Штучний інтелект
AudioSep : Відокремте все, що ви описуєте
LASS або Language-queried Audio Source Separation – це новий парадигма для CASA або Computational Auditory Scene Analysis, який спрямований на відокремлення цільового звуку від заданої суміші аудіо за допомогою природної мови запит, який забезпечує природний, але масштабований інтерфейс для цифрових аудіо завдань та застосунків. Хоча рамки LASS суттєво покращились за останні кілька років у досягненні бажаної продуктивності на конкретних аудіо джерелах, таких як музичні інструменти, вони не можуть відокремити цільовий аудіо в відкритому домені.
AudioSep, є фундаментальною моделлю, яка спрямована на вирішення поточних обмежень рамок LASS, забезпечуючи відокремлення цільового аудіо за допомогою природної мови запитів. Розробники моделі AudioSep тренували модель широко на великомасштабних багатомодальних наборах даних та оцінили продуктивність рамки на широкому масиві аудіо завдань, включаючи розділення музичних інструментів, розділення аудіо подій та покращення мови серед багатьох інших. Початкова продуктивність AudioSep задовольняє бенчмаркам, оскільки демонструє вражаючі можливості нульової навчальної здатності та забезпечує сильну аудіо роздільну продуктивність.
У цій статті ми будемо глибше вивчати роботу рамки AudioSep, оскільки ми будемо оцінювати архітектуру моделі, набори даних, використані для тренування та оцінки, та основні концепції, залучені до роботи моделі AudioSep. Тому почнімо з базового введення до рамки CASA.
CASA, USS, QSS, LASS Фреймворки : Фундамент для AudioSep
CASA або Computational Auditory Scene Analysis фреймворк – це фреймворк, який використовується розробниками для створення систем машинного слуху, які мають можливість сприймати складні звукові середовища подібно до того, як люди сприймають звук за допомогою своїх слухових систем. Звукова роздільна здатність, з особливим акцентом на цільовій звуковій роздільній здатності, є фундаментальною областю дослідження у рамках фреймворку CASA, і вона спрямована на вирішення проблеми “коктейльної партії” або розділення реальних аудіо записів від окремих аудіо джерел чи файлів. Важливість звукової роздільної здатності можна віднести головним чином до її широких застосунків, включаючи розділення музичних джерел, розділення аудіо джерел, покращення мови, ідентифікацію цільового звуку та багато іншого.
Більшість робіт щодо звукової роздільної здатності, виконаних у минулому, обертаються головним чином навколо розділення одного чи декількох аудіо джерел, таких як музичне розділення чи мовне розділення. Нова модель під назвою USS або Universal Sound Separation спрямована на розділення довільних звуків у реальних аудіо записах. Однак це складне та обмежувальне завдання розділити кожне звукове джерело від аудіо суміші головним чином через широкий масив різних звукових джерел, що існують у світі, що є основною причиною, чому метод USS не є життєздатним для реальних застосунків, що працюють в реальному часі.
Життєздатною альтернативою методу USS є QSS або Query-based Sound Separation метод, який спрямований на розділення окремого чи цільового звукового джерела від аудіо суміші на основі певного набору запитів. Завдяки цьому фреймворк QSS дозволяє розробникам та користувачам витягувати бажані джерела аудіо з суміші на основі їхніх вимог, що робить метод QSS більш практичним рішенням для цифрових реальних застосунків, таких як мультимедійне редагування вмісту чи аудіо редагування.
Крім того, розробники недавно запропонували розширення фреймворку QSS, фреймворк LASS або Language-queried Audio Source Separation, який спрямований на розділення довільних джерел звуку від аудіо суміші за допомогою природної мови описів цільового аудіо джерела.既然 фреймворк LASS дозволяє користувачам витягувати цільові аудіо джерела за допомогою набору природної мови інструкцій, він може стати потужним інструментом із широкими застосунками у цифрових аудіо застосунках. Коли порівнюється з традиційними аудіо-запитувальними чи візуально-запитувальними методами, використання природної мови інструкцій для аудіо роздільної здатності пропонує більшу ступінь переваги, оскільки додає гнучкість та робить придбання запитувальної інформації значно легшим та зручним. Крім того, коли порівнюється з міткою запитувальної аудіо роздільної здатності фреймворками, які використовують попередньо визначений набір інструкцій чи запитів, фреймворк LASS не обмежує кількість входящих запитів та має гнучкість бути узагальненим до відкритого домену безшовно.
Спочатку фреймворк LASS залежить від наглядового навчання, при якому модель тренується на наборі мітованих аудіо-текстових пар даних. Однак основною проблемою цього підходу є обмежена доступність анотованих та мітованих аудіо-текстових даних. Для зменшення залежності фреймворку LASS від анотованих аудіо-текстових міток дані моделі тренуються за допомогою багатомодального наглядового навчання підходу. Основною метою використання багатомодального наглядового підходу є використання багатомодального контрастного попереднього тренування моделей, таких як CLIP або Contrastive Language Image Pre Training модель, як запитувального кодувальника для фреймворку.既然 CLIP фреймворк має можливість вирівнювати текстові вкладення з іншими модальностями, такими як аудіо чи зір, це дозволяє розробникам тренувати моделі LASS за допомогою даних-багатих модальностей та дозволяє інтерферувати з текстовими даними у нульовій установці. Поточні фреймворки LASS jedoch використовують малих масштабів набори даних для тренування, та застосунки фреймворку LASS по сотням потенційних доменів ще не були досліджені.
Для вирішення поточних обмежень, з якими стикаються фреймворки LASS, розробники ввели AudioSep, фундаментальну модель, яка спрямована на розділення звуку від аудіо суміші за допомогою природної мови описів. Поточна увага для AudioSep полягає у розробці попередньо тренованої моделі звукової роздільної здатності, яка використовує існуючі великомасштабні багатомодальні набори даних для забезпечення узагальнення моделей LASS у відкритому домені застосунках. Під час підсумовування, модель AudioSep – це: ” Фундаментальна модель для універсальної звукової роздільної здатності у відкритому домені за допомогою природної мови запитів чи описів, тренована на великомасштабних аудіо- та багатомодальних наборах даних “.
AudioSep : Ключові компоненти та архітектура
Архітектура фреймворку AudioSep складається з двох ключових компонентів: текстового кодувальника та моделі розділення.
Текстовий кодувальник
Фреймворк AudioSep використовує текстовий кодувальник моделі CLIP або Contrastive Language Image Pre Training модель або моделі CLAP або Contrastive Language Audio Pre Training модель для витягування текстових вкладень у природній мові запит. Вхідний текстовий запит складається з послідовності ” N ” токенів, який потім обробляється текстовим кодувальником для витягування текстових вкладень для заданого вхідного мовного запиту. Текстовий кодувальник використовує стек трансформерних блоків для кодування вхідних текстових токенів, а вихідні представлення агрегуються після проходження через трансформерні шари, що призводить до розробки D-мірного векторного представлення з фіксованою довжиною, де D відповідає розмірам моделей CLAP чи CLIP, тоді як текстовий кодувальник заморожений під час тренування періоду.
Модель CLIP попередньо тренується на великомасштабному наборі даних зображень-текстових пар даних за допомогою контрастного навчання, що є основною причиною, чому її текстовий кодувальник вивчає відображення текстових описів на семантичному просторі, який також спільний для візуальних представлень. Перевага, яку AudioSep отримує від використання текстового кодувальника CLIP, полягає в тому, що вона тепер може масштабуватися або тренувати модель LASS з ненаданих аудіо-візуальних даних, використовуючи візуальні вкладення як альтернативу, що дозволяє тренувати моделі LASS без вимог анотованих або мітованих аудіо-текстових даних.
Модель CLAP працює подібно до моделі CLIP та використовує контрастну навчальну мету, оскільки вона використовує текстовий та аудіо кодувальник для зв’язку аудіо та мови, що дозволяє текстові та аудіо описи на аудіо-текстовому латентному просторі, поєднані разом.
Модель розділення
Фреймворк AudioSep використовує частотно-доменну модель ResUNet, яка подається суміші аудіо кліпів як роздільна основа для фреймворку. Фреймворк працює шляхом застосування STFT або короткочасного Фур’є-трасформування до sóngової форми для витягування комплексного спектрограми, величини спектрограми та фази X. Модель потім слідує相同ній установці та будує кодувальник-декодувальник мережу для обробки величини спектрограми.
Модель ResUNet кодувальник-декодувальник мережа складається з 6 залишкових блоків, 6 декодувальних блоків та 4 бутербродних блоків. Спектрограма в кожному кодувальникові блоці використовує 4 залишкові конволюційні блоки для знизування себе у бутербродну особливість, тоді як декодувальні блоки використовують 4 залишкові деконволюційні блоки для отримання роздільних компонентів шляхом апсамплінгу особливостей. Після цього кожний з кодувальникових блоків та його відповідних декодувальних блоків встановлює пропускну зв’язок, яка працює на相同ній апсамплінговій чи знизувальній швидкості. Залишковий блок фреймворку складається з 2 Leaky-ReLU активаційних шарів, 2 шарів нормалізації батчу та 2 шарів CNN, а крім того, фреймворк вводить додатковий залишковий шорткат, який з’єднує вхід та вихід кожного окремого залишкового блоку. Модель ResUNet приймає комплексну спектрограму X як вхід, та виробляє величину маску M як вихід з фазовим залишком, який умовно контролює величину масштабування та обертання кута спектрограми. Розділена комплексна спектрограма може бути витягнута шляхом множення передбаченої величини маски та фазового залишку з STFT (короткочасним Фур’є-трасформуванням) суміші.

У своєму фреймворку AudioSep використовує FiLm або Feature-wise Linearly модульований шар для зв’язку моделі розділення та текстового кодувальника після розгортання конволюційних блоків у ResUNet.
Тренування та втрата
Під час тренування моделі AudioSep розробники використовують метод гучної аугментації, та тренують фреймворк AudioSep з кінцем до кінця за допомогою L1-функції втрат між справжнім та передбаченим хвилями.
Набори даних та бенчмарки
Як згадувалося у попередніх розділах, AudioSep є фундаментальною моделлю, яка спрямована на вирішення поточної залежності моделей LASS від анотованих аудіо-текстових пар даних. Модель AudioSep тренується на широкому масиві наборів даних для забезпечення багатомодальної навчальної здатності, та ось детальний опис набору даних та бенчмарків, використаних розробниками для тренування фреймворку AudioSep.
AudioSet
AudioSet – це слабко-мітований великомасштабний аудіо набір даних, який складається з понад 2 мільйонів 10-секундних аудіо кліпів, витягнутих безпосередньо з YouTube. Кожен аудіо кліп у наборі даних AudioSet категоризується за відсутністю чи присутністю звукових класів без конкретних деталей часу звукових подій. Набір даних AudioSet має понад 500 різних аудіо класів, включаючи природні звуки, людські звуки, звуки транспорту та багато іншого.
VGGSound
Набір даних VGGSound – це великомасштабний візуально-аудіо набір даних, який, подібно до AudioSet, був витягнутий безпосередньо з YouTube, та містить понад 200 000 відео кліпів, кожний з яких має тривалість 10 секунд. Набір даних VGGSound категоризується у понад 300 звукових класів, включаючи людські звуки, природні звуки, пташині звуки та багато іншого. Використання набору даних VGGSound забезпечує, що об’єкт, відповідальний за генерацію цільового звуку, також описується у відповідному візуальному кліпі.
AudioCaps
AudioCaps – це найбільший публічний аудіо описувальний набір даних, який складається з понад 50 000 10-секундних аудіо кліпів, витягнутих з набору даних AudioSet. Дані у AudioCaps розділені на три категорії: тренувальні дані, тестові дані та валідувальні дані, та аудіо кліпи анотовані людьми природними мовними описами за допомогою платформи Amazon Mechanical Turk. Варто зазначити, що кожен аудіо кліп у тренувальному наборі даних має один опис, тоді як дані у тестовому та валідувальному наборах мають по 5 справжніх описів.
ClothoV2
ClothoV2 – це аудіо описувальний набір даних, який складається з кліпів, витягнутих з платформи FreeSound, та, подібно до AudioCaps, кожен аудіо кліп анотований людьми природними мовними описами за допомогою платформи Amazon Mechanical Turk.
WavCaps
Подібно до AudioSet, WavCaps – це слабко-мітований великомасштабний аудіо набір даних, який складається з понад 400 000 аудіо кліпів з описами, та загальним часом приблизно 7568 годин тренувальних даних. Аудіо кліпи у наборі даних WavCaps витягнуті з широкого масиву аудіо джерел, включаючи BBC Sound Effects, AudioSet, FreeSound, SoundBible та багато іншого.

Деталі тренування
Під час фази тренування модель AudioSep випадково вибірково два аудіо сегменти з двох різних аудіо кліпів з тренувального набору даних, та потім змішує їх разом для створення тренувальної суміші, де довжина кожного аудіо сегменту становить близько 5 секунд. Модель потім витягує комплексну спектрограму з хвиляової форми сигналу за допомогою Hann вікна розміру 1024 з кроком 320.
Модель потім використовує текстовий кодувальник моделей CLIP/CLAP для витягування текстових вкладень з текстовим наглядом за замовчуванням для AudioSep. Для моделі розділення фреймворк AudioSep використовує шар ResUNet, який складається з 30 шарів, 6 кодувальникових блоків та 6 декодувальних блоків, подібно до архітектури, використаної у фреймворку універсальної звукової роздільної здатності. Крім того, кожний кодувальниковий блок має два конволюційні шари з розміром ядра 3×3, з кількістю виходних особливостей кодувальникових блоків, рівним 32, 64, 128, 256, 512 та 1024 відповідно. Декодувальні блоки мають симетрію з кодувальниковими блоками, та розробники застосовують оптимізатор Adam для тренування моделі AudioSep з розміром батчу 96.
Результати оцінки
На бачених наборах даних
Наступна фігура порівнює продуктивність фреймворку AudioSep на бачених наборах даних під час фази тренування, включаючи тренувальні набори даних. Нижче фігура представляє результати оцінки бенчмарків фреймворку AudioSep при порівнянні з базовими системами, включаючи моделі покращення мови, LASS та CLIP. Модель AudioSep з текстовим кодувальником CLIP представлена як AudioSep-CLIP, тоді як модель AudioSep з текстовим кодувальником CLAP представлена як AudioSep-CLAP.

Як можна побачити на фігурі, фреймворк AudioSep працює добре при використанні аудіо описів чи текстових міток як вхідних запитів, та результати вказують на вищу продуктивність фреймворку AudioSep при порівнянні з попередніми бенчмарками LASS та аудіо-запитувальними моделями звукової роздільної здатності.
На небачених наборах даних
Для оцінки продуктивності AudioSep у нульовій установці розробники продовжили оцінювати продуктивність на небачених наборах даних, та фреймворк AudioSep демонструє вражаючу роздільну продуктивність у нульовій установці, та результати представлені на фігурі нижче.

Крім того, нижче зображення показує результати оцінки моделі AudioSep проти Voicebank-Demand покращення мови.

Оцінка фреймворку AudioSep вказує на сильну та бажану продуктивність на небачених наборах даних у нульовій установці, та тим самим робить можливим виконання завдань звукової обробки на нових розподілах даних.
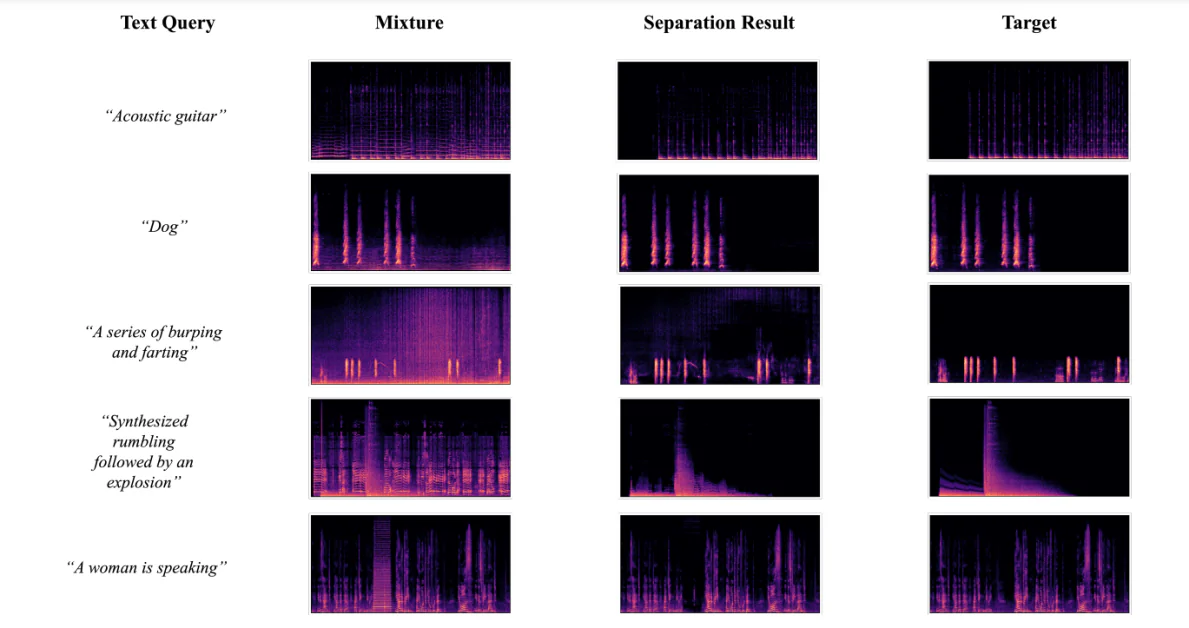
Візуалізація результатів розділення
Нижче фігура показує результати, отримані при використанні фреймворку AudioSep-CLAP для візуалізації спектрограм для справжніх цільових аудіо джерел, аудіо сумішей та розділених аудіо джерел за допомогою текстових запитів різноманітних аудіо чи звуків. Результати дозволили розробникам спостерігати, що шаблон спектрограми розділеного джерела близький до джерела справжнього, що ще більше підтримує об’єктивні результати, отримані під час експериментів.
Порівняння текстових запитів
Розробники оцінюють продуктивність AudioSep-CLAP та AudioSep-CLIP на AudioCaps Mini, та розробники використовують мітки подій AudioSet, описи AudioCaps та переанотовані природні мовні описи для вивчення впливу різних запитів, та нижче фігура показує приклад AudioCaps Mini в дії.

Висновок
AudioSep – це фундаментальна модель, яка розроблена для відкритого домену універсальної звукової роздільної здатності, яка використовує природну мову описів для аудіо розділення. Як спостерігалося під час оцінки, фреймворк AudioSep能够 виконувати нульову та ненаглядну навчальну здатність безшовно за допомогою аудіо описів чи текстових міток як запитів. Результати та оцінка продуктивності AudioSep вказують на сильну продуктивність, яка перевершує поточний стан мистецтва звукової роздільної здатності фреймворків, таких як LASS, та вона може бути здатною вирішити поточні обмеження популярних фреймворків звукової роздільної здатності.












