного забезпечення для електронних медичних записів, сигналізує про інтеграцію LLM у охорону здоров’я. Ініціативи вже реалізуються в UC San Diego Health і Stanford University Medical Center. Подібним чином, партнерство Google з Mayo Clinic і запуск Amazon Web Services HealthScribe, служби клінічної документації штучного інтелекту, позначають суттєві кроки в цьому напрямку.
Однак ці швидкі розгортання викликають занепокоєння щодо передачі контролю над медициною корпоративним інтересам. Пропріетарна природа цих LLM робить їх важкими для оцінки. Їхня можливе модифікація або припинення заради прибутковості могла б компрометувати догляд за пацієнтами, конфіденційність і безпеку.
Терміново необхідний відкритий і інклюзивний підхід до розробки LLM для охорони здоров’я. Заклади охорони здоров’я, дослідники, клініцисти і пацієнти повинні співпрацювати глобально, щоб створити відкриті LLM для охорони здоров’я. Цей підхід, подібний до Trillion Parameter Consortium, дозволить об’єднати обчислювальні, фінансові ресурси і експертизу.












