Artificial Intelligence
Neural Parts: Breaking Down Primitives for Meaningful Inferred Geometry
While systems capable of generating 3D geometry from static single images have proliferated in recent years, the objects that they obtain tend to be ‘fused’ together, without any real semantic schema to reflect how the parts contribute to the whole.
There are a number of good reasons to generate hierarchical inferred models with a meaningful division of parts, including industrial analysis, medical research and imaging applications, automatic generation of geometry for video-games, simulators and VR/AR environments, and visual effects rigging, among others.
Many methods developed in recent years, such as Superquadrics shape parsing, produce less than satisfactory results, and have struggled to progress the state of the art beyond cuboid-style indicative slicing.

Segmentation by Superquadrics and other approaches provide crude or broadly representational sub-parts to an inferred image. Source: https://www.youtube.com/watch?v=6WK3B0IZJsw
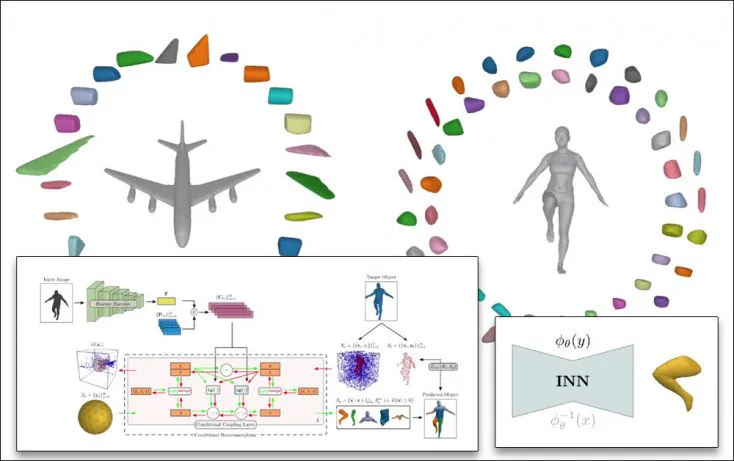
However, new research from the Max Planck Institute, entitled Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks, offers a new neural primitive 3D representation system that creates semantically useful sections.
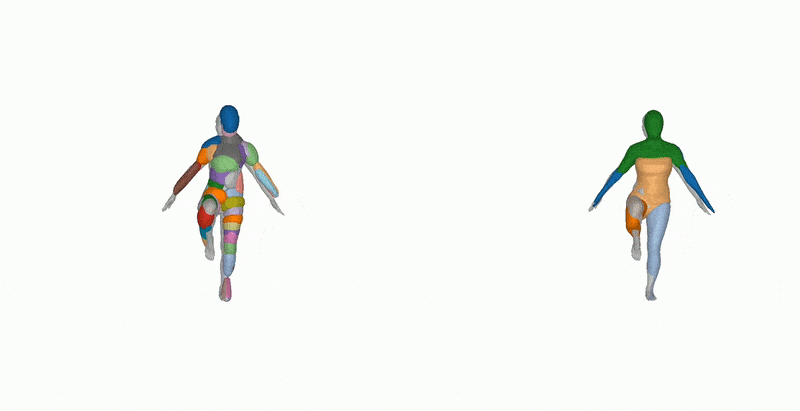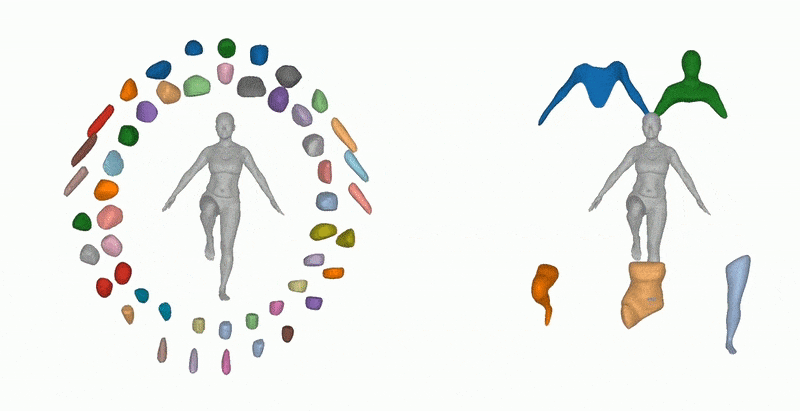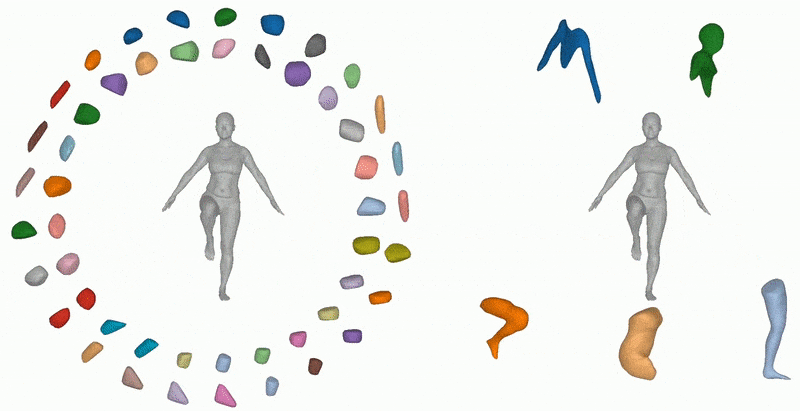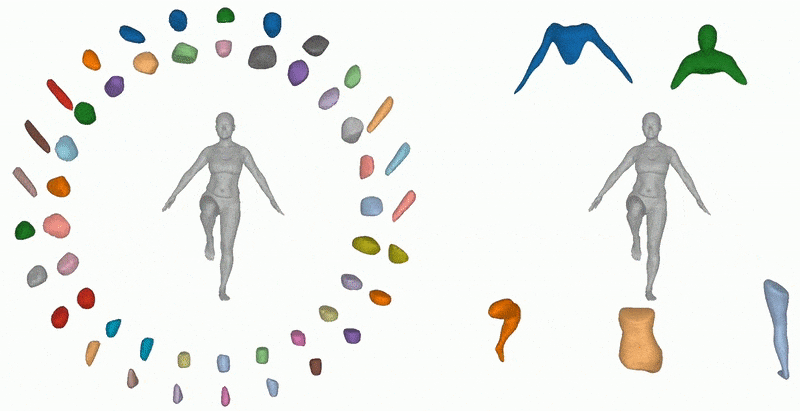
Previous methods can decompose large inferred objects, but not in a semantically useful way. On the right, the Neural Parts method creates more practical fragments. Source: https://paschalidoud.github.io/neural_parts
The segmentation is achieved via an Invertible Neural Network (INN), which uses conditional homeomorphism to deform a base geometric shape into primitives, and vice versa, calculating the topological hierarchy in both directions. In this way each primitive shape is associated with a learnable primitive embedding in order to generate the shape embedding for that primitive.

Architecture
Neural parts needs to strike a balance between reconstruction quality and primitive integrity, since complex primitives will tend the system towards complex deconstructions. Therefore the architecture of Neural Parts has been designed to straddle these conflicting considerations in an elegant manner.
The Neural Parts architecture consists of a feature extractor that maps the input of a vector, and a conditional homeomorphism component that learns homeomorphic mappings that are conditioned by the shape embedding.

The initial section of the feature extractor uses a ResNet-18 component to extract feature images. The conditional homeomorphism component uses a real-valued non-volume preserving (real NVP) transformation module.
Evaluation
The system was tested against three datasets – 2017’s Dynamic FAUST (D-FAUST), FreiHAND (2019) and Stanford University’s popular 2015 ShapeNet. D-FAUST contains 38,640 human-centered meshes, which proved suitable for the comparison, while the first 5000 hand poses in FreiHAND were used to generate meshes. For ShapeNet, the researchers followed the same category-specific training outlined by Stanford researchers in 2016.
The tests were run against primitive-based methods including superquadrics, CvxNet, and H-SQs.
Under ShapeNet, the researchers found that the Neural Parts model resulted in more accurate reconstructions than CvxNet at a level of both 5 and 25 primitives. Some of the simpler objects in the database, such as chairs, did not contain enough geometry for a meaningful deconstruction.

For FreiHAND, Neural Parts resulted in more geometrically accurate reconstructions, with better capture of fine details such as thumb position. The researchers note that by comparison, CvxNet and SQs are more focused on the general core structure, and lack these details.

For Dynamic FAUST, CvxNet and SQs were compared with the output of Neural Parts using five primitives to capture the integrity of the human body initially inferred from the data. Neural Parts was able to achieve smoother segmentation, without sacrificing the essentials of the topology.

Future Work
The researchers intend to extend Neural Parts to studies that don’t directly offer target meshes, by the use of differentiable rendering techniques. Since a base sphere is the current primitive employed in the Neural Parts framework, the researchers are also considering the use of more complex and expressive geometric primitives.












