AI 101
Vad är förstärkningsinlärning?
Vad är förstärkningsinlärning?
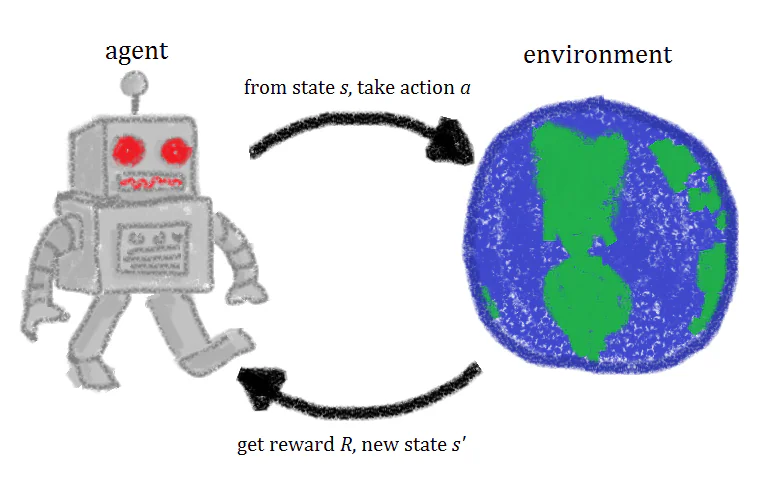
Förstärkningsinlärning är en maskinlärningsteknik som innebär att en artificiell intelligensagent tränas genom upprepning av handlingar och associerade belöningar. En förstärkningsinlärningsagent experimenterar i en miljö, utför handlingar och belönas när rätt handlingar utförs. Med tiden lär sig agenten att utföra handlingar som kommer att maximera dess belöning. Det är en snabb definition av förstärkningsinlärning, men att titta närmare på begreppen bakom förstärkningsinlärning hjälper dig att få en bättre, mer intuitiv förståelse för det.
Begreppet “förstärkningsinlärning” är anpassat från begreppet förstärkning i psykologi. Av den anledningen, låt oss ta en stund att förstå det psykologiska begreppet förstärkning. I den psykologiska meningen, hänvisar begreppet förstärkning till något som ökar sannolikheten för att en viss respons/handling ska inträffa. Detta begrepp om förstärkning är en central idé i teorin om operant betingning, som ursprungligen föreslogs av psykologen B.F. Skinner. I detta sammanhang är förstärkning allt som orsakar att frekvensen av ett visst beteende ökar. Om vi tänker på möjliga förstärkningar för människor, kan dessa vara saker som beröm, en löneförhöjning på jobbet, godis och roliga aktiviteter.
I den traditionella, psykologiska meningen, finns det två typer av förstärkning. Det finns positiv förstärkning och negativ förstärkning. Positiv förstärkning är tillägg av något för att öka ett beteende, som att ge din hund en belöning när den är väluppfostrad. Negativ förstärkning innebär att ta bort en stimulus för att framkalla ett beteende, som att stänga av höga ljud för att locka ut en skygg katt.
Positiv och negativ förstärkning
Positiv förstärkning ökar frekvensen av ett beteende medan negativ förstärkning minskar frekvensen. I allmänhet är positiv förstärkning den vanligaste typen av förstärkning som används i förstärkningsinlärning, eftersom den hjälper modeller att maximera prestationen på en given uppgift. Inte bara det, men positiv förstärkning leder modellen att göra mer hållbara förändringar, förändringar som kan bli bestående mönster och kvarstå under långa perioder.
I kontrast, medan negativ förstärkning också gör ett beteende mer sannolikt att inträffa, används den för att upprätthålla en minimiprestationsstandard snarare än att nå en modells maximala prestation. Negativ förstärkning i förstärkningsinlärning kan hjälpa till att se till att en modell hålls borta från önskvärda handlingar, men den kan inte verkligen göra att en modell utforskar önskvärda handlingar.
Träning av en förstärkningsagent
När en förstärkningsinlärningsagent tränas, finns det fyra olika ingredienser eller tillstånd som används i träningen: initiala tillstånd (Tillstånd 0), nytt tillstånd (Tillstånd 1), handlingar och belöningar.
Tänk att vi tränar en förstärkningsagent att spela ett plattformsspel där AI:s mål är att nå slutet av nivån genom att flytta till höger över skärmen. Det initiala tillståndet i spelet ritas från miljön, vilket innebär att den första ramen i spelet analyseras och ges till modellen. Baserat på denna information måste modellen besluta om en handling.
Under de initiala faserna av träningen är dessa handlingar slumpmässiga, men när modellen förstärks, kommer vissa handlingar att bli mer vanliga. Efter att handlingen har utförts uppdateras spelets miljö och ett nytt tillstånd eller ram skapas. Om handlingen som togs av agenten producerade ett önskvärt resultat, låt oss säga i detta fall att agenten fortfarande är vid liv och inte har träffats av en fiende, ges någon belöning till agenten och det blir mer sannolikt att den gör samma sak i framtiden.
Detta grundläggande system loopas konstant, händer igen och igen, och varje gång försöker agenten lära sig lite mer och maximera sin belöning.
Episodiska kontra kontinuerliga uppgifter
Förstärkningsinlärningsuppgifter kan vanligtvis placeras i en av två olika kategorier: episodiska uppgifter och kontinuerliga uppgifter.
Episodiska uppgifter kommer att utföra inlärnings-/träningsloop och förbättra sin prestation tills vissa slutkriterier är uppfyllda och träningen avslutas. I ett spel kan detta vara att nå slutet av nivån eller falla i en fara som spikar. I kontrast har kontinuerliga uppgifter inga avslutningskriterier, vilket innebär att de i princip tränar för alltid tills ingenjören väljer att avsluta träningen.
Monte Carlo kontra Temporal Difference
Det finns två primära sätt att lära, eller träna, en förstärkningsinlärningsagent. I Monte Carlo-ansatsen levereras belöningar till agenten (dess poäng uppdateras) endast i slutet av träningsEpisoden. För att säga det på ett annat sätt, endast när avslutningsvillkoret träffas lär modellen hur bra den presterade. Den kan sedan använda denna information för att uppdatera och när nästa träningsrunda startas kommer den att svara i enlighet med den nya informationen.
Temporal-difference-metoden skiljer sig från Monte Carlo-metoden på så sätt att värdeestimeringen, eller poängestimeringen, uppdateras under träningsEpisodens gång. Så fort modellen går vidare till nästa tidssteg uppdateras värdena.
Utforskning kontra exploatering
Att träna en förstärkningsinlärningsagent är en balansakt, som innebär att balansera två olika mått: utforskning och exploatering.
Utforskning är handlingen att samla in mer information om den omgivande miljön, medan exploatering är att använda den information som redan är känd om miljön för att tjäna belöningspoäng. Om en agent endast utforskar och aldrig exploaterar miljön, kommer de önskade handlingarna aldrig att utföras. Å andra sidan, om agenten endast exploaterar och aldrig utforskar, kommer agenten endast att lära sig att utföra en handling och inte upptäcka andra möjliga strategier för att tjäna belöningspoäng. Därför är det avgörande att balansera utforskning och exploatering när man skapar en förstärkningsinlärningsagent.
Användningsfall för förstärkningsinlärning
Förstärkningsinlärning kan användas i en mängd olika roller och är bäst lämpad för tillämpningar där uppgifter kräver automatisering.
Automatisering av uppgifter som ska utföras av industrirobotar är ett område där förstärkningsinlärning visar sig vara användbar. Förstärkningsinlärning kan också användas för problem som textutvinning, skapande av modeller som kan sammanfatta långa texter. Forskare experimenterar också med att använda förstärkningsinlärning inom hälso- och sjukvården, med förstärkningsagenter som hanterar uppgifter som optimering av behandlingspolicyer. Förstärkningsinlärning kan också användas för att anpassa utbildningsmaterial för studenter.
Sammanfattning av förstärkningsinlärning
Förstärkningsinlärning är en kraftfull metod för att konstruera AI-agenter som kan leda till imponerande och ibland förvånande resultat. Att träna en agent genom förstärkningsinlärning kan vara komplext och svårt, eftersom det kräver många träningsiterationer och en ömtålig balans av utforskning/exploatering-dikotomin. Men om det lyckas, kan en agent skapad med förstärkningsinlärning utföra komplexa uppgifter under en mängd olika miljöer.








