IA 101
O que é Regressão Linear?
O que é Regressão Linear?
A regressão linear é um algoritmo usado para prever, ou visualizar, uma relação entre duas características/variáveis diferentes. Em tarefas de regressão linear, existem dois tipos de variáveis sendo examinadas: a variável dependente e a variável independente. A variável independente é a variável que está por si mesma, não impactada pela outra variável. À medida que a variável independente é ajustada, os níveis da variável dependente flutuarão. A variável dependente é a variável que está sendo estudada, e é o que o modelo de regressão resolve/pretende prever. Em tarefas de regressão linear, cada observação/instância é composta por ambos os valores da variável dependente e da variável independente.
Essa foi uma explicação rápida da regressão linear, mas vamos garantir que tenhamos uma melhor compreensão da regressão linear olhando para um exemplo e examinando a fórmula que ela usa.
Entendendo Regressão Linear
Suponha que temos um conjunto de dados que cobre tamanhos de disco rígido e o custo desses discos rígidos.
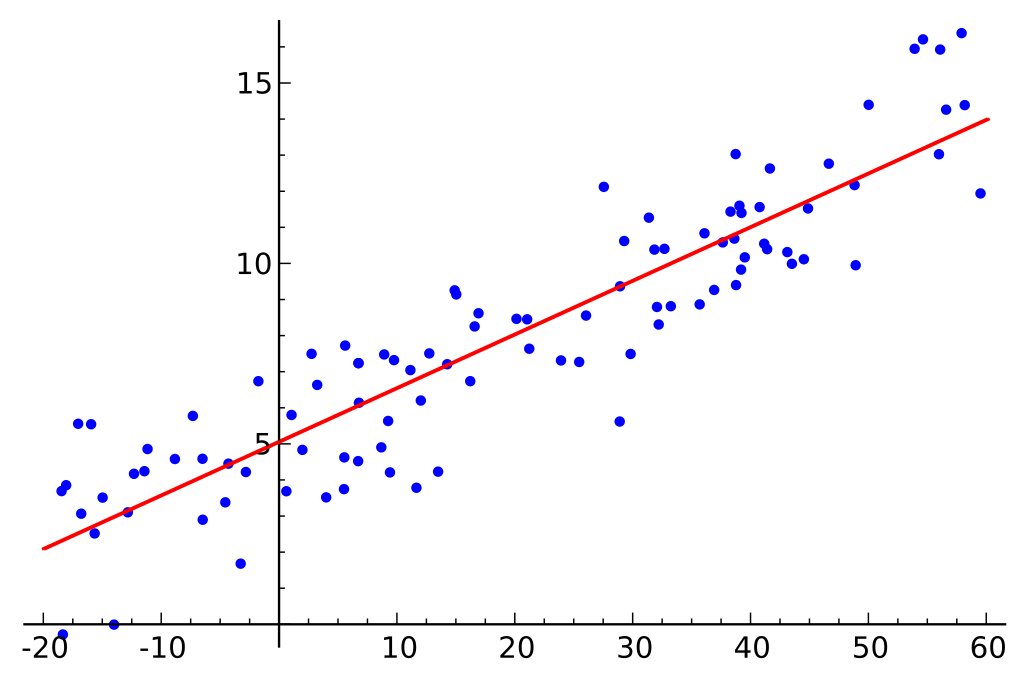
Vamos supor que o conjunto de dados que temos é composto por duas características: a quantidade de memória e o custo. Quanto mais memória compramos para um computador, mais o custo da compra aumenta. Se plotarmos os pontos de dados individuais em um gráfico de dispersão, podemos obter um gráfico que se parece com isso:

A relação exata entre a memória e o custo pode variar entre fabricantes e modelos de disco rígido, mas em geral, a tendência dos dados é uma que começa no canto inferior esquerdo (onde os discos rígidos são mais baratos e têm menor capacidade) e se move para o canto superior direito (onde os discos são mais caros e têm maior capacidade).
Se tivéssemos a quantidade de memória no eixo X e o custo no eixo Y, uma linha que captura a relação entre as variáveis X e Y começaria no canto inferior esquerdo e iria até o canto superior direito.

A função de um modelo de regressão é determinar uma função linear entre as variáveis X e Y que melhor descreva a relação entre as duas variáveis. Na regressão linear, é assumido que Y pode ser calculado a partir de alguma combinação das variáveis de entrada. A relação entre as variáveis de entrada (X) e as variáveis de destino (Y) pode ser representada desenhando uma linha através dos pontos no gráfico. A linha representa a função que melhor descreve a relação entre X e Y (por exemplo, para cada vez que X aumenta 3, Y aumenta 2). O objetivo é encontrar uma “linha de regressão” ótima, ou a linha/função que melhor se ajusta aos dados.
Linhas são tipicamente representadas pela equação: Y = m*X + b. X se refere à variável dependente, enquanto Y é a variável independente. Enquanto isso, m é a inclinação da linha, definida pelo “aumento” sobre a “corrida”. Praticantes de aprendizado de máquina representam a famosa equação da linha de inclinação de uma maneira ligeiramente diferente, usando essa equação em vez disso:
y(x) = w0 + w1 * x
Na equação acima, y é a variável de destino, enquanto “w” são os parâmetros do modelo e a entrada é “x”. Então, a equação é lida como: “A função que dá Y, dependendo de X, é igual aos parâmetros do modelo multiplicados pela característica”. Os parâmetros do modelo são ajustados durante o treinamento para obter a melhor linha de regressão.
Regressão Linear Múltipla

Foto: Cbaf via Wikimedia Commons, Domínio Público (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
O processo descrito acima se aplica à regressão linear simples, ou regressão em conjuntos de dados onde há apenas uma característica/variável independente. No entanto, uma regressão também pode ser feita com múltiplas características. No caso da “regressão linear múltipla“, a equação é estendida pelo número de variáveis encontradas no conjunto de dados. Em outras palavras, enquanto a equação para a regressão linear regular é y(x) = w0 + w1 * x, a equação para a regressão linear múltipla seria y(x) = w0 + w1x1 mais os pesos e entradas para as várias características. Se representarmos o número total de pesos e características como w(n)x(n), então poderíamos representar a fórmula como:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Depois de estabelecer a fórmula para a regressão linear, o modelo de aprendizado de máquina usará diferentes valores para os pesos, desenhando diferentes linhas de ajuste. Lembre-se de que o objetivo é encontrar a linha que melhor se ajusta aos dados para determinar qual das combinações de pesos possíveis (e, portanto, qual linha possível) melhor se ajusta aos dados e explica a relação entre as variáveis.
Uma função de custo é usada para medir quão próxima a valores Y supostos estão dos valores Y reais quando dado um valor de peso particular. A função de custo para a regressão linear é o erro médio quadrado, que simplesmente calcula a média (quadrada) do erro entre o valor previsto e o valor real para todos os pontos de dados no conjunto de dados. A função de custo é usada para calcular um custo, que captura a diferença entre o valor de destino previsto e o valor de destino real. Se a linha de ajuste estiver longe dos pontos de dados, o custo será maior, enquanto o custo se tornará menor à medida que a linha se aproxima de capturar as relações reais entre as variáveis. Os pesos do modelo são então ajustados até que a configuração de peso que produz a menor quantidade de erro seja encontrada.








