IA 101
O que é Backpropagation?
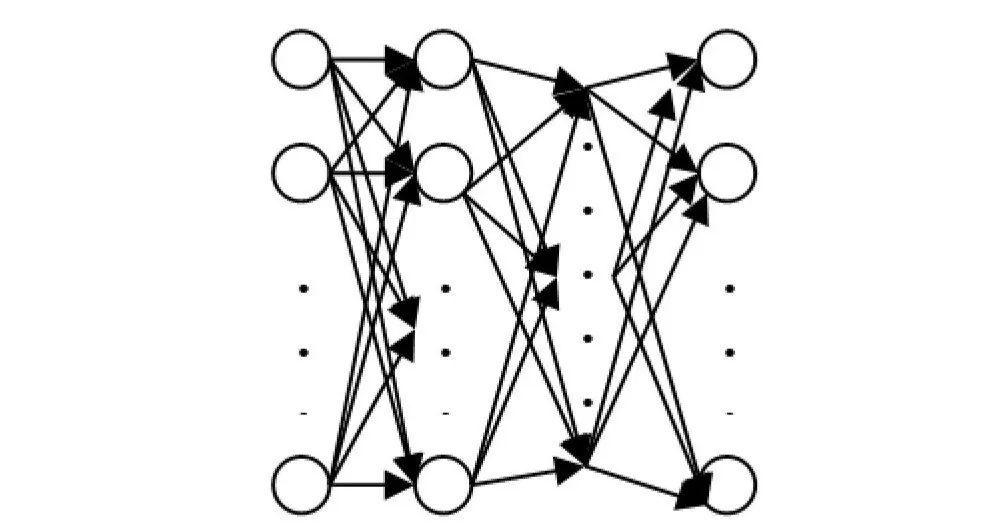
O que é Backpropagation?
Os sistemas de aprendizado profundo são capazes de aprender padrões extremamente complexos, e eles realizam isso ajustando seus pesos. Como os pesos de uma rede neural profunda são ajustados exatamente? Eles são ajustados por meio de um processo chamado backpropagation. Sem backpropagation, as redes neurais profundas não seriam capazes de realizar tarefas como reconhecer imagens e interpretar linguagem natural. Entender como a backpropagation funciona é fundamental para entender as redes neurais profundas em geral, então vamos discutir a backpropagation e ver como o processo é usado para ajustar os pesos de uma rede.
A backpropagation pode ser difícil de entender, e os cálculos usados para realizar a backpropagation podem ser bastante complexos. Este artigo tentará dar a você uma compreensão intuitiva da backpropagation, usando pouco do caminho de matemática complexa. No entanto, alguma discussão da matemática por trás da backpropagation é necessária.
O Objetivo da Backpropagation
Vamos começar definindo o objetivo da backpropagation. Os pesos de uma rede neural profunda são a força das conexões entre unidades de uma rede neural. Quando a rede neural é estabelecida, suposições são feitas sobre como as unidades em uma camada estão conectadas às camadas unidas com ela. À medida que os dados passam pela rede neural, os pesos são calculados e suposições são feitas. Quando os dados atingem a camada final da rede, uma previsão é feita sobre como as características estão relacionadas às classes no conjunto de dados. A diferença entre os valores previstos e os valores reais é a perda/erro, e o objetivo da backpropagation é reduzir a perda. Isso é realizado ajustando os pesos da rede, tornando as suposições mais semelhantes às relações verdadeiras entre as características de entrada.
Treinamento de uma Rede Neural Profunda
Antes que a backpropagation possa ser feita em uma rede neural, o treinamento regular/para frente de uma rede neural deve ser realizado. Quando uma rede neural é criada, um conjunto de pesos é inicializado. O valor dos pesos será alterado à medida que a rede for treinada. O treinamento para frente de uma rede neural pode ser concebido como três etapas discretas: ativação do neurônio, transferência do neurônio e propagação para frente.
Ao treinar uma rede neural profunda, precisamos usar várias funções matemáticas. Os neurônios em uma rede neural profunda são compostos pelos dados de entrada e uma função de ativação, que determina o valor necessário para ativar o nó. O valor de ativação de um neurônio é calculado com vários componentes, sendo uma soma ponderada das entradas. Os pesos e valores de entrada dependem do índice dos nós sendo usados para calcular a ativação. Outro número deve ser levado em conta ao calcular o valor de ativação, um valor de bias. Os valores de bias não flutuam, então não são multiplicados juntos com o peso e as entradas, apenas são adicionados. Tudo isso significa que a seguinte equação pode ser usada para calcular o valor de ativação:
Ativação = soma(peso * entrada) + bias
Depois que o neurônio é ativado, uma função de ativação é usada para determinar o que a saída real do neurônio será. Diferentes funções de ativação são ótimas para diferentes tarefas de aprendizado, mas as funções de ativação comumente usadas incluem a função sigmoide, a função Tanh e a função ReLU.
Uma vez que as saídas do neurônio sejam calculadas executando o valor de ativação pela função de ativação desejada, a propagação para frente é feita. A propagação para frente é apenas pegar as saídas de uma camada e torná-las as entradas da próxima camada. As novas entradas são então usadas para calcular as novas funções de ativação, e a saída dessa operação é passada para a camada seguinte. Esse processo continua até o final da rede neural.
Backpropagation na Rede
O processo de backpropagation recebe as decisões finais de uma passagem de treinamento de um modelo e, em seguida, determina os erros nessas decisões. Os erros são calculados contrastando as saídas/decisões da rede e as saídas/decisões desejadas da rede.
Uma vez que os erros nas decisões da rede sejam calculados, essas informações são propagadas para trás pela rede e os parâmetros da rede são alterados ao longo do caminho. O método usado para atualizar os pesos da rede é baseado no cálculo, especificamente, é baseado na regra da cadeia. No entanto, uma compreensão do cálculo não é necessária para entender a ideia por trás da backpropagation. Basta saber que, quando um valor de saída é fornecido por um neurônio, a inclinação do valor de saída é calculada com uma função de transferência, produzindo uma saída derivada. Ao fazer a backpropagation, o erro para um neurônio específico é calculado de acordo com a seguinte fórmula:
erro = (saída esperada – saída real) * inclinação do valor de saída do neurônio
Ao operar nos neurônios da camada de saída, o valor de classe é usado como o valor esperado. Depois que o erro for calculado, o erro é usado como a entrada para os neurônios da camada oculta, significando que o erro para essa camada oculta é o erro ponderado dos neurônios encontrados na camada de saída. Os cálculos de erro viajam para trás pela rede ao longo dos pesos da rede.
Depois que os erros da rede sejam calculados, os pesos da rede devem ser atualizados. Como mencionado, calcular o erro envolve determinar a inclinação do valor de saída. Depois que a inclinação for calculada, um processo conhecido como descida de gradiente pode ser usado para ajustar os pesos da rede. Um gradiente é uma inclinação, cuja inclinação pode ser medida. A inclinação é calculada plotando “y sobre” ou a “subida” sobre a “corrida”. No caso da rede neural e da taxa de erro, o “y” é o erro calculado, enquanto o “x” é os parâmetros da rede. Os parâmetros da rede têm uma relação com os valores de erro calculados, e à medida que os pesos da rede são ajustados, a taxa de erro aumenta ou diminui.
“A descida de gradiente” é o processo de atualizar os pesos para que a taxa de erro diminua. A backpropagation é usada para prever a relação entre os parâmetros da rede neural e a taxa de erro, o que configura a rede para a descida de gradiente. Treinar uma rede com descida de gradiente envolve calcular os pesos por meio da propagação para frente, propagar o erro para trás e, em seguida, atualizar os pesos da rede.








