ปัญญาประดิษฐ์
แอนดรูว์ เอ็นจี วิพากษ์วิจารณ์วัฒนธรรมการปรับแต่งมากเกินไปในเครื่องมือการเรียนรู้ของเครื่อง
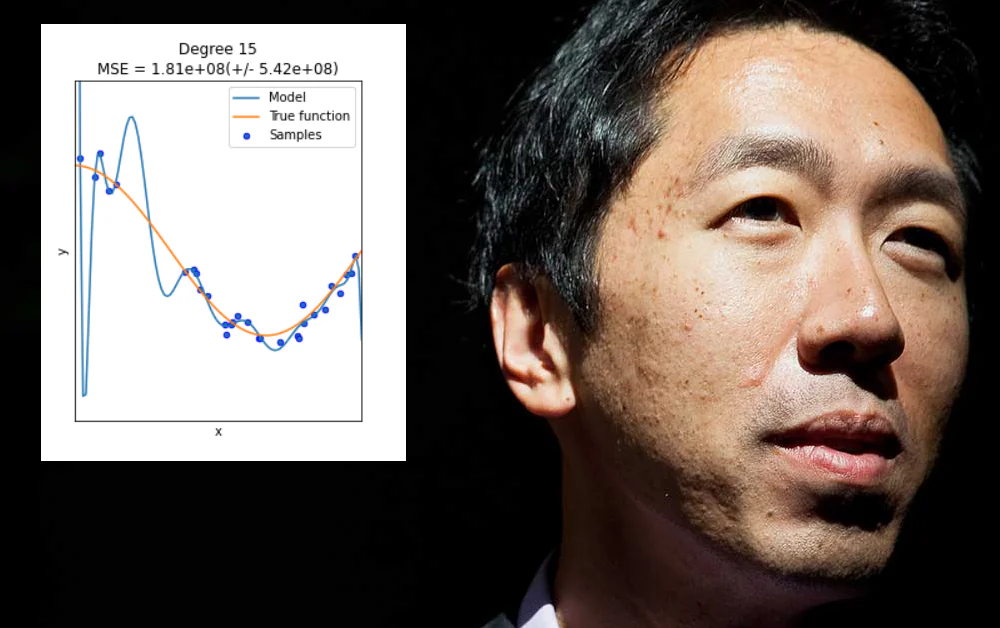
แอนดรูว์ เอ็นจี หนึ่งในเสียงที่มีอิทธิพลมากที่สุดในเครื่องมือการเรียนรู้ของเครื่องในช่วงสิบปีที่ผ่านมา ปัจจุบันกำลังแสดงความกังวลเกี่ยวกับระดับที่ภาคส่วนเน้นย้ำนวัตกรรมในโครงสร้างแบบจำลองมากกว่าข้อมูล – และโดยเฉพาะอย่างยิ่ง ระดับที่ภาคส่วนอนุญาตให้ผลลัพธ์ที่ “ปรับแต่งมากเกินไป” ถูกพรรณนาว่าเป็นโซลูชันหรือความก้าวหน้าทั่วไป
นี่คือการวิพากษ์วิจารณ์ที่กว้างขวางเกี่ยวกับวัฒนธรรมเครื่องมือการเรียนรู้ของเครื่องในปัจจุบัน ซึ่งมาจากหนึ่งในผู้มีอำนาจสูงสุดของภาคส่วน และมีผลกระทบต่อความมั่นใจในภาคส่วนที่ถูกครอบงำโดยความกลัวเกี่ยวกับการล่มสลายครั้งที่สามของความเชื่อมั่นในธุรกิจในการพัฒนา AI ในช่วงหกสิบปี
เอ็นจี เป็นศาสตราจารย์ที่มหาวิทยาลัยสแตนฟอร์ด และเป็นหนึ่งในผู้ก่อตั้ง deeplearning.ai และในเดือนมีนาคมได้ตีพิมพ์ missive บนเว็บไซต์ขององค์กรที่รวม การกล่าวสุนทรพจน์ ของเขาในเดือนกุมภาพันธ์เป็นข้อแนะนำหลักๆ สองประการ
ประการแรก คือชุมชนการวิจัยควรหยุดพูดถึงข้อร้องเรียนที่ว่าการทำความสะอาดข้อมูลแทน 80% ของความท้าทายในเครื่องมือการเรียนรู้ของเครื่อง และเริ่มทำหน้าที่พัฒนา MLOps ที่มีประสิทธิภาพและแนวปฏิบัติ
ประการที่สอง คือควรย้ายออกจาก “ชัยชนะที่ง่าย” ที่สามารถทำได้โดยการปรับแต่งข้อมูลให้เข้ากับแบบจำลองเครื่องมือการเรียนรู้ของเครื่อง เพื่อให้แบบจำลองทำงานได้ดี แต่ล้มเหลวในการสร้างแบบจำลองที่สามารถใช้งานได้ทั่วไป
การยอมรับความท้าทายของโครงสร้างข้อมูลและคัดเลือก
“มุมมองของฉัน” เอ็นจีเขียน “คือว่าหาก 80% ของงานของเราคือขั้นตอนการเตรียมข้อมูล ดังนั้นการรับรองคุณภาพข้อมูลจึงเป็นงานที่สำคัญของทีมเครื่องมือการเรียนรู้ของเครื่อง”
เขายังคงเขียนต่อไป:
“แทนที่จะพึ่งพานักวิศวกรที่จะพบวิธีที่ดีที่สุดในการปรับปรุงชุดข้อมูล ฉันหวังว่าเราจะสามารถพัฒนา MLOps ที่ช่วยให้การสร้างระบบ AI รวมถึงการสร้างชุดข้อมูลที่มีคุณภาพสูงเป็นกระบวนการที่ทำซ้ำและเป็นระบบ
“MLOps เป็นสาขาที่ยังใหม่ และคนต่างๆ นิยามมันในแบบที่แตกต่างกัน แต่ฉันคิดว่าหลักการสำคัญที่สุดของ MLOps คือการรับรองการไหลของข้อมูลที่มีคุณภาพสูงและสม่ำเสมอใน tất cảขั้นตอนของโครงการ ซึ่งจะช่วยให้หลายโครงการดำเนินไปได้อย่างราบรื่น”
ในระหว่างการกล่าวสุนทรพจน์ทาง Zoom ใน การถาม-ตอบ สดๆ ที่จัดขึ้นที่สิ้นสุดเดือนเมษายน เอ็นจีกล่าวถึงปัญหาการใช้งานที่ไม่เพียงพอในระบบวิเคราะห์เครื่องมือการเรียนรู้ของเครื่องสำหรับการรังสีวิทยา:
“เมื่อเรารวบรวมข้อมูลจากโรงพยาบาลสแตนฟอร์ด แล้วเราทดสอบและฝึกอบรมบนข้อมูลจากโรงพยาบาลเดียวกัน เราสามารถตีพิมพ์เอกสารวิจัยที่แสดงให้เห็นว่า [อัลกอริทึม] เหล่านี้สามารถเทียบเท่ากับนักวิจัยรังสีวิทยาของมนุษย์ในการระบุเงื่อนไขบางอย่างได้”
“…[เมื่อ] คุณนำแบบจำลอง AI เหล่านี้ไปใช้กับโรงพยาบาลเก่าๆ ที่อยู่ใกล้ๆ กัน โดยใช้เครื่องมือเก่าและผู้เทคนิคใช้โพรโทคอลการถ่ายภาพที่แตกต่างกันเล็กน้อย ข้อมูลจะเปลี่ยนแปลงไปและทำให้ประสิทธิภาพของระบบ AI ลดลงอย่างมาก ในทางกลับกัน นักวิจัยรังสีวิทยาของมนุษย์สามารถเดินไปที่โรงพยาบาลเก่าๆ ได้และทำงานได้ดี”
การไม่ระบุรายละเอียดไม่ใช่คำตอบ
การปรับแต่งมากเกินไปเกิดขึ้นเมื่อแบบจำลองเครื่องมือการเรียนรู้ของเครื่องถูกออกแบบมาเพื่อให้เข้ากับข้อมูลที่เฉพาะเจาะจง (หรือวิธีการจัดรูปแบบข้อมูล) ซึ่งอาจเกี่ยวข้องกับการกำหนดค่าให้ผลลัพธ์ที่ดีจากชุดข้อมูลนั้น แต่ไม่สามารถ “สร้างแบบจำลองทั่วไป” ได้บนข้อมูลอื่นๆ
ในหลายกรณี พารามิเตอร์เหล่านี้ถูกกำหนดโดย “ส่วนประกอบที่ไม่ใช่ข้อมูล” ของชุดข้อมูลการฝึกอบรม เช่น ความละเอียดของข้อมูลที่รวบรวมหรือลักษณะเฉพาะอื่นๆ ที่ไม่ได้รับประกันว่าจะเกิดขึ้นอีกครั้งในชุดข้อมูลที่ตามมา
แม้ว่ามันจะดี แต่การปรับแต่งมากเกินไปไม่ใช่ปัญหาที่สามารถแก้ไขได้โดยการขยายขอบเขตหรือความยืดหยุ่นของโครงสร้างข้อมูลหรือการออกแบบแบบจำลองโดยไม่จำเป็นต้องมีลักษณะที่มีประโยชน์และมีผลกระทบอย่างกว้างขวางที่จะทำงานได้ดีบนข้อมูลที่หลากหลาย – ซึ่งเป็นความท้าทายที่ยากขึ้น
โดยทั่วไป การ “ไม่ระบุรายละเอียด” นี้จะนำไปสู่ปัญหาที่เอ็นจีได้กล่าวถึงเมื่อเร็วๆ นี้ ซึ่งแบบจำลองเครื่องมือการเรียนรู้ของเครื่องล้มเหลวบนข้อมูลที่ไม่เคยเห็นมาก่อน แต่ในกรณีนี้ แบบจำลองล้มเหลวไม่ใช่เพราะข้อมูลหรือการรูปแบบข้อมูลแตกต่างจากชุดข้อมูลการฝึกอบรมที่ปรับแต่งมากเกินไป แต่เพราะแบบจำลองมีความยืดหยุ่นมากเกินไป
ปลายปี 2020 เอกสารวิจัย การไม่ระบุรายละเอียดนำเสนอความท้าทายสำหรับความน่าเชื่อถือในเครื่องมือการเรียนรู้ของเครื่องสมัยใหม่ ได้วิพากษ์วิจารณ์แนวปฏิบัตินี้อย่างรุนแรง และมีนักวิจัยและนักวิทยาศาสตร์เครื่องมือการเรียนรู้ของเครื่องมากกว่า 40 คนจาก Google และ MIT รวมถึงสถาบันอื่นๆ
เอกสารวิจัยวิพากษ์วิจารณ์ “การเรียนรู้ทางลัด” และสังเกตเห็นว่าแบบจำลองที่ไม่ระบุรายละเอียดสามารถหลุดออกไปในทางที่ไม่คาดคิดตามจุดเริ่มต้นของการฝึกอบรมแบบจำลองที่กำหนดโดยการสุ่ม ผู้ร่วมให้ข้อมูลสังเกตเห็นว่า:
“เราได้เห็นว่าการไม่ระบุรายละเอียดเป็นสิ่งที่พบได้ทั่วไปในเครื่องมือการเรียนรู้ของเครื่องในทางปฏิบัติในหลายโดเมน โดยแท้จริงแล้ว เนื่องจากการไม่ระบุรายละเอียด ด้านที่สำคัญของการตัดสินใจจึงถูกกำหนดโดยตัวเลือกที่ไม่จำเป็น เช่น ตัวเลือกสุ่มที่ใช้ในการเริ่มต้นการฝึกอบรม”
ผลกระทบทางเศรษฐกิจของการเปลี่ยนแปลงวัฒนธรรม
尽管มีประสบการณ์ทางวิชาการ เอ็นจีไม่ใช่นักวิชาการที่ไม่มีประสบการณ์ในอุตสาหกรรม แต่มีประสบการณ์ระดับสูงในอุตสาหกรรมในฐานะผู้ร่วมก่อตั้ง Google Brain และ Coursera อดีตหัวหน้านักวิทยาศาสตร์ด้าน Big Data และ AI ที่ Baidu และผู้ก่อตั้ง Landing AI ซึ่งบริหารจัดการเงิน 175 ล้านเหรียญสหรัฐฯ สำหรับสตาร์ทอัพใหม่ๆ ในภาคส่วน
เมื่อเขาพูดว่า “เครื่องมือการเรียนรู้ของเครื่องทั้งหมด ไม่ใช่แค่ในด้านสุขภาพเท่านั้น มีช่องว่างระหว่างการแสดงตัวอย่างและการผลิต” มันถูกตั้งใจให้เป็นเสียงเตือนภัยให้กับภาคส่วนที่มีประวัติที่ไม่แน่นอนและความไม่แน่นอนในระยะยาวในการลงทุน
อย่างไรก็ตาม ระบบเครื่องมือการเรียนรู้ของเครื่องแบบเฉพาะที่ทำงานได้ดีในสถานที่ แต่ล้มเหลวในสถานที่อื่นๆ แสดงถึงการเข้าครอบครองตลาดที่สามารถให้ผลตอบแทนจากการลงทุนในอุตสาหกรรมได้ การนำเสนอ “ปัญหาปรับแต่งมากเกินไป” ในบริบทของอันตรายที่เกิดขึ้นในอาชีพการงานเป็นวิธีการที่ไม่ซื่อสัตย์ในการ “สร้างรายได้” จากการลงทุนขององค์กรในงานวิจัยแบบเปิด และเพื่อสร้างระบบที่มีประสิทธิภาพ แต่ไม่สามารถทำซ้ำได้โดยคู่แข่ง
ไม่ว่าทางเลือกนี้จะทำงานในระยะยาวหรือไม่นั้นขึ้นอยู่กับระดับที่ความก้าวหน้าจริงๆ ในเครื่องมือการเรียนรู้ของเครื่องต้องการการลงทุนที่สูงขึ้นเรื่อยๆ และไม่ว่าความคิดริเริ่มที่มีประสิทธิผลทั้งหมดจะย้ายไปที่ FAANG ใน某种程度เนื่องจากทรัพยากรที่จำเป็นในการโฮสต์และการดำเนินงาน












