AI 101
Co to jest Drzewo Decyzyjne?
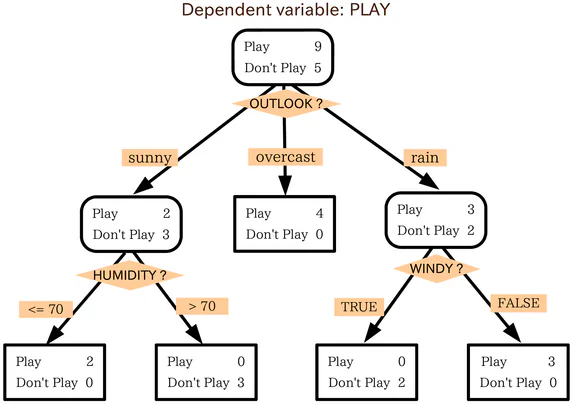
Co to jest Drzewo Decyzyjne?
Drzewo decyzyjne to przydatny algorytm machine learning używany zarówno do zadań regresji, jak i klasyfikacji. Nazwa „drzewo decyzyjne” pochodzi od faktu, że algorytm dzieli zestaw danych na mniejsze i mniejsze części, aż do momentu, gdy dane są podzielone na pojedyncze przypadki, które są następnie klasyfikowane. Jeśli można by wizualizować wyniki algorytmu, sposób, w jaki kategorie są dzielone, przypominałby drzewo i wiele liści.
To jest szybka definicja drzewa decyzyjnego, ale przejdźmy do głębszego zrozumienia, jak drzewa decyzyjne działają. Posiadanie lepszego zrozumienia, jak drzewa decyzyjne działają, a także ich przypadki użycia, pomoże wiedzieć, kiedy ich używać podczas projektów machine learning.
Format Drzewa Decyzyjnego
Drzewo decyzyjne jest bardzo podobne do diagramu przepływu. Aby użyć diagramu przepływu, zaczyna się od punktu startowego, czyli korzenia diagramu, a następnie, w zależności od odpowiedzi na kryteria filtrowania tego węzła startowego, przechodzi się do jednego z następnych możliwych węzłów. Ten proces jest powtarzany, aż do osiągnięcia końca.
Drzewa decyzyjne działają w zasadzie tak samo, przy czym każdy wewnętrzny węzeł w drzewie jest pewnego rodzaju testem/kryterium filtrowania. Węzły na zewnątrz, punkty końcowe drzewa, są etykietami dla punktu danych w question i nazywane są „liśćmi”. Gałęzie, które prowadzą od węzłów wewnętrznych do następnego węzła, są cechami lub połączeniami cech. Reguły używane do klasyfikacji punktów danych są ścieżkami, które biegną od korzenia do liści.

Algorytmy dla Drzew Decyzyjnych
Drzewa decyzyjne działają na podejściu algorytmicznym, które dzieli zestaw danych na poszczególne punkty danych na podstawie różnych kryteriów. Te podziały są wykonywane z różnymi zmiennymi, czyli różnymi cechami zestawu danych. Na przykład, jeśli celem jest określenie, czy opisany jest pies czy kot na podstawie wejściowych cech, zmiennymi, na których dzieli się dane, mogą być rzeczy takie jak „pazury” i „szczekanie”.
Co to są algorytmy używane do podziału danych na gałęzie i liście? Istnieją różne metody, które można użyć do podziału drzewa, ale najczęstszą metodą podziału jest prawdopodobnie technika zwana „rekurencyjnym podziałem binarnym”. Podczas wykonywania tej metody podziału proces zaczyna się od korzenia, a liczba cech w zestawie danych reprezentuje możliwą liczbę możliwych podziałów. Używa się funkcji, aby określić, jak dużo dokładności każdy możliwy podział będzie kosztował, a podział jest wykonywany przy użyciu kryterium, które poświęca najmniej dokładności. Ten proces jest wykonywany rekurencyjnie, a podzbiory są tworzone przy użyciu tej samej ogólnej strategii.
Aby określić koszt podziału, używa się funkcji kosztu. Inna funkcja kosztu jest używana dla zadań regresji i klasyfikacji. Celem obu funkcji kosztu jest określenie, które gałęzie mają najbardziej podobne wartości odpowiedzi, czyli najbardziej jednorodne gałęzie. Rozważ, że chcesz, aby testowe dane określonej klasy followowały określone ścieżki, co ma intuicyjny sens.
W przypadku funkcji kosztu regresji dla rekurencyjnego podziału binarnego algorytm używany do obliczania kosztu jest następujący:
sum(y – prediction)^2
Przewidywanie dla określonej grupy punktów danych jest średnią odpowiedzi treningowych dla tej grupy. Wszystkie punkty danych są przetwarzane przez funkcję kosztu, aby określić koszt wszystkich możliwych podziałów, a podział z najniższym kosztem jest wybrany.
Jeśli chodzi o funkcję kosztu dla klasyfikacji, funkcja jest następująca:
G = sum(pk * (1 – pk))
To jest wynik Gini, a jest to miara skuteczności podziału, oparta na tym, ile przypadków różnych klas jest w grupach wynikających z podziału. Innymi słowy, ilościuje, jak zmieszane są grupy po podziale. Optymalny podział jest wtedy, gdy wszystkie grupy wynikające z podziału składają się tylko z danych wejściowych z jednej klasy. Jeśli optymalny podział został utworzony, wartość „pk” będzie albo 0, albo 1, a G będzie równy zero. Można się domyślać, że najgorszy podział jest taki, w którym jest 50-50 reprezentacja klas w podziale, w przypadku klasyfikacji binarnej. W tym przypadku wartość „pk” będzie 0,5, a G również będzie 0,5.
Proces podziału jest zakończony, gdy wszystkie punkty danych zostały przekształcone w liście i sklasyfikowane. Jednak można chcieć zatrzymać wzrost drzewa wcześniej. Duże, złożone drzewa są podatne na przeuczenie, ale można użyć kilku różnych metod, aby temu przeciwdziałać. Jedną z metod redukowania przeuczenia jest określenie minimalnej liczby punktów danych, które będą używane do utworzenia liścia. Inną metodą kontroli przeuczenia jest ograniczenie drzewa do określonej maksymalnej głębokości, co kontroluje, jak długo może ciągnąć się ścieżka od korzenia do liścia.
Innym procesem zaangażowanym w tworzeniu drzew decyzyjnych jest przycinanie. Przycinanie może pomóc zwiększyć wydajność drzewa decyzyjnego, usuwając gałęzie zawierające cechy, które mają niewielką moc przewidywania / niewielkie znaczenie dla modelu. W ten sposób złożoność drzewa jest zmniejszona, staje się mniej podatne na przeuczenie, a użyteczność przewidywania modelu jest zwiększona.
Podczas przycinania proces może rozpocząć się od góry drzewa lub od dołu. Jednak najłatwiejszą metodą przycinania jest rozpoczęcie od liści i próba usunięcia węzła, który zawiera najczęstszą klasę w tym liściu. Jeśli dokładność modelu nie pogorszy się, gdy to zrobiono, zmiana jest zachowana. Istnieją inne techniki używane do przycinania, ale metoda opisana powyżej – przycinanie z redukcją błędu – jest prawdopodobnie najczęstszą metodą przycinania drzew decyzyjnych.
Zagadnienia do Rozważenia przy Używaniu Drzew Decyzyjnych
Drzewa decyzyjne są często użyteczne, gdy klasyfikacja musi być wykonana, ale czas obliczeń jest dużym ograniczeniem. Drzewa decyzyjne mogą wyjaśnić, które cechy w wybranych zestawach danych mają największą moc przewidywania. Ponadto, w przeciwieństwie do wielu algorytmów machine learning, gdzie reguły używane do klasyfikacji danych mogą być trudne do interpretacji, drzewa decyzyjne mogą dostarczyć reguły interpretowalne. Drzewa decyzyjne mogą również używać zarówno kategorialnych, jak i ciągłych zmiennych, co oznacza, że mniej przetwarzania wstępnego jest potrzebne w porównaniu z algorytmami, które mogą obsługiwać tylko jeden z tych typów zmiennych.
Drzewa decyzyjne nie radzą sobie zbyt dobrze, gdy są używane do określania wartości ciągłych atrybutów. Innym ograniczeniem drzew decyzyjnych jest to, że podczas klasyfikacji, jeśli jest niewiele przykładów treningowych, ale wiele klas, drzewo decyzyjne ma tendencję do nieścisłości.








