AI 101
Hva er Backpropagation?
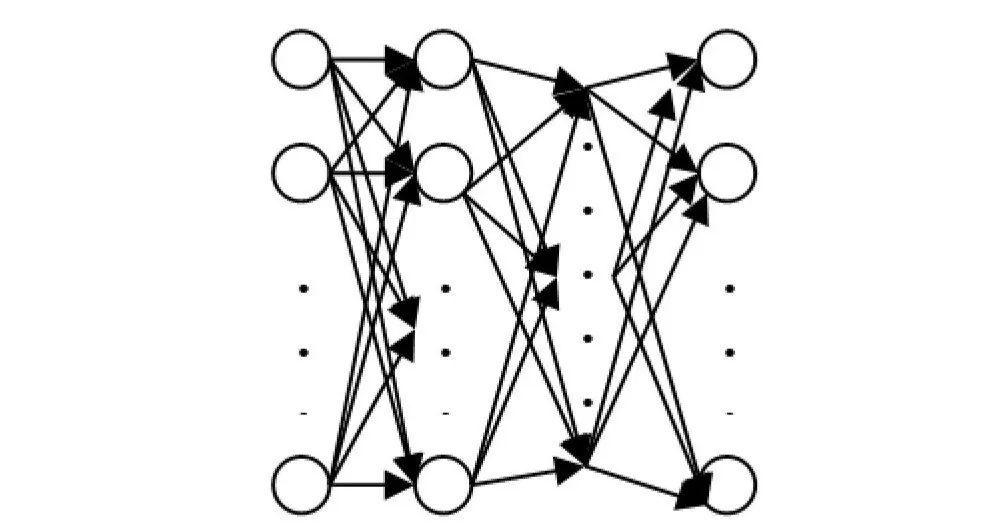
Hva er Backpropagation?
Dype læringsystemer kan lære ekstremt komplekse mønster, og de gjør dette ved å justere vektene sine. Hvordan justeres vektene i et dypt neuralt nettverk nøyaktig? De justeres gjennom en prosess som kalles backpropagation. Uten backpropagation ville dype neurale nettverk ikke kunne utføre oppgaver som å gjenkjenne bilder og tolke naturlig språk. Å forstå hvordan backpropagation fungerer er kritisk for å forstå dype neurale nettverk generelt, så la oss diskutere backpropagation og se hvordan prosessen brukes til å justere en nettverks vekter.
Backpropagation kan være vanskelig å forstå, og beregningene som brukes til å utføre backpropagation kan være ganske komplekse. Denne artikkelen vil prøve å gi deg en intuitiv forståelse av backpropagation, ved å bruke lite kompleks matematikk. Likevel er noen diskusjon om matematikken bak backpropagation nødvendig.
Målet med Backpropagation
La oss starte med å definere målet med backpropagation. Vektene i et dypt neuralt nettverk er styrken på forbindelsene mellom enhetene i et neuralt nettverk. Når det neurale nettverket etableres, gjøres antagelser om hvordan enhetene i ett lag er koblet til lagene som er koblet til det. Når dataene flyter gjennom det neurale nettverket, beregnes vektene og antagelser gjøres. Når dataene når det siste laget i nettverket, gjøres en prediksjon om hvordan egenskapene er relatert til klassene i datasettet. Forskjellen mellom de predikerte verdiene og de faktiske verdiene er tapet/feilen, og målet med backpropagation er å redusere tapet. Dette oppnås ved å justere vektene i nettverket, og gjøre antagelsene mer lik de faktiske relasjonene mellom inndata-egenskapene.
Trening av et Dypt Neuralt Nettverk
Før backpropagation kan utføres på et neuralt nettverk, må den vanlige/forover-træningspassen av et neuralt nettverk utføres. Når et neuralt nettverk opprettes, initialiseres en sett med vekter. Verdiene av vektene vil bli endret mens nettverket trenes. Den forover-træningspassen av et neuralt nettverk kan betraktes som tre separate trinn: neuron-aktivitet, neuron-overføring og forover-propagasjon.
Når du trener et dypt neuralt nettverk, må du bruke flere matematiske funksjoner. Neuroner i et dypt neuralt nettverk består av inndata og en aktiveringsfunksjon, som bestemmer verdien som er nødvendig for å aktivere noden. Aktiveringsverdien til en neuron beregnes med flere komponenter, og er en vektet sum av inndataene. Vekt- og inndata-verdiene avhenger av indeksen til nodene som brukes til å beregne aktiveringsverdien. En annen verdi må også tas i betraktning når aktiveringsverdien beregnes, en bias-verdi. Bias-verdier varierer ikke, så de multipliseres ikke sammen med vekten og inndataene, men legges bare til. Dette betyr at følgende ligning kan brukes til å beregne aktiveringsverdien:
Aktivering = sum(vekt * inndata) + bias
Etter at neuronen er aktivert, brukes en aktiveringsfunksjon til å bestemme hva utgangen av den faktiske utgangen til neuronen skal være. Forskjellige aktiveringsfunksjoner er optimale for forskjellige læringsoppgaver, men vanligvis brukte aktiveringsfunksjoner inkluderer sigmoid-funksjonen, Tanh-funksjonen og ReLU-funksjonen.
Når utgangene til neuronen er beregnet ved å kjøre aktiveringsverdien gjennom den ønskede aktiveringsfunksjonen, er forover-propagasjon gjort. Forover-propagasjon er bare å ta utgangene fra ett lag og gjøre dem til inndata for det neste laget. De nye inndataene brukes deretter til å beregne de nye aktiveringsfunksjonene, og utgangen av denne operasjonen sendes videre til det neste laget. Denne prosessen fortsetter helt til slutten av det neurale nettverket.
Backpropagation i Nettverket
Prosessenen med backpropagation tar imot de endelige beslutningene fra en modells træningspass, og deretter bestemmer den feilene i disse beslutningene. Feilene beregnes ved å kontrastere utgangene/beslutningene til nettverket og de forventede/ønskede utgangene til nettverket.
Når feilene i nettverkets beslutninger er beregnet, sendes denne informasjonen tilbake gjennom nettverket, og nettverkets parametre endres underveis. Metoden som brukes til å oppdatere vektene i nettverket er basert på kalkulus, spesifikt, det er basert på kjede-regelen. Likevel er det ikke nødvendig å ha kunnskap om kalkulus for å forstå idéen bak backpropagation. Bare vær klar over at når en utgangsverdi er gitt fra en neuron, beregnes skråningen av utgangsverdien med en overføringsfunksjon, og produserer en avledet utgang. Når backpropagation utføres, beregnes feilen for en bestemt neuron i henhold til følgende formel:
feil = (forventet_utgang – faktisk_utgang) * skråning av neuronnets utgangsverdi
Når det opereres på neuroner i utgangslaget, brukes klassen som forventet verdi. Etter at feilen er beregnet, brukes feilen som inndata for neuroner i skjulte lag, og feilen for dette skjulte laget er den vektete feilen til neuroner i utgangslaget. Feilberegningene reiser bakover gjennom nettverket langs vektene nettverket.
Etter at feilene for nettverket er beregnet, må vektene i nettverket oppdateres. Som nevnt tidligere, innebærer feilberegning å bestemme skråningen av utgangsverdien. Etter at skråningen er beregnet, kan en prosess som kalles gradient-descent brukes til å justere vektene i nettverket. En gradient er en skråning, hvis vinkel/hellning kan måles. Skråning beregnes ved å plotte “y over” eller “stigning” over “løp”. I tilfelle det neurale nettverket og feilraten, er “y” den beregnede feilen, mens “x” er nettverkets parametre. Nettverkets parametre har en relasjon til de beregnede feilverdiene, og når nettverkets vekter justeres, øker eller minker feilen.
“Gradient-descent” er prosessen med å oppdatere vektene så feilraten minker. Backpropagation brukes til å forutsi relasjonen mellom nettverkets parametre og feilraten, og setter opp nettverket for gradient-descent. Trening av et nettverk med gradient-descent innebærer å beregne vektene gjennom forover-propagasjon, backpropagere feilen og deretter oppdatere vektene i nettverket.








