IA 101
O que são RNNs e LSTMs em Aprendizado Profundo?
Muitos dos avanços mais impressionantes em processamento de linguagem natural e chatbots de IA são impulsionados por Redes Neurais Recorrentes (RNNs) e redes de Memória de Curto Prazo Longo (LSTM). RNNs e LSTMs são arquiteturas de redes neurais especiais que são capazes de processar dados sequenciais, dados onde a ordem cronológica é importante. LSTMs são basicamente versões aprimoradas de RNNs, capazes de interpretar sequências de dados mais longas. Vamos dar uma olhada em como RNNs e LSTMs são estruturados e como eles permitem a criação de sistemas de processamento de linguagem natural sofisticados.
O que são Redes Neurais Feed-Forward?
Então, antes de falarmos sobre como Long Short-Term Memory (LSTM) e Redes Neurais Convolucionais (CNN) funcionam, devemos discutir o formato de uma rede neural em geral.
Uma rede neural é destinada a examinar dados e aprender padrões relevantes, para que esses padrões possam ser aplicados a outros dados e novos dados possam ser classificados. Redes neurais são divididas em três seções: uma camada de entrada, uma camada oculta (ou múltiplas camadas ocultas) e uma camada de saída.
A camada de entrada é o que recebe os dados na rede neural, enquanto as camadas ocultas são o que aprendem os padrões nos dados. As camadas ocultas no conjunto de dados estão conectadas às camadas de entrada e saída por “pesos” e “viés” que são apenas suposições de como os pontos de dados estão relacionados entre si. Esses pesos são ajustados durante o treinamento. À medida que a rede treina, as suposições do modelo sobre os dados de treinamento (os valores de saída) são comparadas com as etiquetas de treinamento reais. Durante o curso do treinamento, a rede deve (esperançosamente) tornar-se mais precisa em prever relações entre pontos de dados, para que possa classificar precisamente novos pontos de dados. Redes neurais profundas são redes que têm mais camadas no meio/mais camadas ocultas. Quanto mais camadas ocultas e mais neurônios/nós o modelo tiver, melhor o modelo pode reconhecer padrões nos dados.
Redes neurais feed-forward regulares, como as que descrevi acima, são frequentemente chamadas de “redes neurais densas”. Essas redes neurais densas são combinadas com diferentes arquiteturas de rede que se especializam em interpretar diferentes tipos de dados.
O que são RNNs (Redes Neurais Recorrentes)?

Redes Neurais Recorrentes pegam o princípio geral de redes neurais feed-forward e as habilitam a lidar com dados sequenciais dando ao modelo uma memória interna. A parte “Recorrente” do nome RNN vem do fato de que a entrada e as saídas fazem um loop. Uma vez que a saída da rede é produzida, a saída é copiada e retornada à rede como entrada. Ao fazer uma decisão, não apenas a entrada e saída atuais são analisadas, mas também a entrada anterior é considerada. Para colocar de outra forma, se a entrada inicial para a rede for X e a saída for H, ambos H e X1 (a próxima entrada na sequência de dados) são alimentados na rede para a próxima rodada de aprendizado. Dessa forma, o contexto dos dados (as entradas anteriores) é preservado à medida que a rede treina.
O resultado dessa arquitetura é que RNNs são capazes de lidar com dados sequenciais. No entanto, RNNs sofrem de alguns problemas. RNNs sofrem do problema do gradiente desaparecendo e do gradiente explodindo.
O comprimento das sequências que uma RNN pode interpretar é bastante limitado, especialmente em comparação com LSTMs.
O que são LSTMs (Redes de Memória de Curto Prazo Longo)?
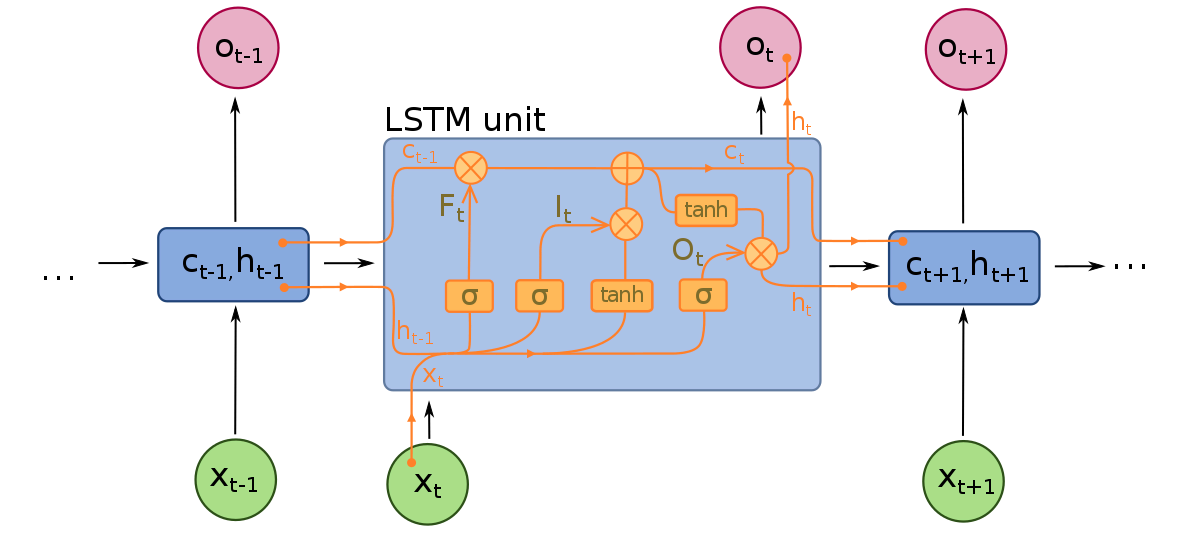
Redes de Memória de Curto Prazo Longo podem ser consideradas extensões de RNNs, aplicando mais uma vez o conceito de preservar o contexto das entradas. No entanto, LSTMs foram modificados de várias maneiras importantes que permitem que eles interpretem dados passados com métodos superiores. As alterações feitas nos LSTMs lidam com o problema do gradiente desaparecendo e permitem que LSTMs considerem sequências de entrada muito mais longas.

Modelos LSTMs são compostos por três componentes diferentes, ou portas. Há uma porta de entrada, uma porta de saída e uma porta de esquecimento. Assim como RNNs, LSTMs consideram as entradas do timestep anterior ao modificar a memória do modelo e os pesos de entrada. A porta de entrada toma decisões sobre quais valores são importantes e devem ser permitidos no modelo. Uma função sigmoide é usada na porta de entrada, que toma decisões sobre quais valores passar pela rede recorrente. Zero dropa o valor, enquanto 1 o preserva. Uma função TanH também é usada aqui, que decide quão importante para o modelo os valores de entrada são, variando de -1 a 1.
Depois que as entradas atuais e o estado de memória são considerados, a porta de saída decide quais valores enviar para o próximo timestep. Na porta de saída, os valores são analisados e atribuídos uma importância variando de -1 a 1. Isso regula os dados antes de serem passados para o próximo cálculo de timestep. Finalmente, o trabalho da porta de esquecimento é dropar informações que o modelo considera desnecessárias para tomar uma decisão sobre a natureza dos valores de entrada. A porta de esquecimento usa uma função sigmoide nos valores, produzindo números entre 0 (esqueça isso) e 1 (mantenha isso).
Uma rede neural LSTM é composta por camadas LSTM especiais que podem interpretar dados de palavras sequenciais e camadas densamente conectadas, como as descritas acima. Uma vez que os dados passam pelas camadas LSTM, eles prosseguem para as camadas densamente conectadas.








